Ein 2026 Schema.org Cheat Sheet für Google Rich Results und KI-Zitate
TL;DR: Schema.org ist nicht tot, aber der Großteil des Hypes von 2018 wird heute nicht mehr ausgespielt. Google liefert weiterhin Rich Results für Article, Product, LocalBusiness, BreadcrumbList, Organization, Review und Recipe. FAQ-Rich-Results sind seit August 2023 für normale Websites verschwunden; HowTo wurde in derselben Woche auf Mobile eingestellt. Neu in 2026 ist die KI-Schicht. Perplexity, ChatGPT Search, Claude und der Google AI Mode parsen alle JSON-LD, um ihre Zitate abzusichern. Der Job lautet nicht „jeden Schema-Typ einbauen“, sondern die vier oder fünf Typen beizubehalten, die ihre Bytes wert sind, und die Entitäten so sauber aufzubauen, dass ein LLM sie ohne Rätselraten zitieren kann.
Ein Kunde von mir zahlte Anfang 2024 eine Agentur dafür, vierzehn Schema-Typen site-weit einzubauen. FAQPage in jedem Blogpost. HowTo auf der Hälfte der Produktseiten. Service-, Course- und Event-Blöcke im Footer mit zufälligen Properties. Nichts davon erzeugte Rich Results: FAQ war bereits im August zuvor abgeschafft worden, HowTo war mobil de-deprecated, der Rest war ungültig oder nicht unterstützt. Wir löschten zwölf der vierzehn Typen, behielten Article, Product und BreadcrumbList – und das SERP-Erscheinungsbild blieb unverändert. Geändert haben sich die KI-Zitate. Mitte 2024 zog Perplexity saubere Product-Entitäten in Shopping-Anfragen, weil nur sie gültige Preise, GTIN und Marke enthielten. Schema im Jahr 2026 bedeutet weniger, jedem jemals angekündigten Rich-Result-Format hinterherzujagen, und mehr, KI-Engines ein sauberes, maschinenlesbares Rückgrat zu liefern.
Warum schema.org 2026 noch zählt (es ist nicht 2018)
Der Pitch 2018 war simpel: überall FAQ und HowTo implementieren und zusehen, wie sich die SERP-Fläche ausdehnt, weil Google die blauen Links mit Dropdowns aufblähte. 2022 waren die SERPs ein Chaos. Zwei Sites mit FAQ-Schema belegten jeweils 800 vertikale Pixel, drückten organische Treffer unter den Fold, und der FAQ-Content war meist geklaut, dupliziert oder dünn. Im August 2023 folgte Googles Deprecation – und die Wortwahl war programmatisch:
„FAQ-Rich-Results (aus FAQPage-Strukturierten Daten) werden nur noch für bekannte, autoritative Regierungs- und Gesundheitswebsites angezeigt. Für alle anderen Seiten wird dieses Rich Result nicht mehr regelmäßig ausgespielt.“ — Google Search Central, Changes to HowTo and FAQ rich results (August 2023)
Was als kleine Richtlinienänderung verkauft wurde, war in Wahrheit ein philosophischer Neustart. Google hörte auf, Schema als SERP-Dekoration zu behandeln, und begann, es als Signal zur Entitäts-Disambiguierung zu nutzen. Die sichtbare Auszahlung schrumpfte; der under-the-hood-Wert stieg, weil dasselbe JSON-LD, das früher Dropdowns speiste, nun den Knowledge Graph füttert, den AI Overviews, AI Mode und die agentische Crawling-Schicht konsumieren.
Für Betreiber macht das die Sache klarer: Hört auf, Rich-Result-Formate zu zählen. Fangt an, saubere Entitäten zu zählen. Das Schema, das ihr 2026 ausliefert, wird von mindestens vier Engines gelesen, die 2018 noch keine Rolle spielten: ChatGPT Search, Perplexity, Claude (über das Anthropic-Webtool) und Google AI Mode. Jede hat eigene Ingest-Logik, aber alle bevorzugen JSON-LD gegenüber Microdata und belohnen vollständige, valide Entitäten statt Property-Stuffing.
Welche Rich Results Google 2026 tatsächlich noch anzeigt
Die 2026-Liste ist kurz. Streicht veraltete Formate und spitze Verticals (Movie, Book, Course-Info, Dataset) – übrig bleibt eine Handvoll Typen, die sich auf den meisten kommerziellen Sites wirklich lohnen.

Article ist das Arbeitstier für Redaktion und News. Headline, datePublished, dateModified, author und publisher sind die tragenden Properties; Google liest sie für Top-Stories-Karussells, News-Boxen und die Datumszeile unter den blauen Links. Discover stützt sich stark auf das image-Attribut (mindestens 1200 px Breite).
Product ist das wertvollste Schema für E-Commerce. Offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU und aggregateRating treiben die Merchant Listings. Google hat die Anforderungen an Merchant Listings 2024 und erneut Anfang 2026 verschärft. Fehlende GTIN bei einem Markenprodukt führt nun still zur Herabstufung statt zu einer Search-Console-Warnung – das klarste Signal, dass Schema-Vollständigkeit bewertet, nicht nur validiert wird.
LocalBusiness speist das Local Pack und die Map-Karten. Name, address, telephone, openingHoursSpecification, Geo-Koordinaten und priceRange befüllen das Knowledge Panel. BreadcrumbList erscheint in der SERP als Pfad unter dem Titel und wird für die AI-Sitetopologie sauber geparst. Organization bildet das Entitäts-Rückgrat: logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, verifizierte Social-Profile), founder, foundingDate, address. KI-Engines verlassen sich darauf am stärksten, wenn sie entscheiden, welches „Acme“ gerade zitiert wird.
Review und AggregateRating werden weiterhin angezeigt, aber Google hat die Berechtigung Ende 2024 eingeschränkt. Selbstverfasste Bewertungen (Organization bewertet sich selbst, Product nur vom Verkäufer bewertet) wurden entfernt. Drittverifizierte Bewertungen erscheinen weiterhin, wenn reviewedBy.Organization oder sourceOrganization auf einen echten Rezensenten verweist.
FAQPage und HowTo sind die Deprecation-Opfer. Löscht das Markup nicht, falls es vorhanden ist (Google hat klargestellt, dass ungenutzte gültige Structured Data nicht schadet), aber plant keine Stunden mehr ein, um es für SERP-Auftritte zu pflegen.
Was KI-Engines tatsächlich aus JSON-LD parsen
Hier hat sich die Betreiberfrage zwischen 2024 und 2026 verschoben – von „Was zeigt Google?“ zu „Wie werde ich von ChatGPT zitiert?“
Jede Engine geht anders mit Structured Data um, doch das Muster ist klar: Schema dient als Grounding-Layer, eine parallele Quelle zur gerenderten Textversion, um Entitäten zu disambiguieren, Provenienz anzuhängen und Feldwerte (Preise, Daten, Ratings) zu ziehen, ohne sie erneut aus dem Fließtext zu extrahieren. Stimmen Inhalt und Schema überein, ist das Vertrauen hoch. Weichen sie ab, gilt das Schema als verdächtig und das Zitat wird herabgestuft oder wechselt die Quelle.
Aleyda Solis fasste Googles eigene Haltung beim Search Central Zürich Ende 2025 zusammen:
„Es bleibt wichtig. Insbesondere für Daten mit behördlicher Relevanz und Preisinformationen im Shopping-Bereich ist es sehr wichtig.“ — Aleyda Solis zitiert Google zu Gemini und Structured Data, Search Central Zurich 2025 recap
Die vier Engines unterscheiden sich so:
Perplexity parst JSON-LD aggressiv. Bei Shopping-Anfragen zieht es Product.offers.price und Product.brand in Antwortkarten; in redaktionellen Ergebnissen nutzt es Article.author und Article.datePublished als Byline. Fehlendes Schema bricht die Zitation nicht, aber vorhandenes liefert sauberere Cards statt einer generischen Seitenzusammenfassung.
ChatGPT Search (das OpenAI-Browse-Tool) parst Organization und Article, um Publikations-Metadaten anzuhängen. Die Zeile „vor X Minuten zitiert von Y“ basiert auf Organization.name und Article.datePublished. Toleranter gegenüber fehlendem Schema als Perplexity, aber es belohnt vollständige Organization-Entitäten.
Claude (über Anthropic Web) spielt Schema-Felder nicht direkt aus, gewichtet aber die Entitäts-Disambiguierung im Retrieval. Seiten mit sauberem Organization- plus Article-Paar gewinnen gegen schema-lose Seiten, wenn es mehrere Quellen zu einem Thema gibt.
Google AI Mode ist am schema-bewusstesten. Er liest das JSON-LD, das klassische Rich Results speist, plus Typen, die Google nie sichtbar ausgespielt hat (Service, Event, EducationalOccupationalCredential), und verwendet es zum Grounding mehrstufiger Konversationen. Hier zahlt sich tiefe Schema-Vollständigkeit am besten aus.

Das gemeinsame Signal aller vier: JSON-LD vor Microdata und RDFa – immer. Microdata validiert weiterhin und Google liest es, aber die Parser der KI-Engines sind auf JSON-LD-Blöcke im Head ausgelegt und extrahieren Inline-Microdata weniger zuverlässig. Legacy-Microdata ist nicht kaputt; neue Schema-Arbeit sollte JSON-LD nutzen.
Die Schema-Typen, die sich noch lohnen
Priorisierte Reihenfolge für eine generische kommerzielle Site 2026.
1. Organization (jede Seite, im Head-Script-Block). Logo, sameAs zu verifizierten Profilen, Founder, Adresse. Das Entitäts-Ankerglied, auf das KI-Engines setzen. Einmal einbauen und dann nicht mehr anfassen.
2. BreadcrumbList (jede Nicht-Startseite). Günstig, erscheint in den SERPs als Pfad, wird von KI für die Site-Topologie sauber geparst. Es gibt keinen Grund, es wegzulassen.
3. Article (jede Blog/News/Editorial-Seite). Headline, author (Person verschachtelt mit sameAs), datePublished, dateModified, publisher, image. Sowohl Discover als auch KI-Zitationen stützen sich darauf.
4. Product (jede Produktseite im E-Commerce). Offers mit price + priceCurrency + availability, brand, GTIN oder MPN, aggregateRating wo echt. Hier lebt die Merchant-Listing-Sichtbarkeit, und hier greift Perplexity für Produkt-Cards zu. Nutzt den SEOJuice Schema-Generator als Ausgangspunkt; Product per Hand richtig zu schreiben ist fehleranfällig, weil die Offers-Verschachtelung viele stolpern lässt.
5. LocalBusiness (jede Standortseite). Auf den passenden Subtyp spezialisieren (Restaurant, MedicalClinic, Dentist, ProfessionalService), wenn einer passt. Der generische Typ funktioniert, aber spezifizierte Varianten werden im Knowledge Panel besser ausgespielt.
6. FAQPage (nur wo wirklich sinnvoll). Kein FAQ-Schema mehr für SERP-Appearance shippen – das Schiff ist im August 2023 abgefahren. Setzt es dort ein, wo echte Fragen sauber beantwortet werden. KI-Engines nutzen es immer noch für Retrieval. Lily Ray brachte es in einem LinkedIn-Post 2024 gut auf den Punkt:
„Stellt sinnvolle FAQs bereit, wenn sie den Nutzern wirklich helfen. Spamt das aber nicht mit Long-Tail/PAA/Fan-Out-Fragen zu, wenn ihr nicht in Google Jail landen wollt.“ — Lily Ray, LinkedIn (late 2024)
7. HowTo (gleiche Einschränkung). Seit August 2023 mobil-dedeprecated, aber das Schema hilft KI-Engines immer noch bei Schritt-für-Schritt-Anfragen. Wenn eure Seite wirklich eine Anleitung ist, markiert sie. Wenn ihr stretcht, lasst es.
Alles andere (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) ist vertical-spezifisch. Implementieren, wenn es zum Geschäftsmodell passt, überspringen, wenn nicht. Jeden Typ „der Vollständigkeit halber“ zu shippen, ist die 2018-Falle.
Häufige Validierungsfehler, die euer Schema leise töten
Der Rich-Results-Test prüft die strukturelle Korrektheit (Pflichtfelder, Typen, Syntax). Er meldet aber nicht die subtileren Probleme, durch die KI-Engines euer Schema ignorieren. Führt den Validator zuerst aus und prüft dann auf Folgendes:
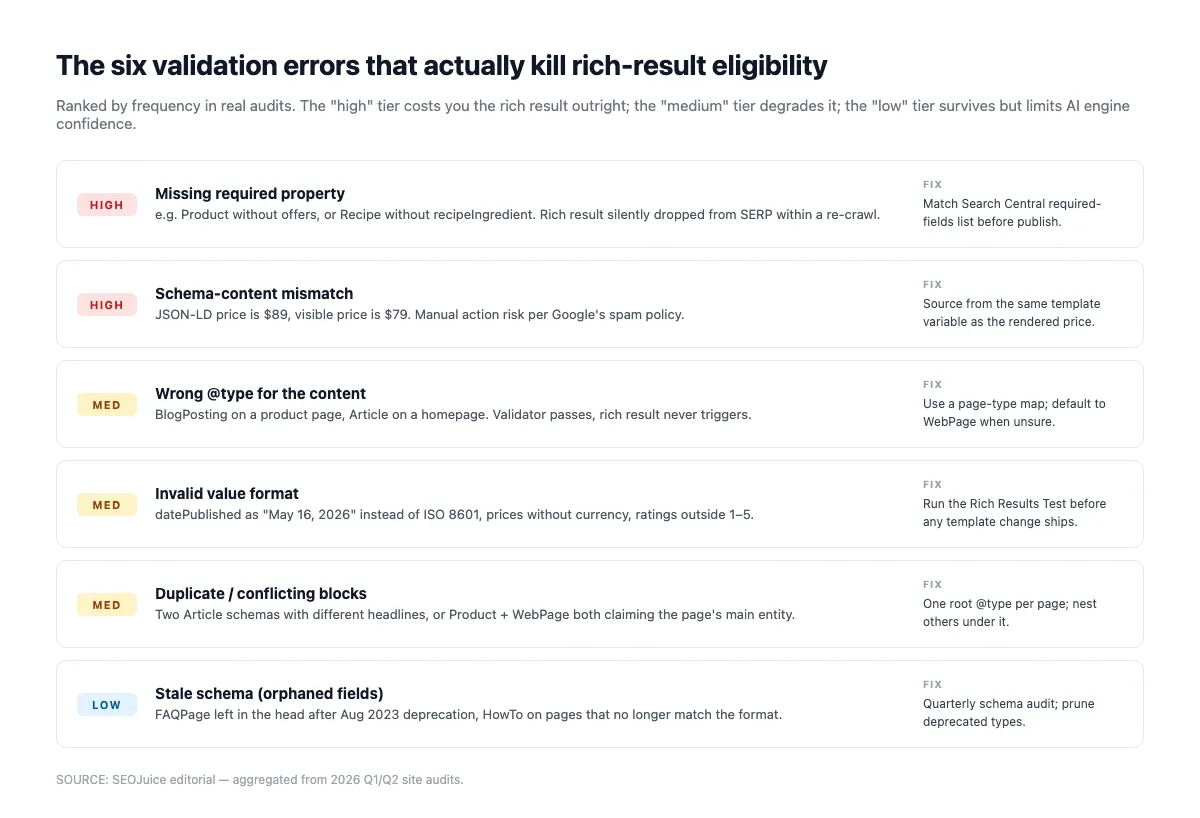
Fehlende Pflichtfelder. Der Rich-Results-Test findet sie. Article benötigt headline, datePublished, image, author, publisher. Product braucht name und offers. LocalBusiness verlangt name und address. Fehlt eins, sinkt die Rich-Result-Eligibility auf null.
Mismatch zwischen Schema und gerendertem Inhalt. Wenn Product.offers.price 49 $ sagt, die Seite aber 59 $ anzeigt, stufen sowohl Google als auch KI-Engines das Schema als verdächtig ein. KI-Engines downgraden die Zitation; Google kann eine manuelle Maßnahme wegen „irreführender Structured Data“ verhängen. Aleyda Solis warnte schon vor Jahren und die Warnung gilt weiterhin:
„Wer von diesen Richtlinien abweicht, kann das gewünschte Ergebnis verfehlen oder sogar eine manuelle Maßnahme kassieren.“ — Aleyda Solis, Search Engine Land, November 2019
Verwaiste Entitäten. Eine Organization, die nirgendwo per @id referenziert wird, ist für den Knowledge Graph unsichtbar. Verknüpft eure Entitäten. Article.publisher sollte per @id auf die site-weite Organization verweisen und sie nicht inline neu definieren.
Ungültige Datumsformate. ISO 8601 mit Zeitzone (YYYY-MM-DDTHH:MM:SS±HH:MM) ist das einzige sichere Format. „15. Januar 2026“ oder „2026-01-15“ ohne Zeitangabe wird von KI-Engines, die das Datum zur Freshness-Bewertung brauchen, still herabgestuft.
Falsches @type. Einen Blog-Index als Article (statt CollectionPage) oder ein Newsticker als BlogPosting (statt NewsArticle) zu taggen verwirrt die Klassifikation. Passt den Typ an die tatsächliche Content-Form an.
Eigeninteressierte Review/AggregateRating. Bewertungen, bei denen reviewedBy gleich itemReviewed ist (oder AggregateRating ohne glaubwürdige reviewCount + sourceOrganization) werden gefiltert. Nutzt Drittanbieter-Plattformen mit sauberem Markup oder lasst Review ganz weg.
Status-Tabelle Schema-Typ vs. Rich Result
Schnellreferenz. „Rich Result“ = sichtbare SERP-Darstellung in Google. „AI parse“ = mindestens einer von Perplexity, ChatGPT, Claude oder AI Mode konsumiert den Typ aktiv.
| Schema-Typ | Google Rich Result (2026) | AI-Parsing | Lohnt sich? |
|---|---|---|---|
| Organization | Knowledge Panel | Alle vier | Jede Site |
| Article / NewsArticle / BlogPosting | Top Stories, Discover, Datumszeile | Alle vier | Editorial-Sites |
| Product | Merchant Listings, Preis/Verfügbarkeit | Perplexity (stark), AI Mode | E-Commerce |
| BreadcrumbList | Pfadangabe in SERP | Alle vier (Topologie) | Jede Nicht-Startseite |
| LocalBusiness | Local Pack, Knowledge Panel | AI Mode, Perplexity | Lokale Sites |
| FAQPage | Nur Regierung/Gesundheit seit Aug 2023 | Alle vier (wird noch geparst) | Nur bei echten FAQs |
| HowTo | Desktop deprecated seit Aug 2023 | AI Mode, Perplexity | Nur für echte How-Tos |
| Review / AggregateRating | Sternbewertungen (Drittanbieter) | AI Mode | Nur mit echten Dritt-Reviews |
| Recipe | Vollständige Rezept-Card | Perplexity, AI Mode | Rezept-Sites |
| Event | Event-Karussell | AI Mode | Event-Sites |
| VideoObject | Video-Thumbnail | AI Mode | Wenn Video primär ist |
| Service | Keine sichtbar | AI Mode | Optional, nur AI-Grounding |
Was AI Overviews bei Schema falsch verstehen
Es lohnt sich, es klar auszusprechen, weil die Erzählung 2025 abdriftete. Die heiße These lautet „AI Overviews basieren komplett auf Schema, also füge jeden Typ hinzu“. Die Realität ist ruhiger. AI Overviews und AI Mode stützen sich auf Schema zur Entitäts-Disambiguierung und Feldextraktion, aber die Zitierentscheidung wird vor allem durch Retrieval-Qualität (beantwortet die Seite die Anfrage?) und Autoritätssignale bestimmt.
Empirische Analysen auf der Tech SEO Connect 2025 kamen zum selben Ergebnis: Structured Data ist notwendig, aber nicht hinreichend. Seiten mit sauberem Schema, aber dünnem Content werden nicht zitiert. Seiten mit starkem Content, aber ohne Schema werden zitiert, jedoch mit schlechteren Metadaten (kein sauberer Autor, kein genaues Datum, kein angezeigter Preis). Die Kombination gewinnt.
Der zweite Mythos: LLMs würden JSON-LD direkt einlesen. Die meisten tun das nicht – zumindest nicht das Modell selbst. Eine Retrieval- und Grounding-Schicht vor dem Modell parst Schema, extrahiert Felder und reicht sie als strukturierte Kontexte in den Prompt. Wenn das Modell eine Antwort generiert, ist das Schema bereits verarbeitet. Fehlgeformtes Schema bekommt kein zweites Mal die Chance – hat der Parser das Preisfeld übersehen, fehlt es dem Modell schlicht.
Also: Implementiert Schema für die Retrieval-Schicht, nicht für das Modell. Validiert aggressiv, haltet @id-Referenzen konsistent, widersteht der Versuchung, alles zu markieren, nur weil schema.org einen Typ dafür hat.
Was dieses Quartal konkret zu tun ist
Vier Schritte. Keiner davon braucht einen Dienstleister oder Relaunch.
Erstens: Auditieren, was ausgeliefert wird. Führt den Rich-Results-Test auf euren zehn Traffic-stärksten Seiten aus. Notiert, welche Typen vorhanden sind, welche validieren und welche Rich Results auslösen. Mindestens ein veralteter Typ aus der Guidance von 2018 wird auftauchen.
Zweitens: Ausmisten. Entfernt FAQPage und HowTo von Seiten, deren Inhalt nicht wirklich FAQ oder Schritt-für-Schritt ist. Entfernt Service-Blöcke ohne echtes Offer. Entfernt Review/AggregateRating, wenn der Bewerter ihr selbst seid.
Drittens: Das Entitäts-Rückgrat hinzufügen. Liefert site-weit einen Organization-JSON-LD-Block im Head mit Logo, sameAs, Founder, Adresse aus. Fügt BreadcrumbList auf jeder Nicht-Startseite hinzu. Der Schema-Markup-Generator von SEOJuice erzeugt validiertes JSON-LD zum Copy-Paste, praktisch für Organization- und Article-Blöcke in vielen Templates.
Viertens: Instrumentieren. Überwacht AI-Zitate mit einem Tool, das Perplexity, ChatGPT und AI Mode für eure Brand- und Top-Produkt-Queries abruft. Vorher-/Nachher-Daten zeigen, ob sich die Schema-Arbeit gelohnt hat.

Weiterführende Lektüre: How to get cited by ChatGPT, Perplexity, and Google AI behandelt die Marken-Zitation; optimizing for Perplexity, ChatGPT search, and Google AI Mode deckt die Content-Form ab. Dieser Artikel ist die Schema-Schiene.
Was Schema nicht für dich erledigt
Der ehrliche Abschluss: Schema ist kein Ranking-Faktor im direkten Sinn. Google ist seit 2019 klar. Product-Schema auf einer dünnen Produktseite wird sie nicht über einen Wettbewerber mit stärkerem Content ranken lassen. Article-Schema auf einem Post ohne Backlinks und ohne E-E-A-T-Signale bringt ihn nicht in die Top Stories. Schema erzeugt keine Autorität; es drückt vorhandene Autorität in maschinenlesbarer Form aus.
Was Schema liefert, ist Disambiguierung. Wenn zwei Seiten dieselbe Anfrage bedienen und eine saubere Organization- plus Article-Entität besitzt, ist sie das leichtere Zitationsziel. Wenn ein Knowledge Panel entscheidet, welches „Acme“ gesucht wird, gewinnt die Organization mit sameAs zu Wikidata. Wenn AI Mode ein mehrstufiges Shopping-Gespräch groundet, ist Product-Schema mit gültigen Offers die Quelle.
Das ist der 2026-Deal: Schema schiebt dich nicht im Ranking nach oben. Es macht dich lesbar, wenn eine KI entscheidet, wen sie zitiert, und zeigt deine strukturierten Felder sauber, wenn das Zitat erscheint. Sechs oder sieben Typen liefern diesen Vertrag für die meisten Sites. Der Rest ist vertical-abhängig, nur AI-Grounding oder ein Überbleibsel der SERP-Format-Ära, die im August 2023 endete.
FAQ
Ist Schema 2026 ein Ranking-Faktor? Nein, nicht direkt. Structured Data hilft Google beim Verstehen von Inhalten, ist aber kein generischer Ranking-Boost. Es beeinflusst Rich-Result-Eligibility und AI-Citation-Surfacing. Beides ist wichtig; keines davon ist „Ranking“ im klassischen Sinn.
Sollte ich trotz Deprecation noch FAQ-Schema einsetzen? Nur wenn der FAQ-Content wirklich nützlich ist. Das Google-Rich-Result ist für Nicht-Regierungs- und Nicht-Gesundheits-Sites weg, aber AI Mode und Perplexity parsen FAQPage-Schema weiterhin fürs Retrieval. Keine FAQs erfinden, nur um Schema-Vorteile zu erhalten; Markup einsetzen, wo echte Fragen existieren.
JSON-LD oder Microdata 2026? JSON-LD. Microdata validiert zwar noch und Google liest es, aber KI-Parser sind auf JSON-LD-Blöcke im Document-Head ausgerichtet. Neue Arbeiten sollten JSON-LD nutzen; bestehendes Microdata kann bleiben, wenn es sauber ausliefert.
Welches Schema-Minimum braucht eine SaaS- oder Service-Site? Organization (site-weit im Head), BreadcrumbList (jede Nicht-Startseite), Article (jede Blog/Editorial-Seite). Product oder LocalBusiness hinzufügen, wenn es zum Geschäftsmodell passt.
Bestraft Google über-markierte Seiten? Nicht wegen Vollständigkeit, aber sehr wohl bei irreführendem oder eigennützigem Schema. Schema, das dem sichtbaren Inhalt widerspricht, kann eine manuelle Maßnahme „misleading structured data“ auslösen. Selbstverfasste Review/AggregateRating wird still gefiltert. Die Messlatte heißt „valide und ehrlich“, nicht „minimal“.
Read More
no credit card required