Een Schema.org-cheatsheet voor 2026: Google Rich Results en AI-citaties
TL;DR: Schema.org is niet dood, maar het gros van de hype uit 2018 levert geen zichtbare resultaten meer op. Google toont nog steeds rich results voor Article, Product, LocalBusiness, BreadcrumbList, Organization, Review en Recipe. FAQ-rich-results zijn sinds augustus 2023 verdwenen voor normale sites; HowTo stierf diezelfde week op mobiel. Nieuw in 2026 is de AI-laag. Perplexity, ChatGPT-search, Claude en Google AI-modus parseren allemaal JSON-LD om hun citaties te onderbouwen. De taak is niet “elke schematype toevoegen”, maar de vier of vijf types behouden die hun bytes verdienen en je entiteiten zo schoon structureren dat een LLM die jou wil citeren niet hoeft te gokken.
In begin 2024 had ik een klant die een bureau betaalde om veertien schematypes op de site te plakken. FAQPage op elke blogpost. HowTo op de helft van de productpagina’s. Service, Course en Event-blokken in de footer met willekeurige properties. Niets leverde rich results op: FAQ was al gedeprécieerd, HowTo mobiel-gedeprécieerd en de rest was ongeldig of niet ondersteund. We verwijderden twaalf van de veertien, hielden Article, Product en BreadcrumbList, en de SERP-weergave bleef identiek. Wat wél veranderde, waren AI-citaties. Halverwege 2024 haalde Perplexity keurige Product-entiteiten in shoppingqueries naar boven omdat dat de enige met geldige prijs, GTIN en merk waren. Schema in 2026 draait minder om elke rich-result-vorm najagen die Google ooit aankondigde en meer om AI-engines een schone, machine-leesbare ruggengraat te geven.
Waarom schema.org in 2026 nog telt (het is geen 2018)
De pitch in 2018 was simpel: implementeer overal FAQ en HowTo, zie de SERP-vastgoed exploderen terwijl Google blauwe links uitklapte met dropdowns. In 2022 was de SERP een zooitje. Twee sites met FAQ-schema pakten elk 800 verticale pixels, duwden organische resultaten onder de vouw, en de FAQ-content was vaak gekopieerd of dun. Googles deprecatie in augustus 2023 volgde, en de formulering zette de toon:
“FAQ rich results (from FAQPage structured data) will be shown only for well-known, authoritative government and health websites. For all other sites, this rich result will no longer be shown regularly.” — Google Search Central, Changes to HowTo and FAQ rich results (August 2023)
Wat als klein beleidspunt werd gepresenteerd bleek een filosofische reset. Google stopte met schema als SERP-decoratie te behandelen en ziet het nu als signaal voor entiteit-ontdubbelen. De zichtbare beloning kromp; de onderhuidse waarde groeide, want dezelfde JSON-LD die dropdowns voedde, voedt nu de knowledge graph die AI Overviews, AI-modus en de agent-crawllaag consumeren.
Voor operators is de conclusie helder: stop met rich-result-formatjes tellen, begin met schone entiteiten tellen. De schema die je in 2026 uitrolt wordt gelezen door minimaal vier engines die er in 2018 niet toe deden: ChatGPT-search, Perplexity, Claude (via Anthropics webtool) en Google AI-modus. Elk heeft eigen inlaadlogica, maar ze verkiezen allemaal JSON-LD boven Microdata en belonen volledige, geldige entiteiten boven property-stuffing.
Welke rich results Google nog écht toont
De lijst voor 2026 is kort. Schrap gedeprécieerde formats en nichetypes (Movie, Book, Course-info, Dataset) en er blijft een handvol over die hun plek op de meeste commerciële sites waard zijn.

Article is het werkpaard voor redactioneel en nieuws. headline, datePublished, dateModified, author en publisher zijn de dragende properties; Google leest ze voor top-stories-carousels, news-boxen en de dateline onder blauwe links. Discover leunt op de image-property (minimaal 1200 px breed).
Product is de hoogst-renderende schema voor e-commerce. offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU en aggregateRating sturen merchant-listings aan. Google verscherpte de merchant-eisen in 2024 en opnieuw begin 2026. Een ontbrekende GTIN bij een merkproduct demotiveert nu geruisloos de listing in plaats van een console-waarschuwing te geven: het duidelijkste teken dat schema-volledigheid wordt gescoord, niet alleen gevalideerd.
LocalBusiness voedt het local pack en de map-kaart. name, address, telephone, openingHoursSpecification, geocoördinaten en priceRange vullen het knowledge panel. BreadcrumbList verschijnt in de SERP als padstring en wordt netjes geparsed voor AI-site-topologie. Organization is het entiteiten-fundament: logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, geverifieerde socials), founder, foundingDate, address. AI-engines leunen er het hardst op bij het bepalen welke “Acme” ze citeren.
Review en AggregateRating verschijnen nog, maar Google versmalde de criteria eind 2024. Zelfbeoordelingen (Organization die zichzelf reviewt, Product uitsluitend beoordeeld door de verkoper) worden gestript. Reviews van derden tonen nog wel als reviewedBy.Organization of sourceOrganization naar een echte reviewer verwijst.
FAQPage en HowTo zijn de deprecatie-slachtoffers. Verwijder de markup niet als je ’m al hebt (Google is expliciet dat ongebruikte maar geldige structured data niet schaadt), maar stop met uren budgetteren om ’m voor SERP-weergave bij te houden.
Wat AI-engines daadwerkelijk uit JSON-LD halen
Hier verschoof de operator-vraag tussen 2024 en 2026: van “wat toont Google?” naar “hoe word ik geciteerd door ChatGPT?”
Elke engine gaat anders om met structured data, maar het patroon is helder. Ze gebruiken schema als grondingslaag, een parallelle waarheid naast gerenderde tekst, om entiteiten te ontdubbelen, herkomst toe te kennen en veldwaarden (prijzen, data, ratings) op te halen zonder ze uit proza te her-extracten. Als content en schema overeenkomen is het vertrouwen hoog. Als ze verschillen, is het schema verdacht en downgrade of omzeilt de engine de citatie.
Aleyda Solis vatte Googles standpunt samen vanaf Search Central Zürich eind 2025:
“Het blijft belangrijk. Zeker voor gegevens met autoritatieve betekenis en regelgeving, zoals prijzen in shopping, is het zeer belangrijk.” — Aleyda Solis citeert Google over Gemini en structured data, Search Central Zurich 2025 recap
De vier engines splitsen zo:
Perplexity parseert JSON-LD agressief. Shopping-queries halen Product.offers.price en Product.brand in antwoordkaarten; redactionele antwoorden tonen Article.author en Article.datePublished als byline. Ontbrekende schema breekt citaties niet, maar mét schema krijg je nettere kaarten in plaats van een generieke paginasamenvatting.
ChatGPT-search (de OpenAI Browse-tool) parseert Organization en Article om publicatie-metadata toe te voegen. De regel “geciteerd X minuten geleden door Y” leunt op Organization.name en Article.datePublished. Toleranter voor ontbrekende schema dan Perplexity, maar beloont complete Organization-entiteiten.
Claude, via Anthropics webtool, toont schema-velden niet direct, maar weegt entiteit-ontdubbelen in retrieval. Pagina’s met een schone Organization + Article-set winnen van schema-loze pagina’s als er meer bronnen zijn.
Google AI-modus is het meest schema-bewust. Het leest de JSON-LD die traditionele rich results voedt plus types die Google nooit zichtbaar heeft getoond (Service, Event, EducationalOccupationalCredential) en gebruikt die in meer-turn-gesprekken. AI-modus is waar diepere schema-volledigheid het meeste oplevert.

Het gedeelde signaal: JSON-LD boven Microdata en RDFa, altijd. Microdata valideert nog en Google leest het, maar AI-parsers zijn getuned op JSON-LD-blokken in de <head> en halen minder betrouwbaar informatie uit inline Microdata. Legacy-Microdata is niet kapot; nieuw werk hoort JSON-LD te zijn.
De schematypes die nog de moeite waard zijn
Prioriteitsvolgorde voor een generieke commerciële site in 2026.
1. Organization (elke pagina, in het <head>-script). logo, sameAs naar geverifieerde profielen, founder, address. Het anker waar AI-engines op leunen. Eenmalig toevoegen en niet meer aankomen.
2. BreadcrumbList (elke niet-homepage). Goedkoop, verschijnt in SERPs als padstring, parseert helder voor AI-site-topologie. Niet verzenden heeft geen excuus.
3. Article (elke blog/nieuws/redactionele pagina). headline, author (Person met sameAs), datePublished, dateModified, publisher, image. Discover en AI-citatie oppervlakken steunen hierop.
4. Product (elke productpagina in e-commerce). offers met price + priceCurrency + availability, brand, GTIN of MPN, aggregateRating als die echt is. Hier leeft merchant-listing-zichtbaarheid, en hier haalt Perplexity zijn productkaarten vandaan. Gebruik de SEOJuice-schema-generator als start; Product handmatig goed krijgen is foutgevoelig omdat Offers-nesting mensen laat struikelen.
5. LocalBusiness (elke locatiepagina). Specialiseer naar het juiste subtype (Restaurant, MedicalClinic, Dentist, ProfessionalService) wanneer van toepassing. De generieke type werkt, maar specifieke versies scoren beter in knowledge panels.
6. FAQPage (alleen waar echt nuttig). Zet FAQ-schema niet meer in voor SERP-zichtbaarheid; dat schip is in augustus 2023 vertrokken. Gebruik het waar de vragen echt zijn en goed beantwoord. AI-engines gebruiken het nog voor retrieval. Lily Ray verwoordde het goed in een LinkedIn-post uit 2024:
“Lever betekenisvolle FAQ’s als ze werkelijk behulpzaam zijn. Maar spam dit niet vol met longtail/PAA-queries als je Google-gevangenis wilt vermijden.” — Lily Ray, LinkedIn (late 2024)
7. HowTo (zelfde kanttekening). Mobiel-gedeprécieerd sinds augustus 2023, maar de schema helpt AI-engines nog bij stap-voor-stap-vragen. Is je pagina echt een how-to? Markeer ’m. Rek je het? Sla over.
Alles daarbuiten (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) is vertical-specifiek. Implementeer als het bij je bedrijf past, sla over als dat niet zo is. Alles shippen “voor de volledigheid” is de val uit 2018.
Veelvoorkomende validatiefouten die je schema stiekem slopen
De Rich Results Test valideert structuur (verplichte velden, types, syntax). Hij vangt niet de subtielere problemen waardoor AI-engines je schema negeren. Draai eerst de validator en controleer dan op het volgende:
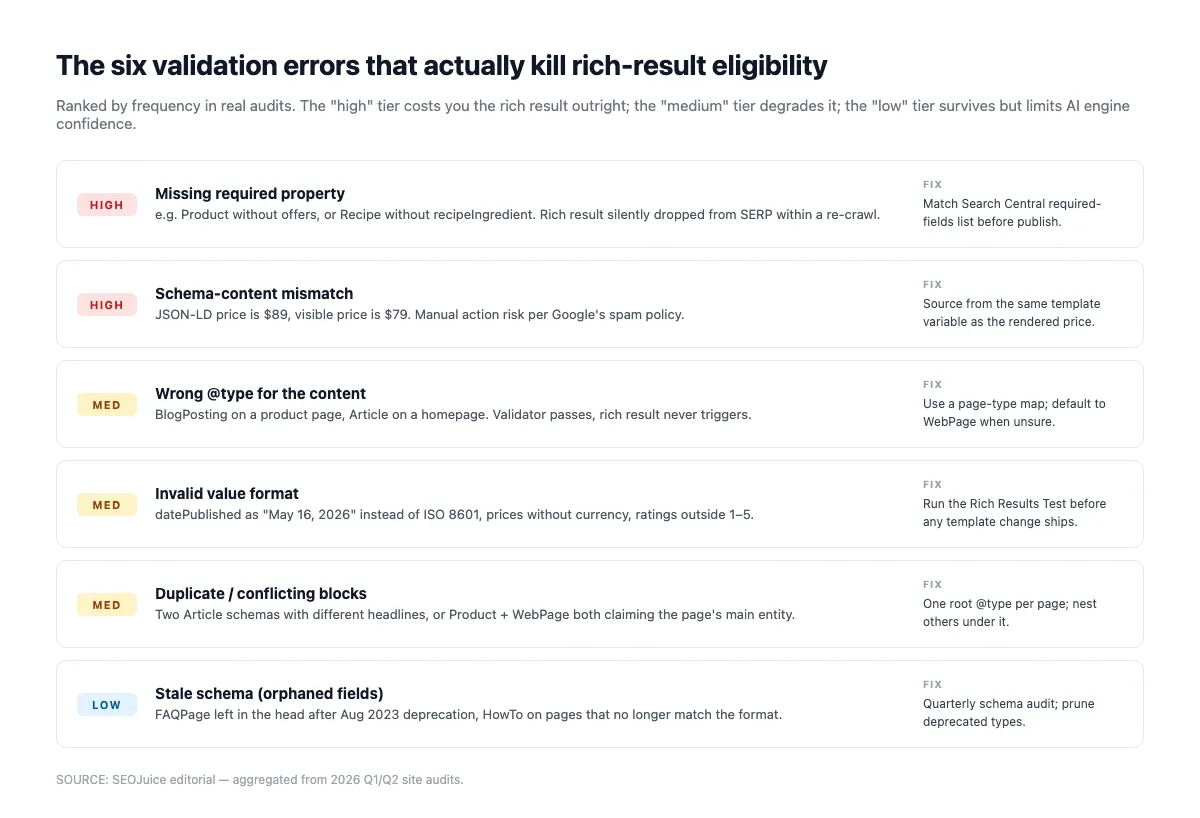
Ontbrekende verplichte properties. De Rich Results Test pikt deze op. Article heeft headline, datePublished, image, author, publisher nodig. Product vereist name en offers. LocalBusiness heeft name en address nodig. Mis er één en rich-result-kans daalt naar nul.
Mismatch schema/gerenderde content. Als Product.offers.price $49 zegt maar de zichtbare pagina $59 toont, zien Google én AI-engines het schema als verdacht. AI-engines downgraden de citatie; Google kan een “misleidende structured data”-handmatige actie geven. Aleyda Solis waarschuwde hier jaren geleden al voor en dat geldt nog steeds:
“Afwijken van deze richtlijnen kan voorkomen dat je het gewenste resultaat behaalt of zelfs een handmatige actie opleveren.” — Aleyda Solis, Search Engine Land, november 2019
Wees-entiteiten. Een Organization die nergens met @id wordt gerefereerd is onzichtbaar voor de knowledge graph. Verbind je entiteiten. Article.publisher moet met @id verwijzen naar de site-brede Organization, niet telkens opnieuw definiëren.
Ongeldige datumformaten. ISO 8601 met tijdzone (YYYY-MM-DDTHH:MM:SS±HH:MM) is de enige veilige vorm. “15 januari 2026” of “2026-01-15” zonder tijd wordt stilletjes gedegradeerd door AI-engines die de datum voor vers-score nodig hebben.
Verkeerde @type. Een blogindex taggen als Article (in plaats van CollectionPage) of een nieuwsticker als BlogPosting (in plaats van NewsArticle) verwart classificatie. Match het type met de werkelijke contentvorm.
Zelfbedienings-Review/AggregateRating. Reviews waarbij reviewedBy gelijk is aan itemReviewed (of AggregateRating zonder geloofwaardige reviewCount + sourceOrganization) worden gefilterd. Gebruik externe reviewplatforms met juiste markup of sla Review helemaal over.
Schema-type-vs-rich-result-status-tabel
Snelle referentie. “Rich result” = zichtbare SERP-behandeling in Google. “AI parse” = minimaal één van Perplexity, ChatGPT, Claude of AI-modus consumeert het type actief.
| Schema-type | Google rich result (2026) | AI parse | Implementeren? |
|---|---|---|---|
| Organization | Knowledge panel | Alle vier | Elke site |
| Article / NewsArticle / BlogPosting | Top stories, Discover, dateline | Alle vier | Redactionele sites |
| Product | Merchant-listings, prijs/beschikbaarheid | Perplexity (zwaar), AI-modus | E-commerce |
| BreadcrumbList | Padstring in SERP | Alle vier (topologie) | Elke niet-homepage |
| LocalBusiness | Local pack, knowledge panel | AI-modus, Perplexity | Lokale sites |
| FAQPage | Alleen overheid/gezondheid sinds aug 2023 | Alle vier (nog geparsed) | Alleen bij echte FAQ’s |
| HowTo | Desktop-gedeprécieerd sinds aug 2023 | AI-modus, Perplexity | Alleen bij echte how-to’s |
| Review / AggregateRating | Sterratingen (third-party only) | AI-modus | Alleen met echte derdenreviews |
| Recipe | Volledig rich card | Perplexity, AI-modus | Receptensites |
| Event | Event-carousel | AI-modus | Eventsites |
| VideoObject | Videominiatuur | AI-modus | Als video primair is |
| Service | Geen zichtbaar | AI-modus | Optioneel, alleen AI-grounding |
Wat AI Overviews mis heeft over schema
Even expliciet, omdat het narratief in 2025 afweek. De populaire hot take: “AI Overviews leunen volledig op schema, dus voeg elk type toe.” De realiteit is rustiger. AI Overviews en AI-modus gebruiken schema voor entiteit-ontdubbelen en veldextractie, maar de citatie-beslissing wordt vooral gestuurd door retrieval-kwaliteit (beantwoordt de pagina de vraag) en autoriteitssignalen.
Empirisch werk op Tech SEO Connect 2025 landt op hetzelfde punt: structured data is noodzakelijk maar niet voldoende. Pagina’s met schone schema maar dunne content worden niet geciteerd. Pagina’s met sterke content maar geen schema worden wel geciteerd, maar met afgeroomde metadata (geen nette auteur, geen precieze datum, geen prijs). De combinatie wint.
Een andere mythe: dat LLM’s JSON-LD direct scrapen. Meestal niet, althans niet via het model zelf. Een retrieval- en grounding-laag vóór het model parseert schema, haalt velden op en stopt die als gestructureerde context in de prompt. Tegen de tijd dat het model antwoord genereert, is het schema al verwerkt. Foutieve schema krijgt geen tweede kans: mist de parser het prijsveld, dan heeft het model geen fallback.
Dus: implementeer schema voor de retrieval-laag, niet het model. Valideer grondig, houd @id-referenties consistent, weersta de verleiding om alles te markeren omdat schema.org er een type voor heeft.
Wat je dit kwartaal concreet moet doen
Vier stappen. Geen vendor of rebuild nodig.
Eerst: audit wat er nu draait. Run de Rich Results Test op je tien best bezochte pagina’s. Noteer welke types aanwezig zijn, welke valideren en welke rich results opleveren. Je vindt zeker één verouderd type uit de adviezen van 2018.
Tweede: snoei. Verwijder FAQPage en HowTo van pagina’s waar de content geen echte FAQ of stappenplan is. Haal Service-blokken weg zonder echte Offer. Verwijder Review/AggregateRating waar de reviewer jijzelf bent.
Derde: voeg de entiteiten-ruggengraat toe. Plaats een site-brede Organization-JSON-LD-block in de <head> met logo, sameAs, founder, address. Zet BreadcrumbList op elke niet-homepage. De schema-markup-generator van SEOJuice levert gevalideerde JSON-LD om te plakken in de head, handig om Organization- en Article-blokken in veel templates uit te rollen.
Vierde: meet. Volg AI-citatie-weergave met een tool die Perplexity, ChatGPT en AI-modus monitort voor je merk- en topproduct-queries. Voor- en na-data vertellen of het schema-werk loonde.

Verdiepende stukken: How to get cited by ChatGPT, Perplexity, and Google AI behandelt de brand-citatiekant; optimizing for Perplexity, ChatGPT search, and Google AI Mode gaat over de content-vorm. Dit artikel is de schema-rail.
Wat schema níét voor je doet
De eerlijke afsluiter. Schema is in 2026 geen directe rankingfactor. Google zegt dat al sinds 2019. Een Product-schema op een dunne productpagina laat je niet boven een concurrent met dikkere content ranken. Article-schema op een post zonder backlinks en E-E-A-T-signalen plaatst die niet in Top Stories. Schema creëert geen autoriteit; het drukt bestaande autoriteit uit in een machineleesbaar formaat.
Wat schema wél doet, is ont-dubbeling. Wanneer twee pagina’s op dezelfde query mikken en één heeft schone Organization + Article-entiteiten, is dat de makkelijkere citatie. Wanneer een knowledge panel beslist welke “Acme” wordt bedoeld, wint de Organization met sameAs naar Wikidata. Wanneer AI-modus een meer-turn-shoppinggesprek grondt, is Product-schema met geldige Offers de bron.
Dat is het contract van 2026. Schema duwt je niet omhoog in de rankings. Het maakt je leesbaar wanneer een AI-engine beslist wie te citeren, en het toont je gestructureerde velden netjes wanneer die citatie verschijnt. Zes à zeven types leveren dat contract voor de meeste sites. De rest is branche-specifiek, AI-grounding-optioneel of een overblijfsel uit een SERP-format-tijdperk dat in augustus 2023 eindigde.
FAQ
Is schema een rankingfactor in 2026? Nee, niet direct. Structured data helpt Google content te begrijpen maar is geen algemene ranking-boost. Het beïnvloedt wel rich-result-eligibility en AI-citatie-weergave. Beide tellen; geen van beide is “ranking” in klassieke zin.
Moet ik nog FAQ-schema implementeren nu Google het rich result heeft gedeprécieerd? Alleen wanneer de FAQ-content echt nuttig is. Het Google-rich-result is weg voor niet-overheids- en niet-gezondheidssites, maar AI-modus en Perplexity parseren FAQPage nog voor retrieval. Maak geen FAQ’s alleen voor de schema; gebruik de markup waar de vragen reëel zijn.
JSON-LD of Microdata in 2026? JSON-LD. Microdata valideert nog en Google leest het, maar AI-parsers zijn afgestemd op JSON-LD-blokken in de head. Nieuw werk = JSON-LD; legacy-Microdata kan blijven als het schoon draait.
Wat is het minimale schema-set voor een SaaS- of servicesite? Organization (site-breed in head), BreadcrumbList (elke niet-homepage), Article (elke blog/redactionele pagina). Voeg Product of LocalBusiness toe als dat past bij je offering.
Penaliseert Google over-markup? Niet voor volledigheid, wel voor misleidende of zelfdienende schema. Schema die gerenderde content tegenspreekt kan een “misleading structured data”-handmatige actie krijgen. Zelfstaande Review/AggregateRating wordt stilletjes gefilterd. De lat is “geldig en eerlijk,” niet “zo minimaal mogelijk.”
Read More
- Knowledge-Based Trust SEO: een feitelijk auditmodel, geen rankingtruc
- Domain Authority-gids
- Nofollow versus Dofollow: waarom de oude tweedeling niet meer werkt
- Interne linking automatiseren op een site van 50 pagina’s zonder je topical map te verstoren
- SEO-statistieken 2026: Wat we hebben geleerd door het web te crawlen
- Je hebt je website live gezet en hij staat nog niet op Google. Dit is waarom.
no credit card required
No related articles found.