A 2026 Schema.org Cheatsheet for Google Rich Results and AI Citations
TL;DR: Schema.org isn't dead, but most of the 2018 hype isn't shipping anymore. Google still produces rich results for Article, Product, LocalBusiness, BreadcrumbList, Organization, Review, and Recipe. FAQ rich results have been gone for normal sites since August 2023; HowTo died on mobile that same week. What's new in 2026 is the AI layer. Perplexity, ChatGPT search, Claude, and Google AI Mode all parse JSON-LD to ground their citations. The job isn't "add every schema type." It's keeping the four or five that earn their bytes and structuring your entities cleanly enough that an LLM trying to cite you doesn't have to guess.
I had a client in early 2024 who paid an agency to add fourteen schema types across their site. FAQPage on every blog post. HowTo on half the product pages. Service, Course, and Event blocks in the footer with random properties. None of it produced rich results: FAQ had been deprecated the prior August, HowTo was mobile-deprecated, and the rest were invalid or unsupported. We deleted twelve of the fourteen, kept Article, Product, and BreadcrumbList, and SERP appearance was unchanged. What changed was AI citations. By mid-2024 Perplexity was pulling clean Product entities into shopping queries because they were the only ones with valid prices, GTIN, and brand. Schema in 2026 is less about chasing every rich-result format Google ever announced and more about giving AI engines a clean machine-readable backbone.
Why schema.org still matters in 2026 (it's not 2018)
The 2018 pitch was easy: implement FAQ and HowTo everywhere, watch SERP real estate balloon as Google expanded blue links with dropdowns. By 2022 the SERPs were a mess. Two sites with FAQ schema would each take 800 vertical pixels, push organic results below the fold, and the FAQ content was usually scraped, duplicated, or thin. Google's August 2023 deprecation followed, and the wording set the tone:
"FAQ rich results (from FAQPage structured data) will be shown only for well-known, authoritative government and health websites. For all other sites, this rich result will no longer be shown regularly." — Google Search Central, Changes to HowTo and FAQ rich results (August 2023)
What was framed as a small policy update was a philosophical reset. Google stopped treating schema as SERP decoration and started treating it as an entity-disambiguation signal. The visible payoff shrank; the under-the-hood value grew, because the same JSON-LD that used to power dropdowns now feeds the knowledge graph that AI Overviews, AI Mode, and the agentic crawling layer all consume.
For operators the takeaway is clarifying. Stop counting rich-result formats. Start counting clean entities. The schema you ship in 2026 is read by at least four engines that didn't matter in 2018: ChatGPT search, Perplexity, Claude (via Anthropic's web tool), and Google AI Mode. Each has its own ingestion logic, but all favor JSON-LD over Microdata and reward complete, valid entities over property stuffing.
What rich results Google still actually shows
The 2026 list is short. Strip deprecated formats and narrow-vertical types (Movie, Book, Course-info, Dataset) and what's left is a handful of types that earn their place on most commercial sites.

Article is the workhorse for editorial and news. Headline, datePublished, dateModified, author, and publisher are the load-bearing properties; Google reads them for top-stories carousels, news boxes, and the dateline under blue links. Discover leans on the image property (1200px wide minimum).
Product is the highest-value schema for ecommerce. Offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU, and aggregateRating drive merchant listings. Google tightened merchant-listing requirements in 2024 and again in early 2026. Missing GTIN on a branded product now silently demotes the listing rather than triggering a console warning, the cleanest signal that schema completeness is being scored, not just validated.
LocalBusiness powers the local pack and map-card details. Name, address, telephone, openingHoursSpecification, geo coordinates, and priceRange feed the knowledge panel. BreadcrumbList shows in the SERP as the path string under the title and parses cleanly for AI site-topology. Organization is the entity backbone: logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, verified social profiles), founder, foundingDate, address. AI engines lean on it hardest when deciding which "Acme" they're citing.
Review and AggregateRating still appear, but Google narrowed eligibility in late 2024. Self-serving reviews (Organization reviewing itself, Product reviewed only by the seller) were stripped. Third-party-verified reviews still display when reviewedBy.Organization or sourceOrganization points to a real reviewer.
FAQPage and HowTo are the deprecation casualties. Don't delete the markup if you have it (Google has been explicit that unused valid structured data doesn't hurt), but stop budgeting hours to maintain it for SERP appearance.
What AI engines actually parse from JSON-LD
This is where the operator question shifted between 2024 and 2026, from "what does Google show?" to "what gets me cited by ChatGPT?"
Each engine handles structured data differently, but the pattern summarizes cleanly. They use schema as a grounding layer, a parallel source of truth alongside rendered text, to disambiguate entities, attach provenance, and pull field values (prices, dates, ratings) without re-extracting from prose. When content and schema agree, confidence is high. When they disagree, the schema is suspect and the citation downgrades or routes elsewhere.
Aleyda Solis summarized Google's own position from Search Central Zurich in late 2025:
"It continues to be important. In particular, for data with authoritative meaning and regulatory information, like prices in shopping, it's very important." — Aleyda Solis quoting Google on Gemini and structured data, Search Central Zurich 2025 recap
The four engines split like this:
Perplexity parses JSON-LD aggressively. Shopping queries pull Product.offers.price and Product.brand into answer cards; editorial surfaces Article.author and Article.datePublished as the citation byline. Missing schema doesn't break citations, but having it produces cleaner cards instead of a generic page summary.
ChatGPT search (the OpenAI Browse tool) parses Organization and Article to attach publication metadata. The "cited X minutes ago by Y" line leans on Organization.name and Article.datePublished. More tolerant of missing schema than Perplexity, but rewards complete Organization entities.
Claude, via Anthropic's web tool, doesn't surface schema fields directly, but its retrieval weights entity disambiguation. Pages with a clean Organization + Article pair win over schema-less pages when the topic admits multiple sources.
Google AI Mode is the most schema-aware. It reads the JSON-LD that powers traditional rich results plus types Google has never surfaced visibly (Service, Event, EducationalOccupationalCredential), grounding multi-turn conversations. AI Mode is where deeper schema completeness pays best.

The shared signal across all four. JSON-LD over Microdata and RDFa, every time. Microdata still validates and Google still reads it, but AI engines' parsers are tuned for JSON-LD blocks in the head and extract less reliably from inline Microdata. Legacy Microdata isn't broken; new schema work should be JSON-LD.
The schema types still worth implementing
Priority order for a generic commercial site in 2026.
1. Organization (every page, in the head script block). Logo, sameAs to verified profiles, founder, address. The entity anchor AI engines lean on. Add it once and stop touching it.
2. BreadcrumbList (every non-homepage page). Cheap, shows in SERPs as the path string, parses cleanly for AI site-topology. No reason to ship without it.
3. Article (every blog/news/editorial page). Headline, author (Person nested with sameAs), datePublished, dateModified, publisher, image. Discover and AI citation surfaces both lean on these.
4. Product (every product page on ecommerce). Offers with price + priceCurrency + availability, brand, GTIN or MPN, aggregateRating where genuine. Where merchant-listing visibility lives, and where Perplexity's product cards pull from. Use the SEOJuice schema generator for a starting block; getting Product right by hand is error-prone because Offers nesting trips people up.
5. LocalBusiness (every location page). Specialize to the right subtype (Restaurant, MedicalClinic, Dentist, ProfessionalService) when one fits. The generic type still works but typed versions surface better in knowledge panels.
6. FAQPage (only where genuinely useful). Don't ship FAQ schema for SERP appearance, that ship sailed in August 2023. Ship it where the questions are real and answered well. AI engines still use it for retrieval. Lily Ray framed it well in a 2024 LinkedIn post:
"Provide meaningful FAQs on your site if they are truly helpful to users. That said, maybe don't spam this with lots of longtail/PAA/fan-out queries if you want to avoid ending up in Google Jail." — Lily Ray, LinkedIn (late 2024)
7. HowTo (same caveat). Mobile-deprecated since August 2023, but the schema still helps AI engines grounding step-by-step queries. If your page genuinely is a how-to, mark it up. If you're stretching to fit, skip it.
Everything else (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) is vertical-specific. Implement when your business surface matches, skip when it doesn't. Shipping every type "for completeness" is the 2018 trap.
Common validation errors that quietly kill your schema
The Rich Results Test validates structural correctness (required fields, types, syntax). It doesn't flag the subtler problems that cause AI engines to discount your schema. Run the validator first, then audit for these:
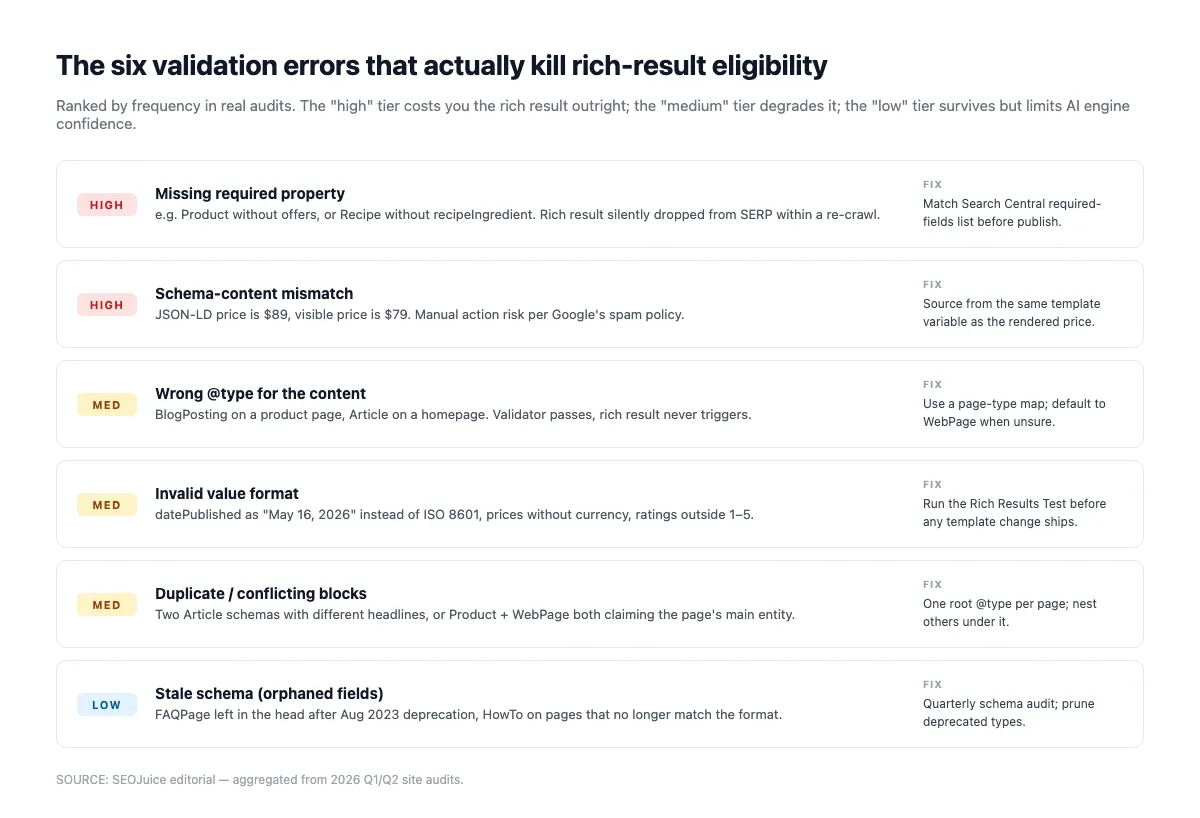
Missing required properties. The Rich Results Test catches these. Article needs headline, datePublished, image, author, publisher. Product needs name and offers. LocalBusiness needs name and address. Miss any and rich-result eligibility drops to zero.
Schema/rendered-content mismatch. If Product.offers.price says $49 but the visible page says $59, both Google and AI engines treat the schema as suspect. AI engines downgrade the citation; Google may issue a manual action for "misleading structured data." Aleyda Solis warned about this years ago and the warning still applies:
"Straying away from these guidelines may preclude you from achieving the desired result or even incur a manual action." — Aleyda Solis, Search Engine Land, November 2019
Orphan entities. An Organization that isn't @id-referenced anywhere is invisible to the knowledge graph. Wire your entities. Article.publisher should @id-reference the site-level Organization, not redefine it inline.
Invalid date formats. ISO 8601 with timezone (YYYY-MM-DDTHH:MM:SS±HH:MM) is the only safe format. "January 15, 2026" or "2026-01-15" without time data gets silently downgraded by AI engines that need the date for freshness scoring.
Wrong @type. Tagging a blog index as Article (instead of CollectionPage) or a news ticker as BlogPosting (instead of NewsArticle) confuses entity classification. Match the type to the actual content shape.
Self-serving Review/AggregateRating. Reviews where reviewedBy equals itemReviewed (or AggregateRating without credible reviewCount + sourceOrganization) get filtered. Use third-party review platforms with proper markup, or skip Review entirely.
Schema-type-vs-rich-result status table
Quick reference. "Rich result" = visible SERP treatment in Google. "AI parse" = at least one of Perplexity, ChatGPT, Claude, or AI Mode actively consumes the type.
| Schema type | Google rich result (2026) | AI parse | Worth implementing? |
|---|---|---|---|
| Organization | Knowledge panel | All four | Every site |
| Article / NewsArticle / BlogPosting | Top stories, Discover, dateline | All four | Editorial sites |
| Product | Merchant listings, price/availability | Perplexity (heavy), AI Mode | Ecommerce |
| BreadcrumbList | Path string in SERP | All four (topology) | Every non-home page |
| LocalBusiness | Local pack, knowledge panel | AI Mode, Perplexity | Local sites |
| FAQPage | Gov/health only since Aug 2023 | All four (still parsed) | Only when FAQs are real |
| HowTo | Desktop deprecated since Aug 2023 | AI Mode, Perplexity | Only for true how-tos |
| Review / AggregateRating | Star ratings (third-party only) | AI Mode | Only with real third-party reviews |
| Recipe | Full rich card | Perplexity, AI Mode | Recipe sites |
| Event | Event carousel | AI Mode | Event sites |
| VideoObject | Video thumbnail | AI Mode | When video is primary |
| Service | None visible | AI Mode | Optional, AI grounding only |
What AI Overviews get wrong about schema
Worth saying directly because the narrative drifted in 2025. The hot take is "AI Overviews lean entirely on schema, so add every type." The reality is calmer. AI Overviews and AI Mode lean on schema for entity disambiguation and field extraction, but the citation decision is driven mostly by retrieval quality (does the page answer the query) and authority signals.
Empirical work shared at Tech SEO Connect 2025 lands on the same point: structured data is necessary but not sufficient. Pages with clean schema but thin content don't get cited. Pages with great content but no schema get cited, but with degraded metadata (no clean author, no precise date, no surfaced price). The combination wins.
The other myth: that LLMs scrape JSON-LD directly. Most don't, at least not via the model itself. A retrieval and grounding layer in front of the model parses schema, extracts fields, and feeds them into the prompt as structured context. By the time the model generates an answer, the schema has been processed. Malformed schema doesn't get a do-over: if the parser missed the price field, the model has no fallback.
So: implement schema for the retrieval layer, not the model. Validate aggressively, keep @id references consistent, resist marking up everything because schema.org has a type for it.
What to actually do this quarter
Four steps. None requires a vendor or rebuild.
First, audit what's shipping. Run the Rich Results Test on your top ten pages by traffic. Note which types are present, which validate, and which trigger eligible rich results. You'll find at least one stale type from 2018-era guidance.
Second, prune. Remove FAQPage and HowTo from pages where the content isn't genuinely FAQ or step-by-step. Remove Service blocks with no real Offer attached. Remove Review/AggregateRating where the reviewer is yourself.
Third, add the entity backbone. Ship a site-wide Organization JSON-LD block in the head with logo, sameAs, founder, address. Ship BreadcrumbList on every non-home page. The schema markup generator from SEOJuice produces validated JSON-LD you can paste into the head, useful when standing up Organization and Article blocks across many templates.
Fourth, instrument. Track AI citation appearance with a tool that pulls Perplexity, ChatGPT, and AI Mode for your brand-name and top-product queries. Before-and-after data is how you know whether the schema work paid off.

Companion reads. How to get cited by ChatGPT, Perplexity, and Google AI covers the brand-citation side; optimizing for Perplexity, ChatGPT search, and Google AI Mode covers the content-shape side. This piece is the schema rail.
What schema won't do for you
The honest closer. Schema isn't a ranking factor in the direct sense. Google's been clear since 2019. Adding Product schema to a thin product page won't make it rank above a competitor with thicker content. Adding Article schema to a post with no backlinks and no E-E-A-T signals won't surface it in Top Stories. Schema doesn't manufacture authority; it expresses authority already present in a format machines can read.
What schema does is disambiguation. When two pages target the same query and one has clean Organization + Article entities, that's the easier citation target. When a knowledge panel decides which "Acme" is being searched, the Organization with sameAs to Wikidata wins. When AI Mode grounds a multi-turn shopping conversation, Product schema with valid Offers is the source.
That's the 2026 contract. Schema doesn't push you up the rankings. It makes you readable when an AI engine decides whom to cite, and surfaces your structured fields cleanly when that citation appears. Six or seven types ship that contract for most sites. The rest are vertical optional, AI-grounding optional, or holdovers from a SERP-format era that ended in August 2023.
FAQ
Is schema a ranking factor in 2026? No, not directly. Structured data helps Google understand content but isn't a generic ranking boost. What it does affect is rich-result eligibility and AI-citation surfacing. Both matter; neither is "ranking" in the classical sense.
Should I still implement FAQ schema even though Google deprecated the rich result? Only when the FAQ content is genuinely useful. The Google rich result is gone for non-government, non-health sites, but AI Mode and Perplexity still parse FAQPage schema for retrieval. Don't manufacture FAQs for the schema benefit; ship the markup where the FAQs are real.
JSON-LD or Microdata in 2026? JSON-LD. Microdata still validates and Google reads it, but AI parsers are tuned for JSON-LD blocks in the document head. New work should be JSON-LD; legacy Microdata can stay if it's already shipping cleanly.
What's the minimum schema set for a SaaS or service site? Organization (site-wide head), BreadcrumbList (every non-home page), Article (every blog/editorial page). Add Product or LocalBusiness if your business surface fits.
Does Google penalize over-marked-up pages? Not for completeness, but yes for misleading or self-serving schema. Schema that contradicts rendered content can trigger a "misleading structured data" manual action. Self-serving Review/AggregateRating gets silently filtered. The bar is "valid and honest," not "minimal."
Read More
no credit card required