Un cheatsheet Schema.org 2026 per i Rich Results di Google e le citazioni AI
In sintesi: Schema.org non è morto, ma gran parte dell’hype del 2018 non è più in produzione. Google continua a generare rich result per Article, Product, LocalBusiness, BreadcrumbList, Organization, Review e Recipe. I rich result di tipo FAQ sono spariti per i siti normali da agosto 2023; HowTo è morto su mobile quella stessa settimana. La novità del 2026 è il layer AI. Perplexity, la ricerca di ChatGPT, Claude e Google AI Mode analizzano tutti il JSON-LD per ancorare le citazioni. Il compito non è “aggiungere ogni tipo di schema”, ma mantenere i quattro o cinque che valgono i loro byte e strutturare le entità in modo così pulito che un LLM non debba indovinare nulla quando vuole citarti.
All’inizio del 2024 un mio cliente ha pagato un’agenzia per inserire quattordici tipi di schema in tutto il sito: FAQPage su ogni post, HowTo su metà delle schede prodotto, Service, Course ed Event nel footer con proprietà a caso. Nessuno di questi ha prodotto rich result: FAQ era stato deprecato ad agosto, HowTo era deprecato su mobile, il resto era invalido o non supportato. Ne abbiamo eliminati dodici, tenuto Article, Product e BreadcrumbList e l’aspetto in SERP è rimasto identico. Ciò che è cambiato sono state le citazioni AI. A metà 2024 Perplexity inseriva entità Product pulite nelle query di shopping perché erano le uniche con prezzo, GTIN e brand validi. Nel 2026 lo schema serve meno per inseguire ogni formato di rich result annunciato da Google e più per dare ai motori AI un backbone leggibile dalle macchine.
Perché schema.org conta ancora nel 2026 (non è il 2018)
Nel 2018 il pitch era semplice: implementa FAQ e HowTo ovunque e guarda l’area in SERP gonfiarsi mentre Google espandeva i link blu con i dropdown. Entro il 2022 le SERP erano un disastro: due siti con schema FAQ occupavano 800 pixel verticali ciascuno, spingendo i risultati organici sotto la piega, con contenuti spesso copiati o sottili. È seguita la deprecazione di agosto 2023 e il testo ne ha chiarito il motivo:
"I rich result FAQ (da FAQPage structured data) verranno mostrati solo per siti governativi e sanitari autorevoli. Per tutti gli altri siti, questo rich result non verrà più mostrato regolarmente." — Google Search Central, Changes to HowTo and FAQ rich results (August 2023)
Ciò che sembrava un piccolo aggiornamento di policy è stato in realtà un reset filosofico. Google ha smesso di trattare lo schema come decorazione di SERP e ha iniziato a usarlo come segnale di disambiguazione delle entità. Il payoff visibile si è ridotto; il valore sottotraccia è cresciuto, perché lo stesso JSON-LD che alimentava i dropdown ora nutre il knowledge graph consumato da AI Overviews, AI Mode e dal layer di crawling agentico.
Per gli operatori il takeaway è chiaro: smettete di contare i formati di rich result, iniziate a contare le entità pulite. Lo schema che spedite nel 2026 è letto da almeno quattro engine che nel 2018 non esistevano: ricerca ChatGPT, Perplexity, Claude (via lo strumento web di Anthropic) e Google AI Mode. Ognuno ha la propria logica di ingestione, ma tutti preferiscono JSON-LD al Microdata e premiano entità complete e valide rispetto al riempimento di proprietà.
Quali rich result Google mostra ancora davvero
La lista 2026 è corta. Eliminati i formati deprecati e i tipi verticali ristretti (Movie, Book, Course-info, Dataset), restano pochi tipi che meritano posto sulla maggior parte dei siti commerciali.

Article è il mulo da soma per editoria e news. Headline, datePublished, dateModified, author e publisher sono le proprietà portanti; Google le usa per i caroselli Top stories, i box news e la dateline sotto i link blu. Discover si appoggia a image (larghezza minima 1200 px).
Product è lo schema a maggior valore per l’e-commerce. Offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU e aggregateRating alimentano le merchant listing. Google ha stretto i requisiti nel 2024 e di nuovo a inizio 2026. Un GTIN mancante su un prodotto di marca ora declassa silenziosamente la scheda invece di mostrare un warning in console: segnale che la completezza viene valutata, non solo validata.
LocalBusiness alimenta il local pack e i dettagli della scheda mappa. Name, address, telephone, openingHoursSpecification, coordinate geo e priceRange riempiono il knowledge panel. BreadcrumbList compare in SERP come percorso sotto il titolo e si analizza bene per la topologia del sito nelle AI. Organization è lo scheletro dell’entità: logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, profili social verificati), founder, foundingDate, address. I motori AI ci si appoggiano di più quando devono decidere quale “Acme” stanno citando.
Review e AggregateRating compaiono ancora, ma Google ha ristretto l’idoneità a fine 2024. Le recensioni auto-referenziali (Organization che recensisce se stessa, Product recensito solo dal venditore) sono state rimosse. Le recensioni verificate da terze parti restano se reviewedBy.Organization o sourceOrganization punta a un reviewer reale.
FAQPage e HowTo sono le vittime della deprecazione. Non cancellate il markup se lo avete (Google è stato esplicito: structured data valido e inutilizzato non danneggia), ma smettete di dedicare ore a mantenerlo per la SERP.
Cosa gli engine AI estraggono davvero dal JSON-LD
È qui che la domanda operativa è cambiata tra 2024 e 2026, da “cosa mostra Google?” a “come mi faccio citare da ChatGPT?”.
Ogni engine gestisce i dati strutturati in modo diverso, ma il pattern è chiaro: usano lo schema come layer di grounding, una fonte di verità parallela al testo renderizzato, per disambiguare entità, agganciare la provenienza e prelevare valori (prezzi, date, rating) senza doverli riestrarre dal testo. Quando contenuto e schema concordano, la confidenza è alta. Quando discordano, lo schema diventa sospetto e la citazione viene declassata o punta altrove.
Aleyda Solis ha riassunto la posizione di Google dal Search Central di Zurigo a fine 2025:
"Continua a essere importante. In particolare, per dati con significato autoritativo e informazioni normative, come i prezzi nello shopping, è molto importante." — Aleyda Solis citando Google su Gemini e structured data, Search Central Zurich 2025 recap
I quattro engine si comportano così:
Perplexity analizza il JSON-LD in modo aggressivo. Nelle query shopping preleva Product.offers.price e Product.brand per le schede di risposta; nei contenuti editoriali mostra Article.author e Article.datePublished come byline della citazione. L’assenza di schema non blocca la citazione, ma averlo produce schede più pulite invece di un riassunto generico.
La ricerca ChatGPT (strumento Browse di OpenAI) analizza Organization e Article per aggiungere i metadati di pubblicazione. La riga “citato X minuti fa da Y” si basa su Organization.name e Article.datePublished. È più tollerante di Perplexity rispetto all’assenza di schema, ma premia entità Organization complete.
Claude, via lo strumento web di Anthropic, non mostra direttamente i campi di schema, ma pesa la disambiguazione delle entità in fase di retrieval. Le pagine con una coppia Organization + Article pulita vincono su quelle senza schema quando l’argomento ha più fonti.
Google AI Mode è il più schema-aware. Legge il JSON-LD che alimenta i rich result tradizionali più tipi mai mostrati visibilmente (Service, Event, EducationalOccupationalCredential), ancorando conversazioni multi-turno. AI Mode è dove la completezza profonda paga di più.

Il segnale comune: JSON-LD batte sempre Microdata e RDFa. Il Microdata valida ancora e Google lo legge, ma i parser degli engine AI sono ottimizzati per blocchi JSON-LD nell’head e estraggono meno in modo affidabile dal Microdata inline. Il Microdata legacy non è rotto; i nuovi lavori vanno fatti in JSON-LD.
I tipi di schema che vale ancora implementare
Ordine di priorità per un sito commerciale generico nel 2026.
1. Organization (ogni pagina, nello script dell’head). Logo, sameAs ai profili verificati, founder, address. L’ancora di entità su cui si appoggiano i motori AI. Inseriscilo una volta e non toccarlo più.
2. BreadcrumbList (ogni pagina tranne la home). Costa poco, compare in SERP come percorso, si analizza bene per la topologia del sito nelle AI. Non c’è motivo di farne a meno.
3. Article (ogni pagina blog/news/editoriale). Headline, author (Person annidato con sameAs), datePublished, dateModified, publisher, image. Discover e le superfici di citazione AI dipendono da questi campi.
4. Product (ogni scheda prodotto e-commerce). Offers con price + priceCurrency + availability, brand, GTIN o MPN, aggregateRating dove autentico. Qui vivono le merchant listing e le schede prodotto di Perplexity. Usa il generatore di schema SEOJuice come base: fare Product a mano è facile da sbagliare perché l’annidamento di Offers inganna.
5. LocalBusiness (ogni pagina di sede fisica). Specializza nel sotto-tipo corretto (Restaurant, MedicalClinic, Dentist, ProfessionalService) quando possibile. Il tipo generico funziona, ma le versioni tipizzate emergono meglio nei knowledge panel.
6. FAQPage (solo dove davvero utile). Non inserire schema FAQ per apparire in SERP: quel treno è partito ad agosto 2023. Inseriscilo dove le domande sono reali e ben risposte. I motori AI lo usano ancora per il retrieval. Lily Ray l’ha riassunto bene in un post LinkedIn del 2024:
"Fornite FAQ significative se sono davvero utili agli utenti. Detto ciò, forse non spammatelo con tante long-tail/PAA se volete evitare Google Jail." — Lily Ray, LinkedIn (fine 2024)
7. HowTo (stesso caveat). Deprecato su mobile da agosto 2023, ma lo schema aiuta ancora i motori AI a inquadrare query step-by-step. Se la pagina è davvero un how-to, marcala; se forzi la mano, salta.
Tutto il resto (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) è verticale. Implementa solo se coincide con il business; saltalo altrimenti. Spedire ogni tipo “per completezza” è la trappola del 2018.
Errori di validazione comuni che uccidono silenziosamente lo schema
Il Rich Results Test convalida la correttezza strutturale (campi richiesti, tipi, sintassi). Non segnala i problemi più sottili che fanno sì che i motori AI ignorino lo schema. Esegui prima il validator, poi controlla questi punti:
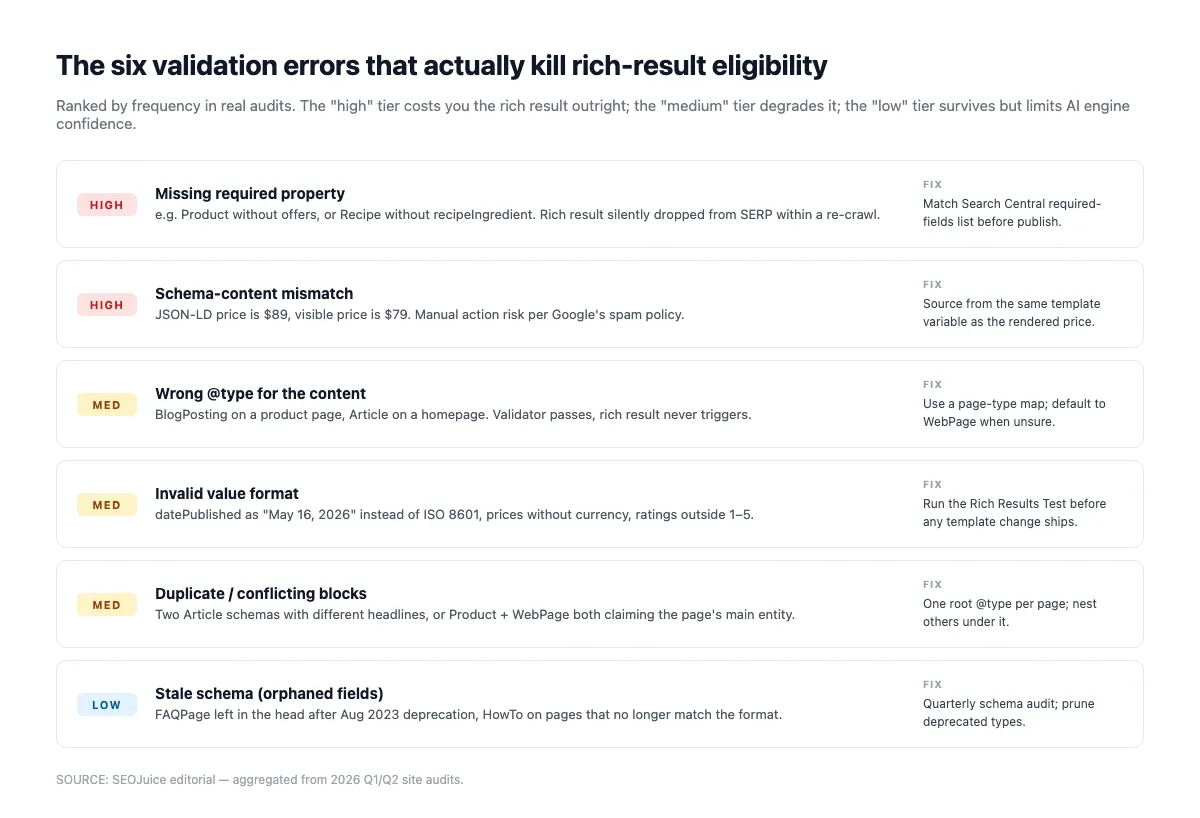
Proprietà obbligatorie mancanti. Il Rich Results Test le rileva. Article richiede headline, datePublished, image, author, publisher. Product richiede name e offers. LocalBusiness richiede name e address. Se mancano, l’idoneità al rich result scende a zero.
Mismatch schema/contenuto renderizzato. Se Product.offers.price dice 49 $ ma la pagina mostra 59 $, Google e i motori AI considerano lo schema sospetto. Le AI declassano la citazione; Google può emettere un’azione manuale per “structured data fuorviante”. Aleyda Solis lo avvertiva già anni fa e vale ancora:
"Allontanarsi da queste linee guida può impedirvi di ottenere il risultato desiderato o persino causare un’azione manuale." — Aleyda Solis, Search Engine Land, novembre 2019
Entità orfane. Un’Organization non referenziata con @id è invisibile al knowledge graph. Collegate le entità: Article.publisher dovrebbe referenziare con @id l’Organization di sito, non ridefinirla inline.
Formati data non validi. ISO 8601 con timezone (YYYY-MM-DDTHH:MM:SS±HH:MM) è l’unico sicuro. “15 gennaio 2026” o “2026-01-15” senza ora viene declassato silenziosamente dai motori AI che usano la data per il freshness scoring.
@type errato. Taggare un indice blog come Article (invece di CollectionPage) o un ticker news come BlogPosting (invece di NewsArticle) confonde la classificazione. Abbina il tipo alla forma reale del contenuto.
Review/AggregateRating auto-referenziale. Recensioni in cui reviewedBy coincide con itemReviewed (o AggregateRating senza reviewCount credibile + sourceOrganization) vengono filtrate. Usa piattaforme di recensioni terze con markup corretto o evita proprio Review.
Tabella stato schema-type vs rich result
Riferimento rapido. “Rich result” = trattamento visibile in Google. “AI parse” = almeno uno fra Perplexity, ChatGPT, Claude o AI Mode consuma il tipo.
| Schema type | Rich result Google (2026) | AI parse | Da implementare? |
|---|---|---|---|
| Organization | Knowledge panel | Tutti e quattro | Ogni sito |
| Article / NewsArticle / BlogPosting | Top stories, Discover, dateline | Tutti e quattro | Siti editoriali |
| Product | Merchant listing, prezzo/disponibilità | Perplexity (molto), AI Mode | E-commerce |
| BreadcrumbList | Stringa percorso in SERP | Tutti e quattro (topologia) | Ogni pagina non-home |
| LocalBusiness | Local pack, knowledge panel | AI Mode, Perplexity | Siti locali |
| FAQPage | Solo gov/salute dal 2023 | Tutti e quattro | Solo FAQ reali |
| HowTo | Deprecato desktop dal 2023 | AI Mode, Perplexity | Solo veri how-to |
| Review / AggregateRating | Stelle (terze parti) | AI Mode | Solo review terze parti |
| Recipe | Rich card completa | Perplexity, AI Mode | Siti di ricette |
| Event | Carosello Eventi | AI Mode | Siti eventi |
| VideoObject | Miniatura video | AI Mode | Se il video è primario |
| Service | Nessuna visibile | AI Mode | Opzionale, solo grounding AI |
Cosa gli AI Overviews sbagliano sullo schema
Vale la pena dirlo chiaro perché nel 2025 la narrazione è deragliata. Hot take: “AI Overviews si basano solo sullo schema, quindi aggiungi ogni tipo”. Realtà: AI Overviews e AI Mode si appoggiano allo schema per disambiguazione ed estrazione campi, ma la decisione di citazione è guidata soprattutto dalla qualità del retrieval (la pagina risponde alla query?) e dai segnali di autorità.
Il lavoro empirico presentato a Tech SEO Connect 2025 arriva allo stesso punto: i dati strutturati sono necessari ma non sufficienti. Pagine con schema pulito ma contenuto scarso non vengono citate. Pagine con ottimo contenuto ma senza schema vengono citate, ma con metadati degradati (niente autore pulito, data imprecisa, prezzo non mostrato). Vince la combinazione.
L’altro mito: che gli LLM raspino il JSON-LD direttamente. La maggior parte no, almeno non via modello. Un layer di retrieval e grounding davanti al modello analizza lo schema, estrae i campi e li inserisce nel prompt come contesto strutturato. Quando il modello genera la risposta, lo schema è già stato processato. Schema malformato non ottiene una seconda chance: se il parser non ha trovato il campo prezzo, il modello non ha fallback.
Quindi: implementa lo schema per il layer di retrieval, non per il modello. Valida in modo aggressivo, mantieni consistenti i riferimenti @id, resisti alla tentazione di marcare tutto solo perché schema.org ha un tipo per quello.
Cosa fare davvero questo trimestre
Quattro passi. Nessuno richiede vendor o rebuild.
Primo, fai l’audit. Esegui il Rich Results Test sulle tue dieci pagine con più traffico. Nota quali tipi sono presenti, quali convalidano e quali generano rich result. Troverai almeno un tipo obsoleto del 2018.
Secondo, pota. Rimuovi FAQPage e HowTo dalle pagine dove il contenuto non è davvero FAQ o step-by-step. Rimuovi i blocchi Service senza Offer reale. Rimuovi Review/AggregateRating dove il reviewer sei tu.
Terzo, aggiungi lo scheletro delle entità. Inserisci un blocco JSON-LD Organization site-wide nell’head con logo, sameAs, founder, address. Aggiungi BreadcrumbList su ogni pagina non-home. Il generatore di markup schema di SEOJuice produce JSON-LD validato da incollare nell’head, utile per distribuire Organization e Article su molti template.
Quarto, misura. Traccia le citazioni AI con uno strumento che monitora Perplexity, ChatGPT e AI Mode per le query sul tuo brand e sui prodotti top. Solo i dati prima/dopo ti diranno se il lavoro schema ha pagato.

Letture correlate. Come farsi citare da ChatGPT, Perplexity e Google AI tratta il lato brand-citation; ottimizzare per Perplexity, ricerca ChatGPT e Google AI Mode affronta la forma-contenuto. Questo pezzo è il binario dello schema.
Cosa lo schema non farà per te
La chiusura onesta. Lo schema non è un fattore di ranking diretto. Google lo dice dal 2019. Aggiungere Product schema a una pagina prodotto sottile non la farà salire sopra un concorrente con contenuto più ricco. Aggiungere Article schema a un post senza backlink né segnali E-E-A-T non lo farà entrare in Top Stories. Lo schema non crea autorità; esprime l’autorità già presente in un formato leggibile dalle macchine.
Ciò che fa è la disambiguazione. Quando due pagine puntano alla stessa query e una ha entità Organization + Article pulite, è il target di citazione più facile. Quando un knowledge panel decide quale “Acme” cercare, vince l’Organization con sameAs a Wikidata. Quando AI Mode sostiene una conversazione di shopping multi-turno, lo schema Product con Offers validi è la fonte.
Questo è il contratto 2026. Lo schema non ti spinge in classifica; ti rende leggibile quando un motore AI decide chi citare e mostra i tuoi campi strutturati puliti quando la citazione appare. Sei o sette tipi soddisfano questo contratto per la maggior parte dei siti. Gli altri sono opzionali verticali, opzionali AI-grounding o residui di un’era SERP finita ad agosto 2023.
FAQ
Lo schema è un fattore di ranking nel 2026? No, non direttamente. I dati strutturati aiutano Google a comprendere il contenuto ma non sono un boost di ranking generico. Influenzano però eleggibilità a rich result e comparsa nelle citazioni AI. Entrambi contano, nessuno è “ranking” in senso classico.
Dovrei implementare ancora lo schema FAQ se Google ha deprecato il rich result? Solo quando il contenuto FAQ è davvero utile. Il rich result di Google è sparito per i siti non governativi o sanitari, ma AI Mode e Perplexity analizzano ancora FAQPage per il retrieval. Non creare FAQ fasulle per lo schema; inserisci il markup dove le domande sono reali.
JSON-LD o Microdata nel 2026? JSON-LD. Il Microdata valida ancora e Google lo legge, ma i parser AI sono ottimizzati per blocchi JSON-LD nell’head. Il nuovo lavoro va in JSON-LD; il Microdata legacy resta se già pulito.
Qual è il set minimo di schema per un sito SaaS o di servizi? Organization (site-wide nell’head), BreadcrumbList (ogni pagina non-home), Article (ogni pagina blog/editoriale). Aggiungi Product o LocalBusiness se il tuo business lo richiede.
Google penalizza le pagine troppo marcate? Non per completezza, ma sì per schema fuorviante o auto-referenziale. Schema che contraddice il contenuto può generare un’azione manuale “misleading structured data”. Review/AggregateRating auto-serving viene filtrato. L’asticella è “valido e onesto”, non “minimale”.
Read More
- Ottimizzazione SEO su Airbnb per host (Guida del consulente)
- Come ottimizzare il tuo sito web per gli strumenti di IA
- SEO per i brand di bellezza: come aumentare il traffico
- Penalità SEO per i Contenuti AI: Su Cosa Google Interviene Davvero
- SEO per i founder di startup: le 5 metriche che contano davvero
- Cos’è una SERP nel 2026? Caratteristiche, IA e nuove regole
no credit card required