Guía rápida de Schema.org 2026 para Google Rich Results y citas de IA
TL;DR: Schema.org no está muerto, pero gran parte del hype de 2018 ya no se concreta. Google sigue mostrando resultados enriquecidos para Article, Product, LocalBusiness, BreadcrumbList, Organization, Review y Recipe. Los resultados enriquecidos de FAQ desaparecieron para los sitios normales en agosto de 2023; HowTo murió en móvil esa misma semana. Lo nuevo en 2026 es la capa de IA. Perplexity, la búsqueda de ChatGPT, Claude y el Modo IA de Google analizan el JSON-LD para fundamentar sus citas. El trabajo ya no es «añadir todos los tipos de schema», sino mantener los cuatro o cinco que realmente aportan valor y estructurar las entidades lo bastante limpias para que un LLM no tenga que adivinar cuando quiera citarte.
A principios de 2024 un cliente pagó a una agencia para añadir catorce tipos de schema en todo su sitio. FAQPage en cada post, HowTo en la mitad de las fichas de producto. Service, Course y Event en el pie con propiedades aleatorias. Nada generó resultados enriquecidos: FAQ estaba deprecado desde agosto, HowTo lo estaba en móvil, y el resto era inválido o no admitido. Eliminamos doce de los catorce, dejamos Article, Product y BreadcrumbList, y la apariencia en el SERP no cambió. Lo que sí cambió fueron las citas de IA. A mediados de 2024 Perplexity ya extraía entidades Product limpias en consultas de compra porque eran las únicas con precios, GTIN y marca válidos. En 2026 el schema trata menos de perseguir cada formato de rich result anunciado por Google y más de dar a los motores de IA un esqueleto legible por máquina.
Por qué schema.org sigue importando en 2026 (no es 2018)
El pitch de 2018 era sencillo: implementa FAQ y HowTo en todas partes y observa cómo tu espacio en el SERP se infla cuando Google expande los enlaces azules con desplegables. Para 2022 los resultados eran un caos. Dos sitios con schema FAQ ocupaban 800 píxeles verticales cada uno, empujaban los resultados orgánicos por debajo del fold y el contenido FAQ solía estar copiado o ser muy pobre. Google lo deprecó en agosto de 2023 y el tono quedó claro:
«Los resultados enriquecidos de FAQ (a partir de los datos estructurados FAQPage) solo se mostrarán para sitios gubernamentales y de salud bien conocidos y con autoridad. Para el resto de los sitios, este resultado enriquecido ya no se mostrará con regularidad.» — Google Search Central, Changes to HowTo and FAQ rich results (August 2023)
Lo que parecía una simple actualización de política fue en realidad un reinicio filosófico. Google dejó de tratar el schema como decoración del SERP y empezó a verlo como señal de desambiguación de entidades. El beneficio visible disminuyó; el valor interno creció, porque el mismo JSON-LD que antes alimentaba desplegables ahora nutre el knowledge graph que consumen AI Overviews, Modo IA y la capa de rastreo agente.
Para los operadores la conclusión es clara: deja de contar formatos de rich result y empieza a contar entidades limpias. El schema que publicas en 2026 lo leen al menos cuatro motores que en 2018 no importaban: la búsqueda de ChatGPT, Perplexity, Claude (vía la herramienta web de Anthropic) y el Modo IA de Google. Cada uno tiene su lógica de ingesta, pero todos prefieren JSON-LD a Microdata y premian entidades completas y válidas frente a rellenar propiedades sin sentido.
Qué resultados enriquecidos sigue mostrando Google
La lista de 2026 es corta. Si quitamos los formatos deprecados y los tipos muy de nicho (Movie, Book, Course-info, Dataset) queda un puñado que realmente merece la pena en la mayoría de sitios comerciales.

Article es el caballo de batalla para editorial y noticias. Headline, datePublished, dateModified, author y publisher son las propiedades críticas; Google las usa en el carrusel de Top Stories, los módulos de noticias y la fecha bajo los enlaces azules. Discover se apoya en la propiedad image (mínimo 1200 px de ancho).
Product es el schema de mayor valor para ecommerce. Offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU y aggregateRating impulsan los listados de comerciantes. Google endureció los requisitos en 2024 y otra vez a principios de 2026. Falta de GTIN en un producto de marca ahora degrada el listado sin aviso en Search Console: la señal más clara de que ya se puntúa la completitud, no solo la validez.
LocalBusiness alimenta el local pack y los detalles de la tarjeta de mapa. Name, address, telephone, openingHoursSpecification, geo coordinates y priceRange llenan el knowledge panel. BreadcrumbList aparece como la ruta bajo el título y se interpreta limpiamente para la topología del sitio en IA. Organization es la columna vertebral de la entidad: logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, perfiles verificados), founder, foundingDate, address. Las IA se apoyan en ella para decidir qué «Acme» están citando.
Review y AggregateRating siguen apareciendo, pero Google restringió la elegibilidad a finales de 2024. Las opiniones autogeneradas (Organization evaluándose a sí misma o Product valorado solo por el vendedor) se eliminaron. Las reviews verificadas de terceros aún se muestran cuando reviewedBy.Organization o sourceOrganization apuntan a un revisor real.
FAQPage y HowTo son las bajas de la deprecación. No elimines el marcado si ya lo tienes (Google ha dicho que los datos estructurados válidos no usados no perjudican), pero deja de invertir horas en mantenerlo para aparecer en el SERP.
Qué analizan realmente las IA en el JSON-LD
Aquí cambió la pregunta entre 2024 y 2026: de «¿qué muestra Google?» a «¿cómo consigo que ChatGPT me cite?»
Cada motor maneja los datos estructurados de forma distinta, pero el patrón es claro. Usan el schema como capa de fundamentación, una fuente paralela junto al texto renderizado, para desambiguar entidades, adjuntar procedencia y extraer valores (precios, fechas, ratings) sin re-raspar el contenido. Cuando el contenido y el schema coinciden, la confianza es alta. Cuando difieren, el schema se pone en duda y la cita se degrada o se dirige a otra parte.
Aleyda Solis resumió la postura de Google desde Search Central Zúrich a finales de 2025:
«Sigue siendo importante. En particular, para datos con significado autoritario e información regulatoria, como los precios en shopping, es muy importante.» — Aleyda Solis citando a Google sobre Gemini y datos estructurados, Search Central Zurich 2025 recap
Los cuatro motores se reparten así:
Perplexity analiza JSON-LD de forma agresiva. En compras extrae Product.offers.price y Product.brand para las tarjetas de respuesta; en editorial muestra Article.author y Article.datePublished como línea de cita. Falta de schema no rompe la cita, pero tenerlo produce tarjetas más limpias en lugar de un resumen genérico.
Búsqueda de ChatGPT (herramienta Browse de OpenAI) interpreta Organization y Article para añadir metadatos de publicación. La línea «citado hace X minutos por Y» se basa en Organization.name y Article.datePublished. Tolera mejor la ausencia de schema que Perplexity, pero premia entidades Organization completas.
Claude, mediante la herramienta web de Anthropic, no muestra campos de schema directamente, pero pondera la desambiguación de entidades en la recuperación. Páginas con un par limpio Organization + Article ganan frente a las sin schema cuando hay múltiples fuentes.
Modo IA de Google es el más consciente del schema. Lee el JSON-LD que impulsa los rich results tradicionales y tipos que Google nunca mostró (Service, Event, EducationalOccupationalCredential), fundamentando conversaciones multivuelta. Aquí es donde la completitud avanzada del schema paga mejor.

La señal común en los cuatro: JSON-LD sobre Microdata y RDFa, siempre. Microdata aún valida y Google lo lee, pero los analizadores de las IA están afinados para bloques JSON-LD en el head y extraen con menos fiabilidad del Microdata inline. El Microdata heredado no está roto; el trabajo nuevo debe ser JSON-LD.
Tipos de schema que todavía merece implementar
Orden de prioridad para un sitio comercial genérico en 2026.
1. Organization (en todas las páginas, en el bloque script del head). Logo, sameAs a perfiles verificados, founder, address. El ancla de entidad que usan las IA. Añádelo una vez y no lo toques.
2. BreadcrumbList (todas las páginas excepto la home). Barato, se muestra en el SERP como la ruta y se interpreta limpio para la topología del sitio en IA. No hay razón para no enviarlo.
3. Article (todas las páginas de blog/noticias). Headline, author (Person anidada con sameAs), datePublished, dateModified, publisher, image. Discover y las citas de IA se apoyan en ellos.
4. Product (cada ficha en ecommerce). Offers con price + priceCurrency + availability, brand, GTIN o MPN, aggregateRating genuino. Aquí vive la visibilidad en merchant listings y de aquí extrae Perplexity sus tarjetas de producto. Usa el generador de schema de SEOJuice para empezar; hacer Product a mano es propenso a errores porque Offers y sus anidamientos confunden.
5. LocalBusiness (cada página de ubicación). Especialízalo al subtipo correcto (Restaurant, MedicalClinic, Dentist, ProfessionalService) si encaja. El genérico funciona, pero los tipados se muestran mejor en el knowledge panel.
6. FAQPage (solo donde sea realmente útil). No uses schema de FAQ para aparecer en el SERP; ese tren pasó en agosto de 2023. Úsalo cuando las preguntas sean reales y estén bien respondidas. Las IA lo siguen usando para recuperación. Lily Ray lo resumió bien en LinkedIn (2024):
«Incluye FAQs significativas si realmente ayudan al usuario. Dicho esto, quizá no abuses con queries long-tail/PAA si no quieres acabar en la cárcel de Google.» — Lily Ray, LinkedIn (finales de 2024)
7. HowTo (mismo matiz). Deprecado en móvil desde agosto de 2023, pero el schema aún ayuda a las IA en consultas paso a paso. Si tu página es realmente un how-to, márcala. Si fuerzas la etiqueta, sáltala.
Todo lo demás (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) es vertical. Implémentalo si tu negocio encaja; sáltalo si no. Publicar todos los tipos «por completitud» es la trampa de 2018.
Errores de validación comunes que silenciosamente matan tu schema
La prueba de resultados enriquecidos valida la estructura (campos requeridos, tipos, sintaxis). No señala problemas más sutiles que hacen que las IA ignoren tu schema. Valida primero y luego revisa esto:
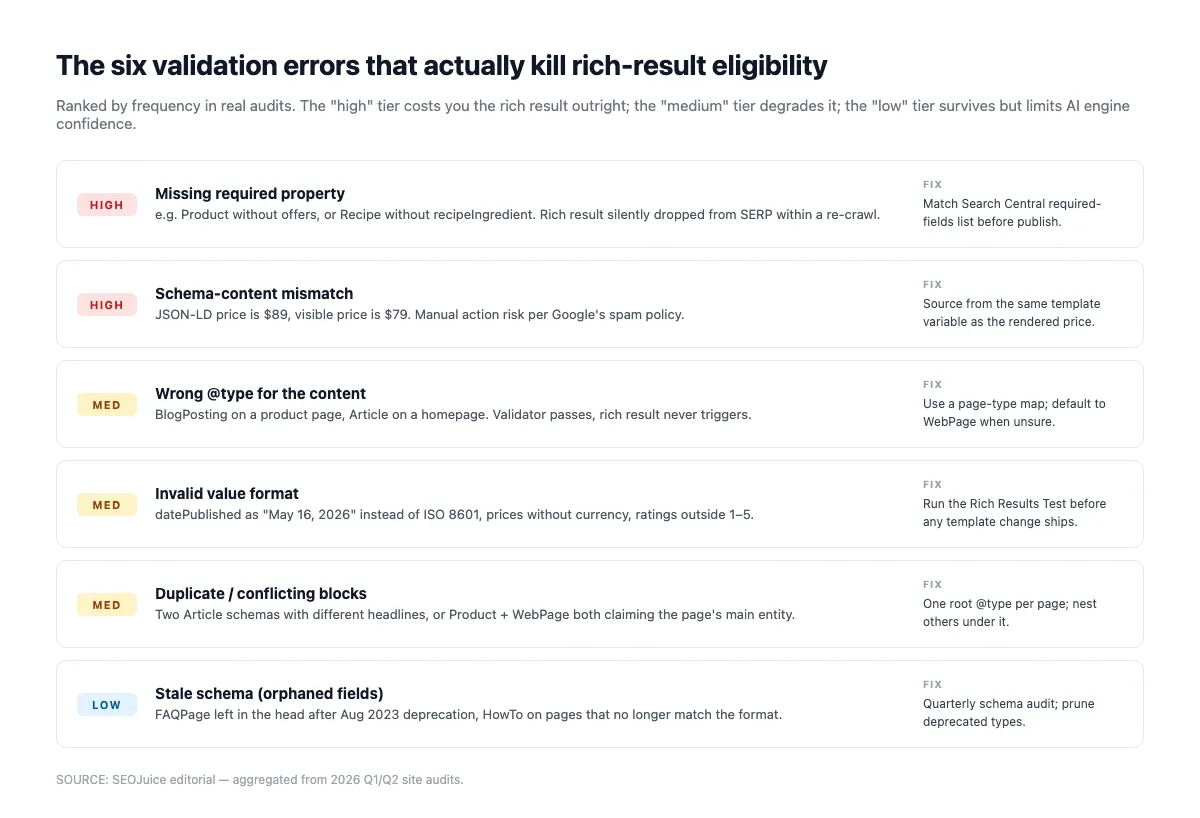
Propiedades requeridas ausentes. La prueba las detecta. Article necesita headline, datePublished, image, author, publisher. Product necesita name y offers. LocalBusiness requiere name y address. Si falta algo, la elegibilidad para rich results cae a cero.
Desajuste schema-contenido renderizado. Si Product.offers.price marca 49 $ y la página muestra 59 $, Google y las IA sospechan. Las IA degradan la cita; Google puede imponer una acción manual por «datos estructurados engañosos». Aleyda Solis lo advirtió hace años y sigue vigente:
«Alejarse de estas directrices puede impedir lograr el resultado deseado o incluso conllevar una acción manual.» — Aleyda Solis, Search Engine Land, noviembre 2019
Entidades huérfanas. Una Organization sin referencia @id es invisible para el knowledge graph. Conecta tus entidades. Article.publisher debe referenciar con @id a la Organization a nivel de sitio, no redefinirla cada vez.
Fechas inválidas. ISO 8601 con zona horaria (YYYY-MM-DDTHH:MM:SS±HH:MM) es el único formato seguro. «15 de enero de 2026» o «2026-01-15» sin hora se degradan en las IA que usan la fecha para puntuar frescura.
@type incorrecto. Etiquetar un índice de blog como Article (en lugar de CollectionPage) o un ticker de noticias como BlogPosting (en vez de NewsArticle) confunde la clasificación de entidad. Ajusta el tipo al contenido real.
Review/AggregateRating autocomplaciente. Reviews donde reviewedBy es igual a itemReviewed (o AggregateRating sin reviewCount creíble + sourceOrganization) se filtran. Usa plataformas de reviews de terceros con marcado correcto o evita Review.
Tabla de estado schema-vs-rich-result
Referencia rápida. «Rich result» = tratamiento visible en Google. «AI parse» = al menos uno de Perplexity, ChatGPT, Claude o Modo IA consume el tipo.
| Tipo de schema | Rich result de Google (2026) | IA lo analiza | ¿Implementar? |
|---|---|---|---|
| Organization | Knowledge panel | Los cuatro | Todo sitio |
| Article / NewsArticle / BlogPosting | Top Stories, Discover, fecha | Los cuatro | Sitios editoriales |
| Product | Merchant listings, precio/disponibilidad | Perplexity (fuerte), Modo IA | Ecommerce |
| BreadcrumbList | Ruta en SERP | Los cuatro (topología) | Toda página no home |
| LocalBusiness | Local pack, knowledge panel | Modo IA, Perplexity | Sitios locales |
| FAQPage | Solo gobierno/salud desde 2023 | Los cuatro | Solo FAQ reales |
| HowTo | Desktop deprecado | Modo IA, Perplexity | Solo para how-tos reales |
| Review / AggregateRating | Estrellas (terceros) | Modo IA | Solo con reviews reales |
| Recipe | Tarjeta completa | Perplexity, Modo IA | Sitios de recetas |
| Event | Carrusel de eventos | Modo IA | Sitios de eventos |
| VideoObject | Miniatura | Modo IA | Cuando el vídeo es clave |
| Service | Ninguno | Modo IA | Opcional, solo IA |
En qué se equivoca AI Overviews respecto al schema
Vale la pena aclararlo porque el relato se desvió en 2025. El titular fácil es «AI Overviews se basa totalmente en el schema, así que añade todos los tipos». La realidad es más tranquila. AI Overviews y Modo IA usan el schema para desambiguar entidades y extraer campos, pero la decisión de citación depende sobre todo de la calidad de recuperación (si la página responde a la consulta) y de señales de autoridad.
El trabajo empírico compartido en Tech SEO Connect 2025 coincide: el dato estructurado es necesario pero no suficiente. Páginas con schema limpio pero contenido pobre no se citan. Páginas con gran contenido pero sin schema sí se citan, pero con metadatos degradados (sin autor claro, fecha imprecisa, precio sin mostrar). La combinación gana.
Otro mito: que los LLM raspan directamente el JSON-LD. La mayoría no, al menos no con el modelo en sí. Una capa de recuperación y fundamentación delante del modelo analiza el schema, extrae campos y los introduce en el prompt como contexto estructurado. Cuando el modelo genera la respuesta, el schema ya fue procesado. Un schema mal formado no tiene segunda oportunidad: si el analizador no captó el precio, el modelo no tiene plan B.
Así que: implementa schema para la capa de recuperación, no para el modelo. Valida con rigor, mantén las referencias @id coherentes y resiste la tentación de marcarlo todo porque schema.org tenga un tipo para ello.
Qué hacer realmente este trimestre
Cuatro pasos. Ninguno requiere proveedor ni rediseño.
Primero, audita lo que ya publicas. Ejecuta la prueba de rich results en tus diez páginas con más tráfico. Anota qué tipos están presentes, cuáles validan y cuáles generan rich results. Encontrarás al menos un tipo obsoleto de la guía de 2018.
Segundo, poda. Elimina FAQPage y HowTo de páginas donde el contenido no sea realmente FAQ o paso a paso. Quita bloques Service sin Offer real. Elimina Review/AggregateRating donde el revisor seas tú mismo.
Tercero, añade la columna vertebral de entidades. Publica un bloque JSON-LD de Organization en todo el sitio, en el head, con logo, sameAs, founder, address. Añade BreadcrumbList en cada página no home. El generador de schema de SEOJuice produce JSON-LD validado para pegar, útil al desplegar Organization y Article en muchas plantillas.
Cuarto, instrumenta. Rastrea las citas de IA con una herramienta que consulte Perplexity, ChatGPT y Modo IA para tus búsquedas de marca y de productos principales. Los datos antes-y-después te dirán si el trabajo de schema dio frutos.

Lecturas complementarias. Cómo lograr que tu marca aparezca en ChatGPT, Perplexity y Google IA cubre el lado de las citas de marca; optimización para Perplexity, la búsqueda de ChatGPT y el Modo IA de Google trata la forma de contenido. Este artículo es el raíl del schema.
Lo que el schema no hará por ti
La despedida honesta. El schema no es un factor de ranking directo. Google lo dejó claro desde 2019. Añadir schema Product a una ficha pobre no la hará superar a un competidor con contenido sólido. Agregar Article a un post sin backlinks ni señales E-E-A-T no lo llevará a Top Stories. El schema no fabrica autoridad; expresa la que ya existe en un formato legible por máquinas.
Lo que sí hace el schema es desambiguar. Cuando dos páginas compiten por la misma consulta y una tiene entidades limpias Organization + Article, esa es la cita más fácil. Cuando un knowledge panel decide qué «Acme» busca el usuario, gana la Organization con sameAs a Wikidata. Cuando Modo IA fundamenta una conversación de compra multivuelta, la Product con Offers válidos es la fuente.
Ese es el contrato de 2026. El schema no te sube en los rankings. Te hace legible cuando una IA decide a quién citar y muestra tus campos estructurados de forma limpia cuando aparece esa cita. Seis o siete tipos cumplen ese contrato para la mayoría de sitios. El resto son opcionales por vertical, opcionales para IA o reliquias de una era de formatos SERP que terminó en agosto de 2023.
FAQ
¿Es el schema un factor de ranking en 2026? No, al menos no directamente. Los datos estructurados ayudan a Google a entender el contenido, pero no aportan un impulso genérico. Lo que sí afectan es la elegibilidad a rich results y la aparición en citas de IA. Ambos importan; ninguno es «ranking» en el sentido clásico.
¿Debo seguir implementando schema FAQ aunque Google deprecara el rich result? Solo si el contenido FAQ es realmente útil. El rich result desapareció para sitios que no sean de gobierno o salud, pero Modo IA y Perplexity aún analizan FAQPage para recuperación. No fabriques FAQs solo por el schema; márcalo donde las preguntas sean reales.
¿JSON-LD o Microdata en 2026? JSON-LD. Microdata aún valida y Google lo lee, pero los analizadores de IA están afinados para bloques JSON-LD en el head. El trabajo nuevo debe ser JSON-LD; Microdata heredado puede quedarse si ya funciona limpio.
¿Cuál es el set mínimo de schema para un SaaS o sitio de servicios? Organization (head en todo el sitio), BreadcrumbList (cada página no home), Article (cada página editorial). Añade Product o LocalBusiness si se ajusta a tu negocio.
¿Penaliza Google las páginas sobre-marcadas? No por completitud, pero sí por schema engañoso o interesado. El schema que contradice al contenido puede provocar una acción manual por «datos estructurados engañosos». Review/AggregateRating autocomplaciente se filtra en silencio. El listón es «válido y honesto», no «mínimo».
Read More
- SEO de Knowledge-Based Trust: un modelo de auditoría basado en hechos, no un truco de posicionamiento
- Guía de Autoridad de Dominio
- Nofollow vs Dofollow: por qué el antiguo enfoque binario dejó de funcionar
- Cómo automatizar el enlazado interno en un sitio de 50 páginas sin comprometer tu mapa temático
- Estadísticas de SEO 2026: Lo que aprendimos rastreando la web
- Enviáste tu sitio y no aparece en Google. Esto es por qué.
no credit card required
No related articles found.