Fiche mémo Schema.org 2026 pour les résultats enrichis de Google et les citations IA
TL;DR : Schema.org n’est pas mort, mais la plupart du battage de 2018 n’est plus déployé. Google continue d’afficher des résultats enrichis pour Article, Product, LocalBusiness, BreadcrumbList, Organization, Review et Recipe. Les rich results de type FAQ ont disparu pour les sites « normaux » depuis août 2023 ; HowTo a cessé d’apparaître sur mobile la même semaine. La nouveauté en 2026, c’est la couche IA : Perplexity, la recherche ChatGPT, Claude et Google AI Mode analysent tous le JSON-LD pour étayer leurs citations. Le travail ne consiste pas à « ajouter tous les types de schéma », mais à conserver les quatre ou cinq qui valent leurs octets et à structurer vos entités assez proprement pour qu’un LLM n’ait pas à deviner quand il veut vous citer.
Début 2024, un de mes clients avait payé une agence pour ajouter quatorze types de schéma sur tout son site. FAQPage sur chaque article de blog. HowTo sur la moitié des fiches produit. Service, Course et Event dans le pied de page avec des propriétés aléatoires. Aucune de ces balises n’a généré de rich results : FAQ était déprécié depuis août précédent, HowTo l’était sur mobile, et le reste était invalide ou non pris en charge. Nous avons supprimé douze de ces quatorze types, conservé Article, Product et BreadcrumbList, et l’apparence dans les SERP n’a pas bougé. Ce qui a changé, ce sont les citations par l’IA. Mi-2024, Perplexity intégrait des entités Product propres dans les requêtes shopping parce qu’elles étaient les seules à comporter un prix, un GTIN et une marque valides. En 2026, le schéma sert moins à courir après chaque format de rich result qu’à offrir aux moteurs d’IA une ossature lisible par machine.
Pourquoi schema.org compte encore en 2026 (ce n’est plus 2018)
En 2018, le discours était simple : implémentez FAQ et HowTo partout et regardez l’espace des SERP exploser à mesure que Google allongeait les liens bleus avec des déroulants. En 2022, les SERP étaient devenues ingérables : deux sites dotés de FAQ schema occupaient chacun 800 pixels de hauteur, reléguaient les résultats organiques sous la ligne de flottaison et leurs FAQ étaient souvent dupliquées, aspirées ou creuses. La dépréciation d’août 2023 a suivi, et le libellé donnait le ton :
« Les résultats enrichis FAQ (provenant des données structurées FAQPage) ne seront affichés que pour les sites gouvernementaux ou de santé reconnus et faisant autorité. Pour tous les autres sites, ce résultat enrichi ne sera plus affiché de manière régulière. » — Google Search Central, Changes to HowTo and FAQ rich results (août 2023)
Ce qui était présenté comme une simple mise à jour de politique fut en réalité un reset philosophique. Google a cessé de considérer le schéma comme un ornement de SERP et l’a abordé comme un signal de désambiguïsation d’entités. Le gain visible a diminué ; la valeur « sous le capot » a augmenté, car le même JSON-LD qui alimentait les déroulants nourrit désormais le graphe de connaissances que consomment AI Overviews, AI Mode et la couche de crawl agentique.
Pour les exploitants, la conclusion est limpide : cessez de compter les formats de rich result, commencez à compter les entités propres. Le schéma que vous déployez en 2026 est lu par au moins quatre moteurs qui n’existaient pas en 2018 : la recherche ChatGPT, Perplexity, Claude (via l’outil web d’Anthropic) et Google AI Mode. Chacun possède sa logique d’ingestion, mais tous préfèrent le JSON-LD au Microdata et récompensent les entités complètes et valides plutôt que le bourrage de propriétés.
Quels rich results Google affiche encore réellement
La liste 2026 est courte. Une fois écartés les formats dépréciés et les types très nichés (Movie, Book, Course-info, Dataset), il ne reste qu’une poignée de types qui méritent leur place sur la plupart des sites commerciaux.

Article est le cheval de trait pour l’éditorial et l’actu. Headline, datePublished, dateModified, author et publisher sont les propriétés porteuses ; Google s’y réfère pour les carrousels « Top stories », les encarts d’actus et la ligne de date sous les liens bleus. Discover s’appuie sur la propriété image (minimum 1200 px de large).
Product est le schéma à plus forte valeur ajoutée pour l’e-commerce. Offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU et aggregateRating alimentent les fiches marchandes. Google a durci les exigences en 2024 puis début 2026. L’absence de GTIN sur un produit de marque rétrograde désormais la fiche en silence au lieu de déclencher un avertissement dans la Search Console : le signal le plus clair que l’exhaustivité du schéma est notée, pas seulement validée.
LocalBusiness alimente le pack local et les cartes sur Maps. Name, address, telephone, openingHoursSpecification, coordonnées géo et priceRange remplissent le knowledge panel. BreadcrumbList s’affiche dans la SERP comme le chemin d’accès sous le titre et se parse proprement pour la topologie de site côté IA. Organization est la colonne vertébrale : logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, profils sociaux vérifiés), founder, foundingDate, address. Les moteurs d’IA s’y fient particulièrement lorsqu’ils doivent choisir quel « Acme » citer.
Review et AggregateRating s’affichent encore, mais Google a restreint l’éligibilité fin 2024. Les avis auto-attribués (Organization se notant elle-même, Product évalué uniquement par le vendeur) ont été retirés. Les avis vérifiés par un tiers apparaissent toujours lorsque reviewedBy.Organization ou sourceOrganization renvoie à un véritable évaluateur.
FAQPage et HowTo sont les victimes de la dépréciation. Ne supprimez pas le balisage si vous l’avez déjà (Google est clair : des données structurées valides mais non utilisées ne nuisent pas), mais cessez d’y consacrer du temps pour leur apparence dans les SERP.
Ce que les moteurs d’IA extraient réellement du JSON-LD
C’est là que la question de l’opérateur a basculé entre 2024 et 2026 : on est passé de « qu’est-ce que Google affiche ? » à « qu’est-ce qui me fait citer par ChatGPT ? »
Chaque moteur traite les données structurées à sa façon, mais le schéma commun est simple : ils utilisent le balisage comme couche d’ancrage, source de vérité parallèle au texte rendu, pour désambiguïser les entités, attacher la provenance et récupérer des valeurs (prix, dates, notes) sans les ré-extraire du texte. Quand le contenu et le schéma concordent, la confiance est haute. Quand ils divergent, le schéma devient suspect et la citation est rétrogradée ou redirigée.
Aleyda Solis a résumé la position officielle de Google depuis Search Central Zurich fin 2025 :
« C’est toujours important. En particulier pour les données à portée réglementaire ou faisant autorité, comme les prix dans le shopping, c’est très important. » — Aleyda Solis citant Google à propos de Gemini et des données structurées, compte-rendu Search Central Zurich 2025
Les quatre moteurs se répartissent ainsi :
Perplexity analyse le JSON-LD de façon agressive. Les requêtes shopping extraient Product.offers.price et Product.brand pour les afficher dans les cartes de réponse ; côté éditorial, Article.author et Article.datePublished servent de signature. L’absence de schéma n’empêche pas la citation, mais sa présence génère des cartes plus propres qu’un simple résumé de page.
ChatGPT search (l’outil Browse d’OpenAI) extrait Organization et Article pour adjoindre les métadonnées de publication. La ligne « cité il y a X minutes par Y » s’appuie sur Organization.name et Article.datePublished. Plus tolérant que Perplexity vis-à-vis de l’absence de schéma, mais valorise les entités Organization complètes.
Claude, via l’outil web d’Anthropic, n’affiche pas directement les champs du schéma, mais son retrieval pondère la désambiguïsation. Les pages dotées d’un couple Organization + Article propre l’emportent sur celles sans schéma lorsqu’il existe plusieurs sources sur le même sujet.
Google AI Mode est le plus sensible au schéma. Il lit le JSON-LD qui alimente les rich results classiques ainsi que des types que Google n’a jamais affichés (Service, Event, EducationalOccupationalCredential), afin d’ancrer les conversations multi-tours. C’est dans AI Mode que l’exhaustivité poussée du schéma rapporte le plus.

Signal commun aux quatre : JSON-LD plutôt que Microdata ou RDFa, à chaque fois. Le Microdata valide encore et Google le lit toujours, mais les parseurs des moteurs d’IA sont optimisés pour les blocs JSON-LD placés dans le head et extraient moins bien le Microdata inline. Le Microdata existant n’est pas cassé ; les nouveaux travaux doivent être en JSON-LD.
Les types de schéma qui valent encore la peine d’être implémentés
Ordre de priorité pour un site commercial générique en 2026.
1. Organization (toutes les pages, dans le bloc script du head). Logo, sameAs vers les profils vérifiés, founder, address. Le point d’ancrage d’entité sur lequel s’appuient les moteurs d’IA. Ajoutez-le une fois et n’y touchez plus.
2. BreadcrumbList (toutes les pages sauf la home). Facile à mettre en place, s’affiche dans les SERP comme le chemin d’accès et se parse proprement pour la topologie de site côté IA. Aucune raison de s’en passer.
3. Article (chaque page blog/actu/éditoriale). Headline, author (Person imbriqué avec sameAs), datePublished, dateModified, publisher, image. Discover et les surfaces de citation IA s’appuient sur ces champs.
4. Product (chaque fiche produit en e-commerce). Offers avec price + priceCurrency + availability, brand, GTIN ou MPN, aggregateRating lorsqu’il est authentique. C’est là que se joue la visibilité en fiches marchandes et que Perplexity puise pour ses cartes produit. Utilisez le générateur de balisage SEOJuice pour un bloc de départ ; faire Product à la main est risqué car l’imbrication Offers piège facilement.
5. LocalBusiness (chaque page d’implantation). Spécialisez vers le sous-type approprié (Restaurant, MedicalClinic, Dentist, ProfessionalService) quand c’est pertinent. Le type générique fonctionne toujours, mais les versions spécialisées ressortent mieux dans les panels.
6. FAQPage (uniquement quand c’est vraiment utile). N’ajoutez pas ce schéma pour l’apparence SERP ; ce train est parti en août 2023. Déployez-le là où les questions sont réelles et bien répondues. Les moteurs d’IA l’utilisent encore pour le retrieval. Lily Ray l’a bien résumé dans un post LinkedIn de 2024 :
« Proposez de vraies FAQ sur votre site si elles aident vraiment les utilisateurs. Mais évitez de spammer avec des tonnes de questions longue traîne/PAA si vous ne voulez pas finir en prison Google. » — Lily Ray, LinkedIn (fin 2024)
7. HowTo (même avertissement). Déprécié sur mobile depuis août 2023, mais le schéma aide toujours les moteurs d’IA à ancrer les requêtes pas-à-pas. Si votre page est vraiment un tutoriel, balisez-la. Si vous forcez le trait, abstenez-vous.
Tout le reste (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) est spécifique à un vertical. Implémentez uniquement quand cela correspond à votre offre, passez votre chemin sinon. Déployer tous les types « pour faire complet » est le piège de 2018.
Erreurs de validation courantes qui sabotent discrètement votre schéma
Le Rich Results Test valide la structure (champs obligatoires, types, syntaxe). Il ne détecte pas les problèmes plus subtils qui poussent les moteurs d’IA à ignorer votre schéma. Exécutez d’abord le validateur, puis auditez les points suivants :
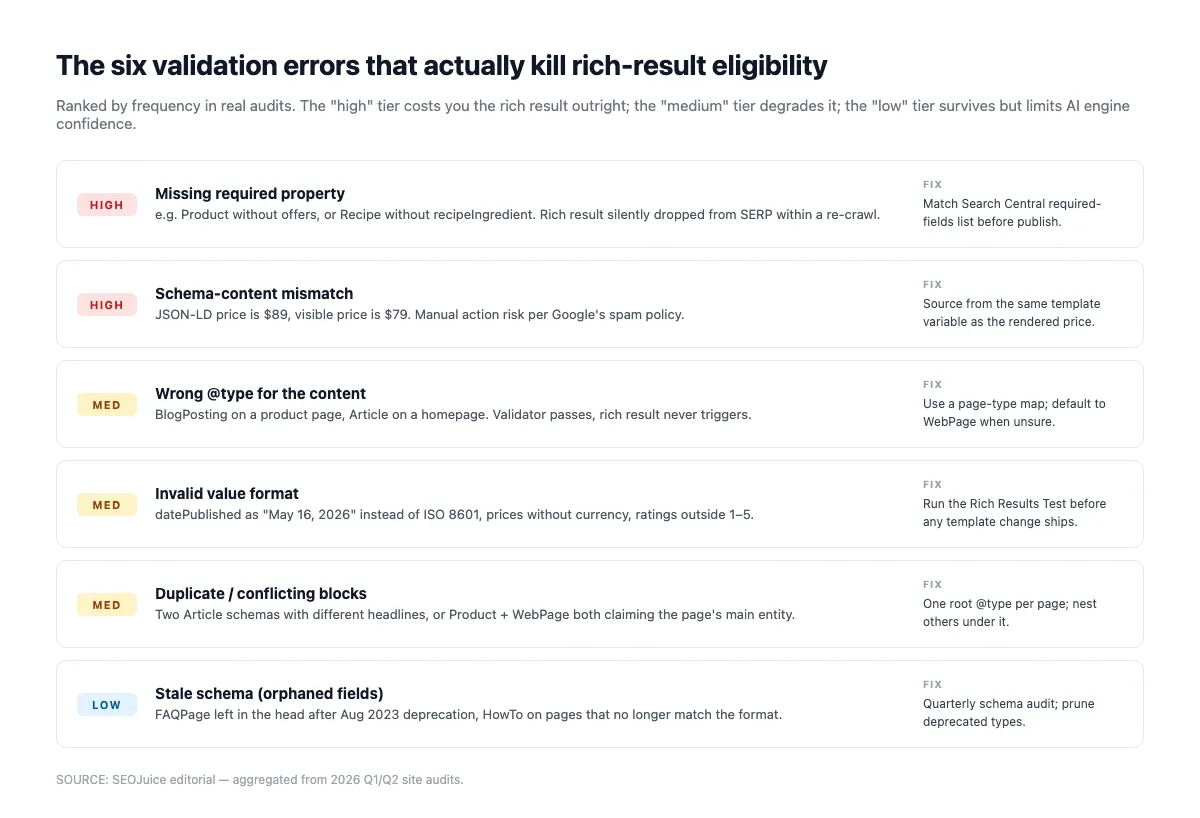
Propriétés obligatoires manquantes. Le Rich Results Test les détecte. Article requiert headline, datePublished, image, author, publisher. Product a besoin de name et offers. LocalBusiness exige name et address. Ratez-en une et l’éligibilité aux rich results tombe à zéro.
Divergence schéma/ contenu rendu. Si Product.offers.price indique 49 $ mais que la page affiche 59 $, Google comme les moteurs d’IA suspectent le schéma. Les moteurs d’IA rétrogradent la citation ; Google peut déclencher une action manuelle pour « structured data trompeuses ». Aleyda Solis l’avait déjà signalé il y a des années et l’avertissement reste valable :
« S’éloigner de ces consignes peut vous empêcher d’obtenir le résultat souhaité, voire entraîner une action manuelle. » — Aleyda Solis, Search Engine Land, novembre 2019
Entités orphelines. Une Organization non référencée via @id est invisible pour le graphe de connaissances. Reliez vos entités. Article.publisher doit faire référence via @id à l’Organization du site, pas la redéfinir inline.
Formats de date invalides. ISO 8601 avec fuseau (YYYY-MM-DDTHH:MM:SS±HH:MM) est le seul format vraiment sûr. « 15 janvier 2026 » ou « 2026-01-15 » sans heure sont silencieusement déclassés par les moteurs d’IA qui notent la fraîcheur.
Mauvais @type. Taguer un index de blog en Article (au lieu de CollectionPage) ou un ticker d’actualités en BlogPosting (au lieu de NewsArticle) brouille la classification. Alignez le type sur la forme réelle du contenu.
Review/AggregateRating auto-satisfaits. Les avis où reviewedBy égale itemReviewed (ou AggregateRating sans reviewCount crédible + sourceOrganization) sont filtrés. Utilisez des plateformes d’avis tierces correctement balisées ou abstenez-vous de Review.
Tableau d’état type de schéma vs rich result
Référence rapide. « Rich result » = traitement visible dans la SERP Google. « AI parse » = au moins Perplexity, ChatGPT, Claude ou AI Mode consomme activement ce type.
| Type de schéma | Rich result Google (2026) | Lecture IA | À implémenter ? |
|---|---|---|---|
| Organization | Knowledge panel | Les quatre | Tous les sites |
| Article / NewsArticle / BlogPosting | Top stories, Discover, dateline | Les quatre | Sites éditoriaux |
| Product | Fiches marchandes, prix/stock | Perplexity (intensif), AI Mode | E-commerce |
| BreadcrumbList | Chemin dans la SERP | Les quatre (topologie) | Toutes les pages hors home |
| LocalBusiness | Pack local, knowledge panel | AI Mode, Perplexity | Sites locaux |
| FAQPage | Gouvern./santé uniquement depuis août 2023 | Les quatre (toujours lus) | Uniquement si les FAQ sont réelles |
| HowTo | Desktop déprécié depuis août 2023 | AI Mode, Perplexity | Seulement pour de vrais tutos |
| Review / AggregateRating | Étoiles (tiers uniquement) | AI Mode | Uniquement avec de vrais avis tiers |
| Recipe | Carte enrichie complète | Perplexity, AI Mode | Sites de recettes |
| Event | Carrousel d’événements | AI Mode | Sites d’événements |
| VideoObject | Vignette vidéo | AI Mode | Quand la vidéo est centrale |
| Service | Aucune visible | AI Mode | Optionnel, ancrage IA seulement |
Ce que les AI Overviews comprennent mal du schéma
Il faut le dire clairement, car le récit a dérapé en 2025. Le hot take : « AI Overviews s’appuie entièrement sur le schéma, donc ajoutez tous les types ». La réalité est plus nuancée. AI Overviews et AI Mode se servent du schéma pour désambiguïser les entités et extraire les champs, mais la décision de citation dépend surtout de la qualité du retrieval (la page répond-elle à la requête ?) et des signaux d’autorité.
Les travaux empiriques présentés à Tech SEO Connect 2025 aboutissent à la même conclusion : les données structurées sont nécessaires mais pas suffisantes. Des pages avec un schéma propre mais un contenu maigre ne sont pas citées. Des pages avec un excellent contenu mais sans schéma le sont, mais avec des métadonnées dégradées (auteur approximatif, date floue, prix absent). Le combo gagne.
Autre mythe : les LLM « grattent » directement le JSON-LD. La plupart ne le font pas, du moins pas via le modèle lui-même. Une couche de retrieval et d’ancrage en amont parse le schéma, extrait les champs et les injecte dans le prompt sous forme de contexte structuré. Au moment où le modèle répond, le schéma est déjà digéré. Un schéma mal formé n’a pas de seconde chance : si le parseur a raté le champ prix, le modèle n’a aucun recours.
Donc : implémentez le schéma pour la couche de retrieval, pas pour le modèle. Validez de façon agressive, maintenez des références @id cohérentes, résistez à l’envie de tout baliser sous prétexte que schema.org propose un type.
Que faire concrètement ce trimestre
Quatre étapes, sans besoin de prestataire ni de refonte.
Premièrement, auditez ce qui est publié. Lancez le Rich Results Test sur vos dix pages les plus consultées. Notez les types présents, ceux qui valident et ceux qui déclenchent un rich result. Vous trouverez au moins un type périmé issu des conseils de 2018.
Deuxièmement, élaguez. Supprimez FAQPage et HowTo des pages où le contenu n’est pas vraiment une FAQ ou un tutoriel. Retirez les blocs Service sans Offer réelle. Supprimez Review/AggregateRating lorsque l’évaluateur, c’est vous.
Troisièmement, ajoutez la colonne vertébrale des entités. Publiez un bloc JSON-LD Organization global dans le head avec logo, sameAs, founder, address. Déployez BreadcrumbList sur chaque page hors home. Le générateur de balisage SEOJuice produit un JSON-LD validé que vous pouvez coller dans le head, pratique pour déployer Organization et Article sur de nombreux templates.
Quatrièmement, instrumentez. Suivez l’apparition des citations IA avec un outil qui interroge Perplexity, ChatGPT et AI Mode sur vos requêtes de marque et de produits phares. Les données avant/après vous diront si le travail de schéma a porté ses fruits.

Lectures complémentaires. How to get cited by ChatGPT, Perplexity, and Google AI traite de la citation de marque ; optimizing for Perplexity, ChatGPT search, and Google AI Mode aborde la forme du contenu. Le présent article est le rail schéma.
Ce que le schéma ne fera pas pour vous
Pour conclure honnêtement : le schéma n’est pas un facteur de classement direct. Google l’affirme depuis 2019. Ajouter Product à une fiche produit maigre ne la fera pas dépasser un concurrent au contenu plus riche. Ajouter Article à un post sans backlinks ni signaux E-E-A-T ne le propulsera pas dans Top Stories. Le schéma ne crée pas l’autorité ; il l’exprime dans un format lisible par les machines.
Ce que fait le schéma, c’est la désambiguïsation. Quand deux pages ciblent la même requête et que l’une possède des entités Organization + Article propres, c’est elle la cible de citation privilégiée. Quand un knowledge panel doit choisir quel « Acme » est recherché, l’Organization reliée à Wikidata via sameAs l’emporte. Quand AI Mode ancre une conversation shopping multi-tours, c’est le Product avec des Offers valides qui sert de source.
C’est le contrat 2026 : le schéma ne vous fait pas grimper, il vous rend lisible quand un moteur d’IA choisit qui citer, et fait remonter vos champs structurés quand la citation s’affiche. Six ou sept types suffisent à honorer ce contrat sur la plupart des sites. Les autres sont optionnels (vertical, ancrage IA) ou vestiges d’une époque orientée SERP qui s’est terminée en août 2023.
FAQ
Le schéma est-il un facteur de classement en 2026 ? Non, pas directement. Les données structurées aident Google à comprendre le contenu mais ne constituent pas un boost générique. Elles influent sur l’éligibilité aux rich results et l’affichage des citations IA. Les deux comptent, aucun n’est du « ranking » au sens classique.
Dois-je encore implémenter le schéma FAQ même si Google a déprécié le rich result ? Uniquement si vos FAQ sont vraiment utiles. Le rich result a disparu pour les sites hors gouvernement/santé, mais AI Mode et Perplexity lisent toujours FAQPage pour le retrieval. Ne fabriquez pas de fausses FAQ ; balisez là où elles existent réellement.
JSON-LD ou Microdata en 2026 ? JSON-LD. Le Microdata valide encore et Google le lit, mais les parseurs IA sont calibrés pour les blocs JSON-LD dans le head. Les nouveaux travaux doivent être en JSON-LD ; le Microdata existant peut rester s’il est propre.
Quel est le minimum de schéma pour un site SaaS ou de services ? Organization (head global), BreadcrumbList (chaque page hors home), Article (chaque page blog/éditoriale). Ajoutez Product ou LocalBusiness si cela correspond à votre offre.
Google pénalise-t-il les pages sur-balisées ? Pas pour cause d’exhaustivité, mais oui pour les schémas trompeurs ou auto-promotionnels. Un schéma qui contredit le contenu peut déclencher une action manuelle pour « structured data trompeuses ». Les Review/AggregateRating auto-attribués sont filtrés sans bruit. Le critère est « valide et honnête », pas « minimal ».
Read More
- SEO basé sur la confiance fondée sur les connaissances : un modèle d’audit factuel, pas une astuce de classement
- Guide de l’autorité de domaine
- Nofollow vs Dofollow : pourquoi l’ancien modèle binaire ne fonctionne plus
- Comment automatiser le maillage interne d’un site de 50 pages sans compromettre votre cocon sémantique
- Statistiques SEO 2026 : ce que nous avons appris en explorant le web
- Vous avez déployé votre site et il n’apparaît pas sur Google. Voici pourquoi.
no credit card required
No related articles found.