Ściągawka Schema.org 2026 dotycząca rozszerzonych wyników Google i cytowań AI
TL;DR: Schema.org nie umarło, ale większość hype’u z 2018 r. już nie działa. Google wciąż pokazuje rozszerzone wyniki dla Article, Product, LocalBusiness, BreadcrumbList, Organization, Review i Recipe. Wyniki FAQ zniknęły dla zwykłych witryn w sierpniu 2023 r.; HowTo w tym samym tygodniu przestało działać w mobile. Nowością w 2026 r. jest warstwa AI. Perplexity, wyszukiwarka ChatGPT, Claude i Google AI Mode analizują JSON-LD, by uwiarygodnić cytaty. Zadanie to nie „dodać każdy typ schematu”, lecz zachować cztery–pięć, które naprawdę zarabiają na swoje bajty, i uporządkować encje tak czysto, by LLM nie musiał zgadywać, gdy chce Cię zacytować.
Na początku 2024 r. miałem klienta, który zapłacił agencji za dodanie czternastu typów schematu na całej stronie. FAQPage w każdym wpisie blogowym. HowTo na połowie stron produktowych. Service, Course i Event w stopce z losowymi właściwościami. Żaden nie wygenerował rozszerzonych wyników: FAQ było już zdeprecjonowane, HowTo wyłączone na mobile, a reszta była niepoprawna lub nieobsługiwana. Usunęliśmy dwanaście z czternastu, zostawiliśmy Article, Product i BreadcrumbList – wygląd SERP się nie zmienił. Zmieniły się cytaty AI: w połowie 2024 r. Perplexity wyciągało czyste encje Product w zapytaniach zakupowych, bo tylko one miały poprawne ceny, GTIN i brand. W 2026 r. schema to mniej pogoń za każdym formatem rich-result, a bardziej dostarczenie silnikom AI czytelnego, maszynowego szkieletu.
Dlaczego schema.org wciąż ma znaczenie w 2026 r. (to nie 2018)
W 2018 r. pitch był prosty: wdrożyć FAQ i HowTo wszędzie, patrzeć jak nieruchomość w SERP puchnie, gdy Google rozbudowuje niebieskie linki o dropdowny. Do 2022 r. SERP-y stały się chaosem. Dwie strony z FAQ zajmowały po 800 pikseli w pionie, spychając wyniki poniżej załamania strony, a treść FAQ była zwykle skopiowana lub miałka. W sierpniu 2023 r. Google wycofało się z tego formatu, a komunikat ustawił ton:
„Rozszerzone wyniki FAQ (z danych strukturalnych FAQPage) będą wyświetlane wyłącznie w znanych, autorytatywnych witrynach rządowych i zdrowotnych. Dla wszystkich innych witryn ten wynik będzie pojawiał się nieregularnie.” — Google Search Central, Changes to HowTo and FAQ rich results (sierpień 2023)
To, co wyglądało na małą aktualizację, było tak naprawdę filozoficznym resetem. Google przestało traktować schemat jako ozdobę SERP, a zaczęło jako sygnał do rozróżniania encji. Widoczna nagroda się skurczyła; wartość pod maską wzrosła, bo ten sam JSON-LD, który napędzał dropdowny, dziś zasila graf wiedzy używany przez AI Overviews, AI Mode i warstwę agentycznego crawlingu.
Dla operatorów wniosek jest jasny: przestań liczyć formaty rich-result, zacznij liczyć czyste encje. Schemat, który wysyłasz w 2026 r., czyta co najmniej czterech graczy, którzy nie liczyli się w 2018: ChatGPT search, Perplexity, Claude (przez narzędzie webowe Anthropic) i Google AI Mode. Każdy ma własną logikę pobierania, ale wszystkie wolą JSON-LD od Microdata i nagradzają kompletne, poprawne encje zamiast upychania właściwości.
Jakie rich results Google wciąż faktycznie pokazuje
Lista na 2026 r. jest krótka. Po odcięciu formatów zdeprecjonowanych i wąskich wertykalnie (Movie, Book, Course-info, Dataset) zostaje garstka typów, które zasługują na miejsce na większości stron komercyjnych.

Article to koń roboczy dla treści redakcyjnych i newsów. Headline, datePublished, dateModified, author i publisher to właściwości nośne; Google czyta je do karuzel Top Stories, boksów newsowych i dat pod niebieskimi linkami. Discover opiera się na image (minimum 1200 px szerokości).
Product to najwyżej wyceniany schemat w ecommerce. Offers (price, priceCurrency, availability), brand, GTIN/MPN/SKU i aggregateRating napędzają listingi handlowe. Google zaostrzył wymagania w 2024 r. i ponownie na początku 2026 r. Brak GTIN przy markowym produkcie dziś po cichu obniża listing zamiast pokazać ostrzeżenie w Search Console – czytelny sygnał, że liczy się kompletność, nie tylko walidacja.
LocalBusiness zasila local pack i szczegóły kart na mapie. Name, address, telephone, openingHoursSpecification, współrzędne geo i priceRange trafiają do panelu wiedzy. BreadcrumbList pojawia się w SERP jako ścieżka pod tytułem i czytelnie opisuje topologię witryny dla AI. Organization to kręgosłup encji: logo, sameAs (Wikidata, Wikipedia, LinkedIn, Crunchbase, GitHub, zweryfikowane profile społecznościowe), founder, foundingDate, address. Silniki AI opierają się na tym najmocniej, gdy decydują, które „Acme” cytować.
Review i AggregateRating wciąż się pojawiają, ale Google zawęził kryteria pod koniec 2024 r. Samooceny (Organization oceniająca siebie, Product oceniony wyłącznie przez sprzedawcę) zostały wycięte. Recenzje zweryfikowane przez podmiot trzeci są pokazywane, gdy reviewedBy.Organization lub sourceOrganization wskazuje prawdziwego recenzenta.
FAQPage i HowTo to ofiary deprecjacji. Nie kasuj znacznika, jeśli już jest (Google jasno mówi, że nieużyte, ale poprawne dane strukturalne nie szkodzą), ale przestań inwestować godziny w jego utrzymanie dla widoczności SERP.
Co silniki AI faktycznie parsują z JSON-LD
Tu pytanie operatora zmieniło się między 2024 a 2026 r.: z „co pokazuje Google?” na „co daje mi cytat w ChatGPT?”
Każdy silnik obsługuje dane strukturalne inaczej, ale schemat jest podobny. Używają schematu jako warstwy ugruntowania, równoległego źródła prawdy obok renderowanego tekstu, by rozróżnić encje, przypisać pochodzenie i pobrać pola (ceny, daty, oceny) bez ponownego wyciągania z prozy. Gdy treść i schema są spójne, pewność jest wysoka. Gdy się różnią, schemat jest podejrzany, a cytat degradowany lub kierowany gdzie indziej.
Aleyda Solis podsumowała stanowisko Google z Search Central Zurich pod koniec 2025 r.:
„To wciąż ważne. Zwłaszcza w przypadku danych o znaczeniu regulacyjnym, jak ceny w zakupach, jest to bardzo istotne.” — Aleyda Solis cytująca Google o Gemini i danych strukturalnych, Search Central Zurich 2025 recap
Cztery silniki rozkładają się tak:
Perplexity agresywnie parsuje JSON-LD. Zapytania zakupowe wyciągają Product.offers.price i Product.brand do kart z odpowiedziami; w treściach redakcyjnych pokazywane są Article.author i Article.datePublished w byline. Brak schematu nie psuje cytatu, ale obecność daje czystsze karty zamiast generycznego podsumowania strony.
ChatGPT search (narzędzie Browse OpenAI) analizuje Organization i Article, by dołączyć metadane publikacji. Linijka „zacytowano X minut temu przez Y” opiera się na Organization.name i Article.datePublished. Bardziej toleruje brak schematu niż Perplexity, ale nagradza kompletne encje Organization.
Claude, przez narzędzie webowe Anthropic, nie pokazuje pól schematu bezpośrednio, ale w ważeniu wyników kładzie nacisk na rozróżnianie encji. Strony z czystym duetem Organization + Article wygrywają nad tymi bez schematu, gdy temat ma wiele źródeł.
Google AI Mode jest najbardziej świadom schematu. Czyta JSON-LD odpowiedzialny zarówno za klasyczne rich-results, jak i typy nigdy niewidoczne (Service, Event, EducationalOccupationalCredential), ugruntowując rozmowy wieloturnowe. AI Mode to miejsce, gdzie głębsza kompletność schematu najbardziej się zwraca.

Wspólny sygnał dla wszystkich czterech: JSON-LD zamiast Microdata i RDFa, zawsze. Microdata wciąż przechodzi walidację i Google ją czyta, ale parsery AI są strojone na bloki JSON-LD w
i mniej niezawodnie wyciągają dane z inline Microdata. Stara Microdata nie jest zepsuta; nowe prace rób w JSON-LD.Typy schematu, które wciąż warto wdrażać
Priorytet dla przeciętnej strony komercyjnej w 2026 r.
1. Organization (na każdej stronie, w skrypcie w <head>). Logo, sameAs do zweryfikowanych profili, founder, address. Kotwica encji, na której polegają silniki AI. Dodaj raz i nie dotykaj.
2. BreadcrumbList (każda strona poza homepage). Tani, pokazuje się w SERP jako ścieżka, czytelnie opisuje topologię dla AI. Nie ma powodu, by go nie mieć.
3. Article (każda strona blog/news/editorial). Headline, author (Person z sameAs), datePublished, dateModified, publisher, image. Discover i cytaty AI bazują na tych polach.
4. Product (każda strona produktu w ecommerce). Offers z price + priceCurrency + availability, brand, GTIN lub MPN, aggregateRating gdy autentyczny. Tu mieszka widoczność listingów handlowych i stąd Perplexity pobiera karty produktowe. Użyj generatora schematu SEOJuice jako bazy; ręczne poprawne zagnieżdżenie Offers jest trudne.
5. LocalBusiness (każda strona lokalizacji). Użyj właściwego podtypu (Restaurant, MedicalClinic, Dentist, ProfessionalService), gdy pasuje. Ogólny typ działa, ale wyspecjalizowany lepiej wyświetla się w panelach wiedzy.
6. FAQPage (tylko gdy naprawdę potrzebny). Nie wdrażaj FAQ dla wyglądu w SERP – ten pociąg odjechał w sierpniu 2023 r. Użyj, gdy pytania są prawdziwe i dobrze opisane. Silniki AI wciąż to czytają. Lily Ray ujęła to trafnie w poście na LinkedIn w 2024 r.:
„Dostarczaj sensowne FAQ, jeśli są naprawdę pomocne użytkownikom. Ale nie spamuj długim ogonem/PAA, jeśli nie chcesz trafić do Google Jail.” — Lily Ray, LinkedIn (koniec 2024)
7. HowTo (ta sama uwaga). Zdeprecjonowany w mobile od sierpnia 2023, ale wciąż pomaga AI w zapytaniach krok-po-kroku. Jeśli strona to prawdziwe how-to, oznacz. Jeśli naciągasz, pomiń.
Cała reszta (Service, Course, Event, Recipe, Review, JobPosting, SoftwareApplication, VideoObject, BookFormat, Quiz, Dataset) jest specyficzna wertykalnie. Wdrażaj, gdy pasuje do biznesu; pomijaj, gdy nie. Instalacja wszystkiego „dla kompletności” to pułapka z 2018 r.
Typowe błędy walidacji, które po cichu zabijają schemat
Rich Results Test sprawdza poprawność strukturalną (wymagane pola, typy, składnię). Nie oznacza subtelnych problemów, przez które silniki AI ignorują Twój schemat. Uruchom walidator najpierw, potem sprawdź to:
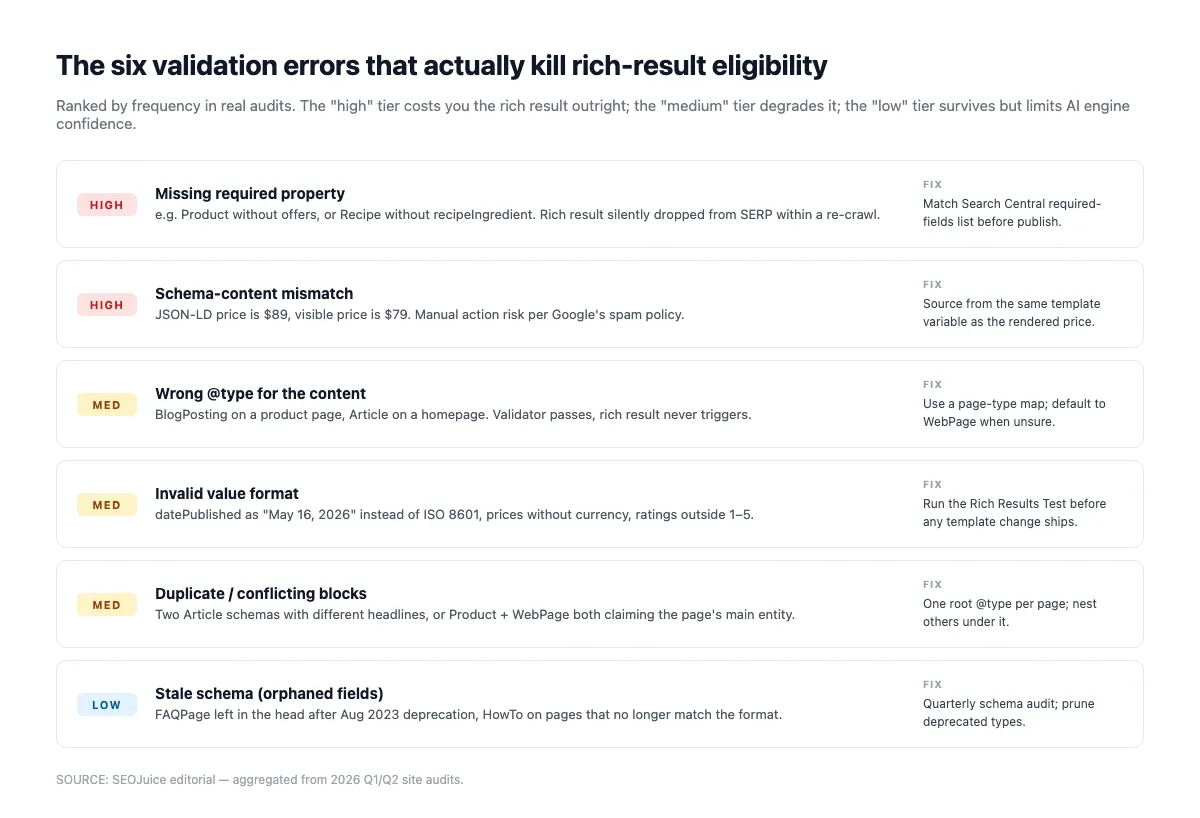
Brak wymaganych właściwości. Rich Results Test to wyłapie. Article potrzebuje headline, datePublished, image, author, publisher. Product wymaga name i offers. LocalBusiness wymaga name i address. Brak jakiegokolwiek = zerowa szansa na rich-result.
Niezgodność schematu z treścią. Jeśli Product.offers.price pokazuje 49 $, a na stronie jest 59 $, Google i AI traktują schemat jako podejrzany. Silniki AI obniżą cytat; Google może nałożyć ręczną karę „misleading structured data”. Aleyda Solis ostrzegała o tym lata temu i wciąż to aktualne:
„Odejście od tych wytycznych może uniemożliwić uzyskanie pożądanego efektu, a nawet skutkować ręczną karą.” — Aleyda Solis, Search Engine Land, listopad 2019
Osierocone encje. Organization, do której nikt nie odwołuje się przez @id, jest niewidoczna dla grafu wiedzy. Połącz encje: Article.publisher powinien odwoływać się do site-level Organization, a nie definiować ją na nowo.
Niepoprawne formaty dat. Tylko ISO 8601 z czasem i strefą (YYYY-MM-DDTHH:MM:SS±HH:MM) jest bezpieczne. „15 stycznia 2026” lub „2026-01-15” bez czasu jest po cichu degradowane przez silniki AI, które potrzebują daty do oceny świeżości.
Zły @type. Oznaczenie indeksu bloga jako Article (zamiast CollectionPage) czy pasku newsowego jako BlogPosting (zamiast NewsArticle) myli klasyfikację encji. Dopasuj typ do faktycznego kształtu treści.
Autocenzuralne Review/AggregateRating. Recenzje, gdzie reviewedBy = itemReviewed (lub AggregateRating bez wiarygodnego reviewCount + sourceOrganization), są filtrowane. Używaj zewnętrznych platform recenzji z poprawnym markupem albo pomiń Review całkiem.
Tablica statusu typ-vs-rich-result
Szybka referencja. „Rich result” = widoczny format w Google. „AI parse” = co najmniej jeden z Perplexity, ChatGPT, Claude lub AI Mode aktywnie konsumuje ten typ.
| Typ schematu | Rich result Google (2026) | AI parse | Warto wdrażać? |
|---|---|---|---|
| Organization | Panel wiedzy | Wszystkie cztery | Każda strona |
| Article / NewsArticle / BlogPosting | Top Stories, Discover, dateline | Wszystkie cztery | Serwisy redakcyjne |
| Product | Listing merchant, cena/dostępność | Perplexity (mocno), AI Mode | Ecommerce |
| BreadcrumbList | Ścieżka w SERP | Wszystkie cztery (topologia) | Każda podstrona |
| LocalBusiness | Local pack, panel wiedzy | AI Mode, Perplexity | Witryny lokalne |
| FAQPage | Rząd/zdrowie od VIII 2023 | Wszystkie cztery (parsują) | Tylko gdy FAQ są realne |
| HowTo | Desktop – deprecated od VIII 2023 | AI Mode, Perplexity | Tylko prawdziwe how-to |
| Review / AggregateRating | Gwiazdkowe oceny (podmiot trzeci) | AI Mode | Tylko przy prawdziwych recenzjach |
| Recipe | Pełna karta przepisów | Perplexity, AI Mode | Serwisy kulinarne |
| Event | Karuzela wydarzeń | AI Mode | Serwisy eventowe |
| VideoObject | Miniatura wideo | AI Mode | Gdy wideo jest kluczowe |
| Service | Brak widocznego | AI Mode | Opcjonalnie, tylko AI grounding |
Co AI Overviews myli w temacie schematu
Warto powiedzieć wprost, bo narracja w 2025 r. odpłynęła. Gorąca teza brzmi „AI Overviews opiera się wyłącznie na schemacie, więc dodaj każdy typ”. Rzeczywistość jest spokojniejsza. AI Overviews i AI Mode korzystają ze schematu do rozróżniania encji i pobierania pól, ale decyzję o cytacie napędza głównie jakość retrievu (czy strona odpowiada na zapytanie) i sygnały autorytetu.
Empiryczne badania z Tech SEO Connect 2025 mówią to samo: dane strukturalne są konieczne, lecz niewystarczające. Strony z czystym schematem, ale cienką treścią nie są cytowane. Strony z mocną treścią, ale bez schematu są cytowane, ale z ubogimi metadanymi (brak autora, daty, ceny). Wygrywa kombinacja.
Drugi mit: że LLM-y skrobią JSON-LD bezpośrednio. Większość nie; robi to warstwa retrievu i ugruntowania przed modelem. Tam parser czyta schemat, wyciąga pola i podaje je modelowi jako kontekst. Gdy schemat jest zepsuty, model nie ma do czego wrócić – parser nie nadrabia.
W skrócie: implementuj schemat dla warstwy retrievu, nie dla samego modelu. Waliduj agresywnie, utrzymuj spójne @id, oprzyj się pokusie oznaczania wszystkiego tylko dlatego, że schema.org ma taki typ.
Co faktycznie zrobić w tym kwartale
Cztery kroki. Żaden nie wymaga dostawcy ani przebudowy.
Po pierwsze, audyt. Puść Rich Results Test na dziesięć stron z największym ruchem. Zapisz, jakie typy są obecne, które przechodzą walidację, które dają rich-result. Znajdziesz przynajmniej jeden stary typ z zaleceń 2018 r.
Po drugie, przytnij. Usuń FAQPage i HowTo z miejsc, gdzie treść nie jest prawdziwym FAQ ani instrukcją. Usuń bloki Service bez realnej Offer. Usuń Review/AggregateRating, gdy recenzentem jesteś Ty sam.
Po trzecie, dodaj kręgosłup encji. Wstaw globalny blok JSON-LD Organization w
z logo, sameAs, founder, address. Dodaj BreadcrumbList na każdej podstronie. Generator schematu SEOJuice tworzy zweryfikowany JSON-LD, który możesz wkleić w szablony, gdy stawiasz Organization i Article na wielu stronach.Po czwarte, pomiar. Śledź pojawianie się cytatów AI narzędziem, które zbiera Perplexity, ChatGPT i AI Mode dla zapytań brandowych i top-produktów. Dane „przed i po” pokażą, czy praca nad schematem się zwróciła.

Lektura uzupełniająca. Jak sprawić, by Twoja marka pojawiała się w ChatGPT, Perplexity i Google AI o cytowaniu marki; optymalizacja pod Perplexity, ChatGPT search i Google AI Mode o kształcie treści. Ten materiał to szyna schematu.
Czego schema dla Ciebie nie zrobi
Szczere zakończenie. Schema nie jest czynnikiem rankingowym wprost. Google mówi to jasno od 2019 r. Dodanie Product schema do słabej strony produktu nie przebije konkurenta z bogatszą treścią. Dodanie Article schema do posta bez linków i sygnałów E-E-A-T nie wrzuci go do Top Stories. Schema nie tworzy autorytetu; wyraża autorytet już obecny w formacie czytelnym dla maszyn.
Co schema robi, to rozróżnianie. Gdy dwie strony celują w to samo zapytanie, a jedna ma czyste Organization + Article, to ona jest łatwiejszym celem cytatu. Gdy panel wiedzy decyduje, które „Acme” jest wyszukiwane, wygrywa Organization z sameAs do Wikidata. Gdy AI Mode ugruntowuje rozmowę zakupową, Product z valid Offers jest źródłem.
To kontrakt na 2026 r. Schema nie wypycha Cię w rankingach. Sprawia, że jesteś czytelny, gdy silnik AI decyduje, kogo zacytować, i pokazuje Twoje pola, gdy cytat się wyświetla. Sześć–siedem typów realizuje ten kontrakt dla większości stron. Reszta jest opcjonalna wertykalnie, opcjonalna dla AI grounding albo reliktem ery formatów SERP zakończonej w sierpniu 2023 r.
FAQ
Czy schema to czynnik rankingowy w 2026 r.? Nie, bezpośrednio nie. Dane strukturalne pomagają Google zrozumieć treść, ale nie dają ogólnego boostu. Wpływają natomiast na rich-results i pojawianie się cytatów AI. Oba są ważne, żadne nie jest klasycznym „rankingiem”.
Czy nadal implementować FAQ schema mimo deprecjacji rich-result? Tylko gdy treść FAQ jest naprawdę użyteczna. Wynik Google zniknął dla niereżimowych i niezwiązanych ze zdrowiem stron, ale AI Mode i Perplexity wciąż parsują FAQPage do retrievu. Nie twórz FAQ na siłę dla schematu; oznaczaj tam, gdzie są prawdziwe pytania.
JSON-LD czy Microdata w 2026? JSON-LD. Microdata wciąż się waliduje i Google ją czyta, ale parsery AI są strojone na JSON-LD w
. Nowe prace rób w JSON-LD; stara, czysta Microdata może zostać.Minimalny zestaw schematu dla SaaS lub serwisu? Organization (site-wide w
), BreadcrumbList (każda podstrona), Article (każdy blog/editorial). Dodaj Product lub LocalBusiness, jeśli pasuje do modelu biznesowego.Czy Google karze strony z nadmiarem schematu? Nie za kompletność, ale tak za wprowadzający w błąd lub samoobsługowy schemat. Dane strukturalne sprzeczne z treścią mogą wywołać ręczną karę „misleading structured data”. Samoocenne Review/AggregateRating są cicho filtrowane. Kryterium to „poprawne i uczciwe”, nie „minimalne”.
Read More
- Knowledge-Based Trust SEO: model audytu faktograficznego, a nie sztuczka rankingowa
- Przewodnik po Domain Authority
- Nofollow kontra Dofollow: Dlaczego stary binarny podział przestał działać
- Jak zautomatyzować linkowanie wewnętrzne w serwisie liczącym 50 stron, nie naruszając przy tym mapy tematycznej
- Statystyki SEO 2026: Czego się nauczyliśmy, skanując internet
- Wdrożyłeś swoją stronę i nie ma jej w Google. Oto dlaczego.
no credit card required
No related articles found.