Analisi dei file di log per la SEO
TL;DR: Google Search Console ti dice cosa Google vuole che tu veda. I log del server ti dicono cosa ha fatto davvero Googlebot. Ho scoperto che Googlebot stava spendendo il 73% del budget di scansione su URL con parametri che avevamo dimenticato di esistere. In GSC non risultava nulla di anomalo. Ecco come impostare l’analisi dei log, cosa controllare e perché è la tecnica di technical SEO meno usata.
GSC mente per omissione
Google Search Console è uno strumento fantastico. Lo uso ogni giorno. Ma ha un problema di fondo: ti mostra solo ciò che Google ha deciso di riportare.
Le statistiche di scansione di GSC ti danno numeri aggregati — richieste totali, tempo medio di risposta, alcuni codici di stato. Quello che non ti dice è quali URL specifici Googlebot ha colpito, in che ordine, quanto è durata ogni richiesta, se Googlebot è tornato per un secondo passaggio per eseguire JavaScript, oppure quali sezioni del tuo sito sta ignorando completamente.
Ed ecco il vuoto. Un vuoto enorme.
I log del server sono la verità senza filtri. Ogni richiesta che Googlebot fa al tuo server viene registrata con timestamp, URL esatto, codice di stato, tempo di risposta e stringa dello user agent. Niente riassunti, niente campionamenti, niente decisioni da parte di Google su cosa devi sapere. Dati grezzi.
Su una cosa sarò schietto: per i primi due anni di attività di SEOJuice ho ignorato l’analisi dei log. Mi sembrava roba che facevano solo gli SEOs enterprise, con contratti Botify da sei cifre. Avevo torto. Nel momento in cui ho iniziato a leggere e analizzare i nostri log Nginx, ho trovato problemi che GSC teneva nascosti da mesi. Sprechi di crawl budget su URL sfaccettati. Errori 5xx che si manifestavano solo seguendo i pattern di scansione di Googlebot. Nuovi post del blog che Googlebot non visitava da tre settimane.
In base a quanto ho visto su centinaia di siti: per esperienza, quasi ogni sito con più di 500 pagine ha almeno un problema di crawl significativo che solo l’analisi dei log può rivelare.
Cosa contiene davvero un server log
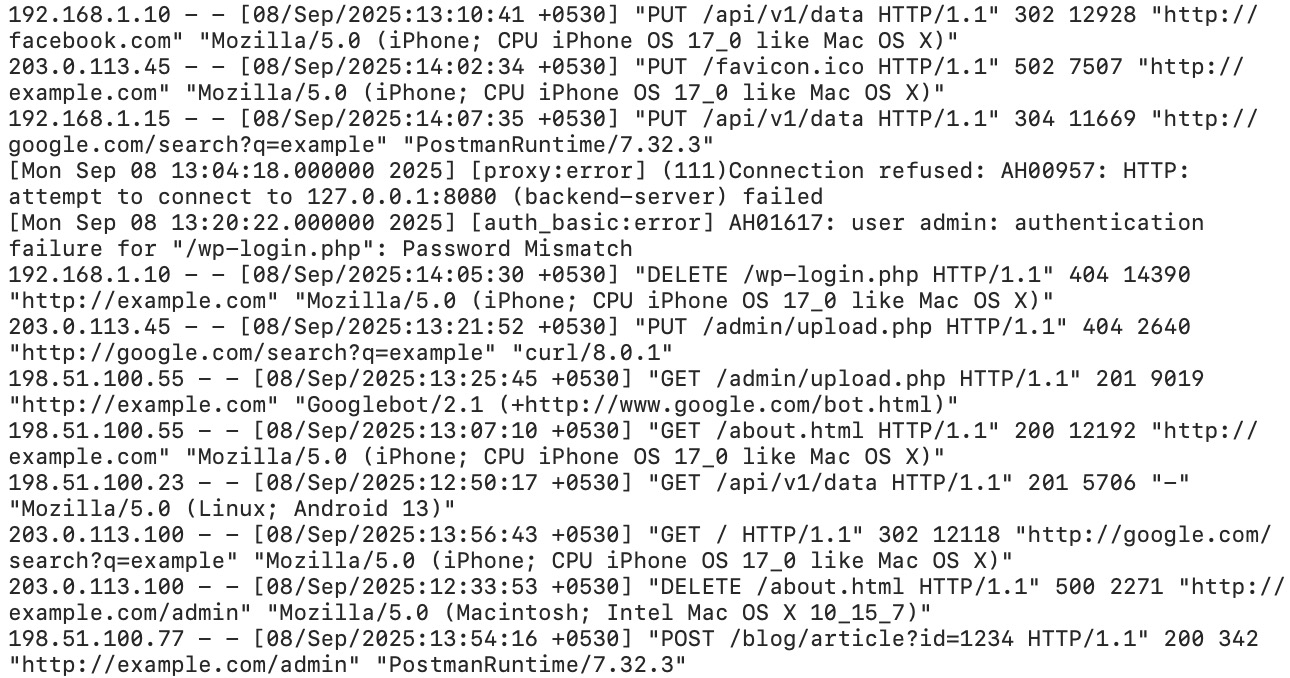
Spacchiamolo:
| Campo | Valore | Cosa significa |
|---|---|---|
| Indirizzo IP | 66.249.79.45 | IP di Googlebot (il range 66.249.x.x è Google) |
| Timestamp | [15/Mar/2026:09:23:17 +0000] | Ora esatta della richiesta |
| Richiesta | GET /blog/content-decay-guide/ HTTP/2.0 | Quale URL è stato scansionato |
| Codice di stato | 200 | Risposta del server (200 = OK) |
| Byte inviati | 34521 | Dimensione della risposta in byte |
| Referer | - | Da dove arriva la richiesta (di solito vuoto per i bot) |
| User Agent | Googlebot/2.1 | Identifica il crawler |
| Tempo di risposta | 0.142 | 142ms per servire la pagina |
Server web diversi usano formati leggermente differenti. Il “Combined Log Format” di Apache è quasi identico a quello di Nginx. IIS usa un formato esteso W3C con campi separati da spazio e una riga di intestazione che definisce le colonne. I dati sono gli stessi — cambia solo l’organizzazione.
I campi critici per la SEO sono: user agent (per filtrare i bot), URL (per capire cosa viene scansionato), codice di stato (per individuare gli errori) e tempo di risposta (per trovare colli di bottiglia di performance).
User agent che devi conoscere
Non tutte le richieste di Googlebot sono uguali. Google usa user agent diversi per scopi diversi, e saperle distinguere conta.
| Stringa User Agent | Che cosa fa | Perché conta |
|---|---|---|
Googlebot/2.1 | Crawler web principale | È lo scan principale — le tue pagine core |
Googlebot-Image/1.0 | Crawler immagini | Scansiona le immagini per l’indice Google Immagini |
Googlebot-Video/1.0 | Crawler video | Scopre e indicizza contenuti video |
Googlebot-News | Crawler News | Ha senso solo se sei su Google News |
APIs-Google | Fetch AMP/API | Recupera pagine AMP e contenuti speciali |
Chrome/W.X.Y.Z (con Googlebot) | Rendering bot | Questo è quello grande. Quando vedi un Chrome UA insieme a Googlebot, è il Web Rendering Service — Google che esegue il tuo JavaScript |
Il rendering bot è particolarmente importante. Quando Googlebot scansiona per la prima volta una pagina, riceve l’HTML grezzo. Se la pagina usa JavaScript, Google accoda una seconda richiesta tramite il suo Web Rendering Service (WRS), che usa un browser Chrome headless. Questa seconda richiesta compare nei tuoi log con una stringa user agent da Chrome.
Se vedi il primo hit di Googlebot ma non mai il passaggio di rendering Chrome su pagine ricche di JS, probabilmente Google non sta vedendo tutto il tuo contenuto. In GSC non lo vedi. Lo rivela solo l’analisi dei log.
Impostare i log per l’analisi SEO
La maggior parte delle configurazioni predefinite di Nginx e Apache registra abbastanza dati per un’analisi di base. Ma “di base” non basta. Ti serve il tempo di risposta, e la maggior parte dei default non lo include.
Ecco il formato di log Nginx che uso. Aggiungilo al tuo blocco http in nginx.conf:
log_format seo_analysis '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$request_time $upstream_response_time';
access_log /var/log/nginx/access.log seo_analysis;Le due aggiunte che contano: $request_time (tempo totale dalla richiesta alla risposta) e $upstream_response_time (quanto ha impiegato il tuo application server, escludendo l’overhead di Nginx). La differenza tra questi due valori ti dice se il collo di bottiglia è la tua app o lo strato proxy.
Per Apache, aggiungi %D (tempo di richiesta in microsecondi) alla direttiva LogFormat:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" seo_combined
CustomLog /var/log/apache2/access.log seo_combinedIl problema della CDN
Ecco dove diventa fastidioso. Se sei dietro Cloudflare, Bunny CDN, Fastly o qualsiasi altra CDN, i log del tuo origin server mostrano solo le richieste che passano la cache. Una pagina perfettamente in cache può essere scansionata 50 volte da Googlebot, ma il tuo origin non vedrà nessuna di quelle richieste.
Ti servono log a livello CDN:
- Cloudflare: il piano Enterprise include il Logpush completo su S3, R2 o Datadog. I piani Business e Pro ottengono log campionati via dashboard. Piano Free — sei nei guai.
- Bunny CDN: log raw disponibili su tutti i piani. Download via API o dashboard. È anche per questo che mi piace Bunny.
- Fastly: streaming dei log in tempo reale verso un endpoint tuo. Flessibile, ma richiede configurazione.
- AWS CloudFront: log standard e real-time su S3. Semplice da abilitare.
Se la tua CDN non offre log a livello bot nel piano che hai, puoi impostare una regola per bypassare la cache per user agent dei bot noti. In questo modo le richieste dei bot colpiscono l’origin, dove puoi registrarle. Lo scambio è un carico leggermente maggiore sull’origin durante le scansioni.
Non sono del tutto sicuro che per i siti piccoli valga lo scambio. Se ricevi 200 richieste di Googlebot al giorno, il carico sull’origin dovuto al bypass è trascurabile. Se ne ricevi 200.000, fermati un attimo e valuta con attenzione la tua infrastruttura prima di attivare quella leva.
Rotazione e storage dei log
I log diventano grandi in fretta. Un sito con 10.000 visite al giorno genera circa 2-5 MB di log di accesso al giorno. Su un anno sono 700 MB-1,8 GB non compressi. Gzip, forse 50-100 MB.
Per l’analisi SEO vuoi almeno 90 giorni di log. Idealmente 6 mesi, così puoi vedere pattern stagionali di crawl e correlare con gli aggiornamenti dell’algoritmo. Imposta logrotate (Linux) o una job cron per comprimere e archiviare i log ogni settimana. Elimina tutto ciò che è più vecchio di 6 mesi a meno che tu non abbia una ragione specifica per tenerlo.
Analizzare i log con Python: una guida pratica
Dedico questa sezione a Hamlet Batista, scomparso di recente, che ha pionierizzato l’uso di Python per l’analisi e l’automazione dei log SEO. Hamlet è morto nel 2020, ma il suo lavoro — soprattutto la sua scrittura sull’uso di Python e dei notebook Jupyter per la technical SEO — ha cambiato in modo fondamentale il modo in cui il nostro settore affronta i problemi legati ai dati. Gran parte di ciò che segue costruisce sulle intuizioni che lui ha insegnato alla community SEO.
Ecco uno script Python di base che filtra i log Nginx per le richieste di Googlebot e genera le metriche che contano davvero per la SEO. È molto simile a quello che ho usato contro i log di SEOJuice.com.
import re
import csv
from collections import Counter, defaultdict
from datetime import datetime
LOG_PATTERN = re.compile(
r'(?P<ip>\S+) \S+ \S+ '
r'\[(?P<timestamp>[^\]]+)\] '
r'"(?P<method>\S+) (?P<url>\S+) \S+" '
r'(?P<status>\d{3}) (?P<size>\d+) '
r'"[^"]*" "(?P<ua>[^"]*)" '
r'(?P<response_time>[\d.]+)?'
)
GOOGLEBOT_PATTERN = re.compile(r'Googlebot|Google-InspectionTool', re.IGNORECASE)
def parse_log(filepath):
"""Analizza il log Nginx, restituisce solo le richieste di Googlebot."""
results = []
with open(filepath, 'r') as f:
for line in f:
match = LOG_PATTERN.match(line)
if not match:
continue
if not GOOGLEBOT_PATTERN.search(match.group('ua')):
continue
results.append({
'ip': match.group('ip'),
'timestamp': match.group('timestamp'),
'url': match.group('url'),
'status': int(match.group('status')),
'size': int(match.group('size')),
'ua': match.group('ua'),
'response_time': float(match.group('response_time') or 0),
})
return results
def analyze(requests):
"""Genera metriche rilevanti per la SEO dalle richieste di Googlebot."""
url_counts = Counter(r['url'] for r in requests)
status_counts = Counter(r['status'] for r in requests)
slow_urls = [
(r['url'], r['response_time'])
for r in requests if r['response_time'] > 1.0
]
# Distribuzione del crawl per sezione
section_counts = Counter()
for r in requests:
parts = r['url'].strip('/').split('/')
section = parts[0] if parts and parts[0] else '(root)'
section_counts[section] += 1
print(f"Totale richieste Googlebot: {len(requests)}")
print(f"\n--- Distribuzione per codice di stato ---")
for code, count in status_counts.most_common():
pct = (count / len(requests)) * 100
print(f" {code}: {count} ({pct:.1f}%)")
print(f"\n--- Top 20 URL più scansionati ---")
for url, count in url_counts.most_common(20):
print(f" {count:>5}x {url}")
print(f"\n--- Distribuzione del crawl per sezione ---")
total = len(requests)
for section, count in section_counts.most_common(10):
pct = (count / total) * 100
print(f" /{section}/: {count} ({pct:.1f}%)")
print(f"\n--- Risposte lente (>1s) ---")
for url, time in sorted(slow_urls, key=lambda x: -x[1])[:10]:
print(f" {time:.2f}s {url}")
if __name__ == '__main__':
requests = parse_log('/var/log/nginx/access.log')
analyze(requests)Sono forse 60 righe di codice. Mi ci sono voluti 20 minuti per scriverlo. E l’output mi ha subito mostrato che Googlebot stava martellando la nostra sezione /tools/ (il 73% di tutte le richieste di crawl) senza quasi toccare i nuovi post del blog. Questo spiegava perché i nostri nuovi contenuti non venivano indicizzati da settimane.
Per siti più grandi o per monitoraggio continuo, serve qualcosa di più robusto. Lo stack ELK (Elasticsearch, Logstash, Kibana) è lo standard del settore per aggregare i log su larga scala. Logstash li acquisisce e li analizza, Elasticsearch li indicizza per query veloci e Kibana ti fornisce dashboard. È potente, ma non banale da impostare — metti in budget almeno un giorno o due per la configurazione iniziale.
Le sei metriche che contano davvero

La sezione /tools/ aveva decine di combinazioni di parametri (filtri, opzioni di ordinamento, paginazione) che generavano migliaia di URL scansionabili. Googlebot li stava scansionando tutti. Nel frattempo, il nostro blog — la sezione che guida davvero il traffico organico — riceveva solo l’11% dell’attenzione di crawl.
La correzione è stata una combinazione di tag canonical, regole robots.txt e noindex sulle varianti con parametri. Abbiamo anche ristrutturato il linking interno per rispecchiare meglio i nostri content silo. In due settimane, la frequenza di crawl del blog è raddoppiata. I nuovi post hanno iniziato a essere indicizzati entro pochi giorni, invece che settimane.
Questa cosa non la vedi in GSC. GSC ti mostra le richieste di crawl totali. Non le spezza per sezione e non evidenzia il problema di distribuzione.
2. Distribuzione dei codici di stato
Aggrega i tuoi codici di stato su tutte le richieste di Googlebot. Ecco come dovrebbe apparire un sistema sano:
- 200 (OK): dovrebbe essere l’85-95% di tutte le richieste
- 301/302 (Redirect): sotto il 10%. Se è più alto, hai catene di redirect o URL legacy ancora in crawl
- 304 (Non Modified): normale, significa che Googlebot ha controllato e la pagina non era cambiata
- 404 (Not Found): sotto il 5%. Se è più alto, stai sprecando crawl budget su pagine morte
- 500/503 (Errori server): dovrebbe essere vicino allo zero. Qualsiasi picco qui è un’emergenza
Una volta ho visto un sito in cui il 22% delle richieste di Googlebot tornava 404. Il developer precedente aveva rimosso una categoria prodotto senza fare redirect. Googlebot aveva quei URL in coda di crawl e continuava a riprovarli. Il 22% del crawl budget, bruciato su pagine che non esistevano. Per otto mesi.
3. Tempo di risposta per URL
Google ha detto ripetutamente che la velocità della pagina è un fattore di ranking. Ma i Core Web Vitals (quelli che GSC riporta) misurano la performance lato client. Il tempo di risposta del server — quanto impiega il tuo server a generare e inviare l’HTML — è un’altra cosa, e si vede solo nei log.
Cosa cercare: qualsiasi URL in cui il tempo di risposta supera 500ms in modo costante. Sopra 1 secondo è un problema. Sopra 2 secondi e Googlebot potrebbe abbandonare la richiesta del tutto.
Ordina le richieste di Googlebot per tempo di risposta, in ordine decrescente. Gli URL più lenti di solito rientrano in poche categorie: pagine pesanti a livello database (listing prodotti con filtri complessi), pagine che fanno chiamate a API esterne durante il rendering, oppure pagine che generano risposte grandi (sitemap, feed).
4. Pattern di profondità di crawl
Quanti click dalla homepage servono a Googlebot per arrivare a una pagina? Questo non è direttamente nei log, ma puoi dedurlo guardando timestamp e pattern di referral.
Se Googlebot colpisce la homepage alle 09:00, le pagine di categoria principali alle 09:01 e una pagina prodotto profonda alle 09:14 — quel gap di 14 minuti suggerisce che la pagina è annidata profondamente. Le pagine che Googlebot scopre tardi durante una sessione di crawl ricevono meno attenzione.
Approccio più semplice: confronta l’insieme di URL che Googlebot ha scansionato con la tua sitemap completa. Ogni URL presente nella sitemap che Googlebot non ha visitato da 30+ giorni, dal punto di vista di Google, è di fatto orfano, a prescindere da cosa dice il linking interno.
5. Rapporto traffico bot vs. umano
È una metrica di sicurezza e performance tanto quanto una metrica SEO. Filtra i log per user agent e calcola quale percentuale del totale delle richieste arriva da bot rispetto agli utenti reali.
Su molti siti, i bot rappresentano il 30-50% di tutte le richieste. Se i bot arrivano all’80%+ sei probabilmente sotto scraping o colpito da bad bot che stanno sprecando risorse del server. Se Googlebot nello specifico rappresenta meno del 5% del traffico bot, allora qualcosa sta consumando la capacità del server e potenzialmente rallentando la capacità di Google di scansionarti.
6. Pagine orfane — quelle che Googlebot non visita mai
Questa può essere l’analisi più utile che puoi fare. Prendi la lista degli URL nella tua sitemap o nel tuo CMS. Confrontala con la lista di URL che Googlebot ha visitato negli ultimi 90 giorni. Qualsiasi URL che Googlebot non tocca è di fatto invisibile.
Casi comuni: la pagina non ha link interni che puntano ad essa (un vero orfano), la pagina è troppo profonda nella struttura del sito, oppure la pagina è bloccata da una regola robots.txt che ti sei dimenticato di considerare.
Non sono sinceramente sicuro del perché molti SEOs non facciano questa analisi in modo regolare. Richiede 10 minuti con lo script Python sopra e una lista dei tuoi URL. Ogni volta che l’ho eseguita per un cliente, abbiamo trovato pagine che dovevano essere importanti ma non venivano scansionate da mesi.
Pattern reali che dovrebbero metterti in allarme
La teoria è carina. Ecco i problemi reali che ho scoperto attraverso l’analisi dei log su siti esistenti, problemi che altrimenti sarebbero rimasti invisibili.
La trappola degli URL con parametri
Ne ho già parlato: esperienza diretta. Ma vale la pena ribadirlo: la navigazione sfaccettata, i parametri di ricerca, gli ordini di sorting e la paginazione creano un numero esponenziale di URL scansionabili. Un catalogo prodotti con 500 prodotti, 8 categorie di filtro e 3 opzioni di ordinamento può generare decine di migliaia di URL. Googlebot cercherà di scansionarli tutti.
Secondo la ricerca sul crawl budget pubblicata da Botify (2023), su grandi siti e-commerce, fino all’80% del crawl budget di Googlebot può essere consumato da URL con parametri che offrono contenuti quasi identici — anche se il valore esatto varia molto in base al tipo di sito e alla sua architettura. Il loro CTO, Adrien Menard, ha scritto ampiamente su questo: il problema del crawl budget sui siti grandi non è convincere Google a scansionare di più — è impedire che sprechi crawl su URL a basso valore.
Il problema 5xx silenzioso
Un cliente aveva errori 503 intermittenti che comparivano solo durante i picchi di crawl di Googlebot. Il loro monitoraggio (Pingdom, UptimeRobot) mostrava un uptime del 99,9% perché questi strumenti controllano una volta al minuto da una singola posizione. Googlebot colpisce 10-50 pagine in rapida successione. Il server non riusciva a reggere quel burst, mandava 503 su circa il 15% delle richieste di Googlebot e rientrava in pochi secondi.
Le statistiche di crawl di GSC mostravano un tasso di errore leggermente elevato. I log raccontavano la storia completa: ogni giorno tra le 2:00 e le 3:00 UTC (quando Googlebot tende a colpire proprio quel sito), il server falliva sotto carico. Sistemarlo ha richiesto tuning dei worker di PHP-FPM e pooling delle connessioni al database. Costo totale: due ore di lavoro DevOps. I miglioramenti di ranking sono comparsi entro tre settimane.
Nuovi contenuti che passano inosservati
Abbiamo pubblicato una guida dettagliata. Tre settimane dopo non era ancora indicizzata. GSC mostrava l’URL come “Discovered — currently not indexed.” Utile.
Nei log invece si vedeva la verità: Googlebot non aveva mai richiesto quell’URL. Mai. La pagina era linkata da una pagina di archivio tag che, a sua volta, era stata scansionata solo due volte in 60 giorni. Googlebot semplicemente non aveva ancora seguito quel link.
La soluzione è stata aggiungere un link interno da una pagina scansionata frequentemente (la sidebar della homepage). Googlebot ha colpito la nuova pagina entro 48 ore. Indicizzata entro una settimana. È esattamente il tipo di problema che un post-launch SEO checklist dovrebbe intercettare prima che diventi un guaio.
Spreco di rendering budget
Un cliente SaaS aveva un sito marketing costruito con Next.js. SSR era abilitato — bene. Ma nei log è emerso qualcosa di strano: il rendering bot di Chrome di Googlebot faceva un secondo passaggio su ogni singola pagina, inclusi i semplici static pages che non avevano contenuti dinamici lato client.
Il problema era uno script di analytics lato client che modificava il DOM dopo il caricamento della pagina. Googlebot vedeva l’HTML iniziale, poi tornava a renderizzare il JavaScript e vedeva contenuti diversi (gli elementi iniettati dall’analytics). Quindi continuava a fare re-rendering per essere sicuro di avere la versione finale. Stava consumando rendering budget su pagine a cui non serviva.
La soluzione: spostare lo script analytics per caricare dopo l’evento DOMContentLoaded con un attributo defer, assicurandosi che non modificasse elementi visibili del DOM. Le richieste di rendering sono scese del 60%.
Strumenti per l’analisi dei log

Botify — Enterprise-grade. Acquisisce log su larga scala, li correla con dati di crawl e Search Console, e costruisce dashboard automaticamente. Se gestisci un sito con milioni di pagine, probabilmente vale l’investimento. Per siti sotto 100k pagine è sovradimensionato. I prezzi erano nell’ordine delle centinaia al mese l’ultima volta che ho controllato (a metà 2025), anche se i dettagli sono poco trasparenti e devo dire che ho sentimenti misti a riguardo.
JetOctopus — Un buon compromesso. Analisi dei log cloud con una visualizzazione valida. Gestisce file di log grandi, si integra con GSC e costa molto meno di Botify. L’ho consigliato spesso ad agenzie che gestiscono più siti mid-size.
Python personalizzato + ELK — Se sei tecnico e vuoi il controllo totale, lo script sopra è un buon punto di partenza. Per monitoraggio continuo, fai confluire i log nello stack ELK (Elasticsearch, Logstash, Kibana). Logstash analizza i log con pattern grok, Elasticsearch li salva e li indicizza, Kibana ti offre dashboard in tempo reale. La configurazione richiede un giorno. Il costo continuativo è solo il server — magari $20-$50 al mese su un piccolo VPS.
GoAccess — Un analizzatore leggero basato su terminale che genera report HTML. Non è specifico per SEO, ma sorprendentemente utile per avere un’overview rapida dell’attività dei bot e della distribuzione dei codici di stato. Gratis, veloce, funziona su qualsiasi server. Buono per il caso “voglio controllare qualcosa al volo”.
Quello che ho imparato analizzando i log di SEOJuice.com
Momento di trasparenza. Ecco cosa ho scoperto quando ho eseguito per la prima volta una vera analisi dei log sul nostro sito a fine 2025.
Scoperta 1: spreco del crawl budget sulle pagine dei tool. I nostri tool SEO gratuiti (site audit, domain authority checker, keyword extractor, ecc.) generano URL unici per ogni analisi. Ogni risultato di tool aveva un URL dedicato. Googlebot li stava scansionando a migliaia. Erano perlopiù pagine sottili e temporanee che non avevano bisogno di stare in indice. Abbiamo aggiunto noindex alle pagine dei risultati dei tool e in due settimane il crawl rate del blog è aumentato.
Scoperta 2: pagine lente che dipendono da API. La nostra pagina prezzi faceva una chiamata real-time all’API di Paddle per recuperare i prezzi aggiornati. Tempo di risposta mediano: 1,8 secondi. Googlebot ci aspettava. Abbiamo cambiato approccio: caching dei dati dei prezzi con un TTL di 1 ora. Il tempo di risposta è sceso a 90ms.
Scoperta 3: catene di redirect 301. Dopo una ristrutturazione degli URL, avevamo catene tipo /old-url → /medium-url → /final-url. Il 12% delle richieste di Googlebot seguiva i redirect. Ogni salto è una richiesta sprecata. Abbiamo appiattito tutte le catene in redirect a singolo hop nella nostra configurazione Nginx.
Scoperta 4: crawl di CSS e JS. Mi ha sorpreso. Circa il 30% delle richieste di Googlebot erano per asset statici — file CSS, bundle JavaScript, font. Sono necessari per il rendering, ma questo significava che solo il 70% del nostro crawl budget stava andando a pagine con contenuto reale. Non potevamo eliminarlo (Google ha bisogno di quei file per renderizzare le pagine), ma ha cambiato il modo in cui ragionavamo sul nostro crawl budget complessivo.
Risultato finale: dopo aver affrontato le scoperte 1-3, i contenuti del nostro blog venivano indicizzati 3-4 volte più velocemente. I nuovi post sono passati da “scoperti ma non indicizzati per 2-3 settimane” a “indicizzati entro 3-5 giorni”. Tutto grazie a insight dell’analisi dei log che GSC non aveva mai evidenziato.
Come l’analytics del crawler di SEOJuice aiuta
Ho costruito la funzione di crawler analytics in SEOJuice apposta perché ero stanco di dover parsare log grezzi. Ti dà le stesse intuizioni senza il lavoro da command-line.
L’analytics del crawler di SEOJuice monitora l’attività di Googlebot sul tuo sito e mette in evidenza:
- Frequenza di crawl per pagina e sezione — vedi esattamente dove Google sta spendendo il crawl budget
- Distribuzione dei codici di stato nel tempo — intercetta picchi di errori prima che impattino i ranking
- Trend dei tempi di risposta — individua le pagine che stanno rallentando Googlebot
- Pagine non crawlate — pagine nella tua sitemap che Googlebot non ha visitato
- Attività di rendering — quali pagine innescano un secondo passaggio tramite la WRS di Google
Non sostituisce l’analisi dei log grezzi per ogni scenario. Se devi fare debug di una specifica configurazione Nginx o indagare il comportamento bot a livello IP, hai ancora bisogno dei log raw. Ma per il 90% dei casi in cui vuoi solo sapere “Googlebot sta crawlando le cose giuste?” — è molto più veloce che scrivere script Python.
Prova SEOJuice gratis e collega il tuo sito per vedere l’analytics del crawler in azione. Nessuna carta di credito richiesta.
Un processo semplice di audit mensile dei log
Non devi fissare i log ogni giorno. Ecco la routine mensile che seguo:
- Scarica o interroga gli ultimi 30 giorni di log (oppure controlla la dashboard dello strumento di analisi log).
- Controlla la distribuzione dei codici di stato. Aumenti in 4xx o 5xx? Indaga subito.
- Confronta la distribuzione del crawl con la distribuzione dei contenuti. Google sta crawlando, in proporzione, le sezioni che ti interessano?
- Trova gli URL non crawlati. Incrocia la tua sitemap con gli URL crawlati. Qualsiasi cosa non crawlata da 30+ giorni ottiene un link interno da una pagina ad alto crawl.
- Controlla i tempi di risposta. Spuntano nuove pagine nel bucket >1s? Correggile prima che diventino problemi di ranking.
- Guarda le richieste di rendering. Se aumentano senza nuove pagine ricche di JS, qualcosa è cambiato nel tuo frontend.
Tempo totale: 30-45 minuti. Il ROI è sproporzionato.
Domande frequenti
Quanto deve essere grande il mio sito perché l’analisi dei log serva davvero?
Non l’ho testata in modo esaustivo su ogni nicchia, ma non c’è un minimo rigido — il valore cresce con la dimensione del sito. Sotto 100 pagine, Googlebot scansiona tutto comunque e non è probabile avere problemi di crawl budget. Tra 500 e 5.000 pagine è dove inizia a diventare davvero utile. Sopra 10.000 pagine è fondamentale — lo spreco di crawl budget è quasi garantito su siti di quelle dimensioni. Detto questo, anche un sito da 200 pagine può beneficiare se stai vedendo ritardi nell’indicizzazione o cali di ranking misteriosi.
Posso verificare che una richiesta sia davvero di Googlebot e non di un finto?
Sì. Google pubblica i suoi range IP e puoi fare una reverse DNS lookup sull’IP della richiesta. Gli IP di Googlebot reali risolvono a *.googlebot.com o *.google.com. In Python: import socket; socket.gethostbyaddr('66.249.79.45'). Qualsiasi IP che non risolve verso un dominio Google è un finto Googlebot — probabilmente uno scraper che usa la stringa user agent di Googlebot. La documentazione ufficiale di Google raccomanda questo metodo di verifica.
Con che frequenza Googlebot scansiona un sito tipico?
Varia tantissimo. Un sito news ad alta autorità può vedere migliaia di richieste di Googlebot all’ora. Un piccolo business può vederne 50-200 al giorno. La frequenza dipende da quanto Google percepisce l’importanza del tuo sito, da quanto spesso cambiano i contenuti, dalla velocità con cui risponde il tuo server e dalla freschezza della tua XML sitemap. Secondo l’analisi sulla frequenza di crawl di JetOctopus del 2024 sul loro customer base, la frequenza mediana di crawl per un sito da 5.000 pagine è circa 300-800 richieste di Googlebot al giorno.
Devo bloccare i bad bot nei miei log?
Blocca i bad bot a livello server (regole Nginx deny o fail2ban), non solo in robots.txt. robots.txt è un suggerimento — i bot malevoli lo ignorano. Ma attenzione: non bloccare per errore crawler legittimi. Ho visto siti che bloccavano tutti i bot con “bot” nella stringa user agent, intercettando anche Googlebot. Inserisci sempre in whitelist Google, Bing e qualsiasi altro motore di ricerca che ti interessa prima di implementare regole generiche di blocco bot.
Qual è la relazione tra analisi dei log e crawl budget?
L’analisi dei log è il modo con cui misuri il crawl budget. Google definisce crawl budget come combinazione del limite di crawl rate (quanto velocemente Google può scansionare senza sovraccaricare il tuo server) e della crawl demand (quanto Google vuole scansionare in base al valore percepito). Non puoi controllare direttamente nessuno dei due, ma puoi influenzarli: tempi di risposta più rapidi aumentano il crawl rate limit e rimuovere pagine a basso valore dalla coda di crawl di Google aumenta la proporzione di crawl budget spesa su pagine che contano. I log mostrano entrambi i lati di questa equazione.
L’analisi dei log non è glamour. È grep e regex e l’uso di script per far scorrere file di testo. Niente dashboard belle — a meno che tu non le costruisca. Ma è la cosa più vicina a vedere il tuo sito con gli occhi di Google. GSC ti mostra un riassunto curato. I log mostrano la verità grezza.
Se stai gestendo un sito con più di poche centinaia di pagine e non hai mai guardato i log del server, hai problemi di crawl che non sai di avere. Scommetterei soldi su questo.
Ulteriore lettura nella silo di Technical SEO:
Read More
- Ti presento SEOJuice — l’unico strumento AI di cui hai davvero bisogno
- Perché l’accessibilità conta e come migliora la SEO
- Strategie SEO economiche per le piccole imprese
- Checklist per scegliere un'agenzia SEO
- 10 motivi per cui la SEO manuale sta frenando la tua azienda
- Come eseguire un audit di visibilità con l’IA nel 2026
no credit card required