Protokolldatei-Analyse für SEO
TL;DR: Die Google Search Console zeigt dir, was Google von dir sehen lassen möchte. Server-Logs zeigen dir, was Googlebot tatsächlich gemacht hat. Ich habe festgestellt, dass Googlebot 73% seines Crawl-Budgets für Parameter-URLs ausgegeben hat, die wir längst vergessen hatten. In der GSC war nichts auffällig. So richtest du die Analyse von Logdateien ein, worauf du achten solltest und warum das die am stärksten unterschätzte Technik im technischen SEO ist.
GSC lügt durch Auslassung
Google Search Console ist ein tolles Tool. Ich nutze es täglich. Aber es gibt ein grundlegendes Problem: Es zeigt dir nur das, was Google sich entschieden hat zu melden.
Die Crawl-Statistiken in GSC liefern dir aggregierte Werte — insgesamt Requests, durchschnittliche Antwortzeit, ein paar Statuscodes. Was sie nicht zeigt, ist: Welche konkreten URLs Googlebot aufgerufen hat, in welcher Reihenfolge, wie lange jede Anfrage gedauert hat, ob Googlebot für einen zweiten Durchlauf zurückkommt, um JavaScript zu rendern, oder welche Bereiche deiner Website es komplett ignoriert.
Das ist die Lücke. Und sie ist riesig.
Server-Logs sind die ungefilterte Wahrheit. Jede Anfrage, die Googlebot an deinen Server stellt, wird mit Zeitstempel, exakter URL, Statuscode, Antwortzeit und User-Agent-String protokolliert. Keine Zusammenfassung, kein Sampling, keine Entscheidung von Google, was du angeblich wissen musst. Rohdaten.
Ich bin ehrlich mit etwas: In den ersten zwei Jahren, in denen ich SEOJuice betrieben habe, habe ich die Analyse von Logdateien ignoriert. Es fühlte sich an wie etwas, das nur Enterprise-SEOs mit sechsstelligen Botify-Verträgen machen. Ich lag falsch. Sobald ich angefangen habe, unsere eigenen Nginx-Logs auszuwerten, fand ich Probleme, die GSC seit Monaten versteckte. Crawl-Budgetverschwendung durch Facetten-URLs. 5xx-Fehler, die nur dann auftauchten, wenn Googlebot genau diese Crawl-Muster fuhr. Neue Blogbeiträge, die Googlebot seit drei Wochen nicht besucht hatte.
Basierend auf dem, was ich über Hunderte von Websites gesehen habe: In meiner Erfahrung hat nahezu jede Seite mit mehr als 500 URLs mindestens ein relevantes Crawl-Problem, das nur eine Loganalyse sichtbar macht.
Was ein Server-Log tatsächlich enthält
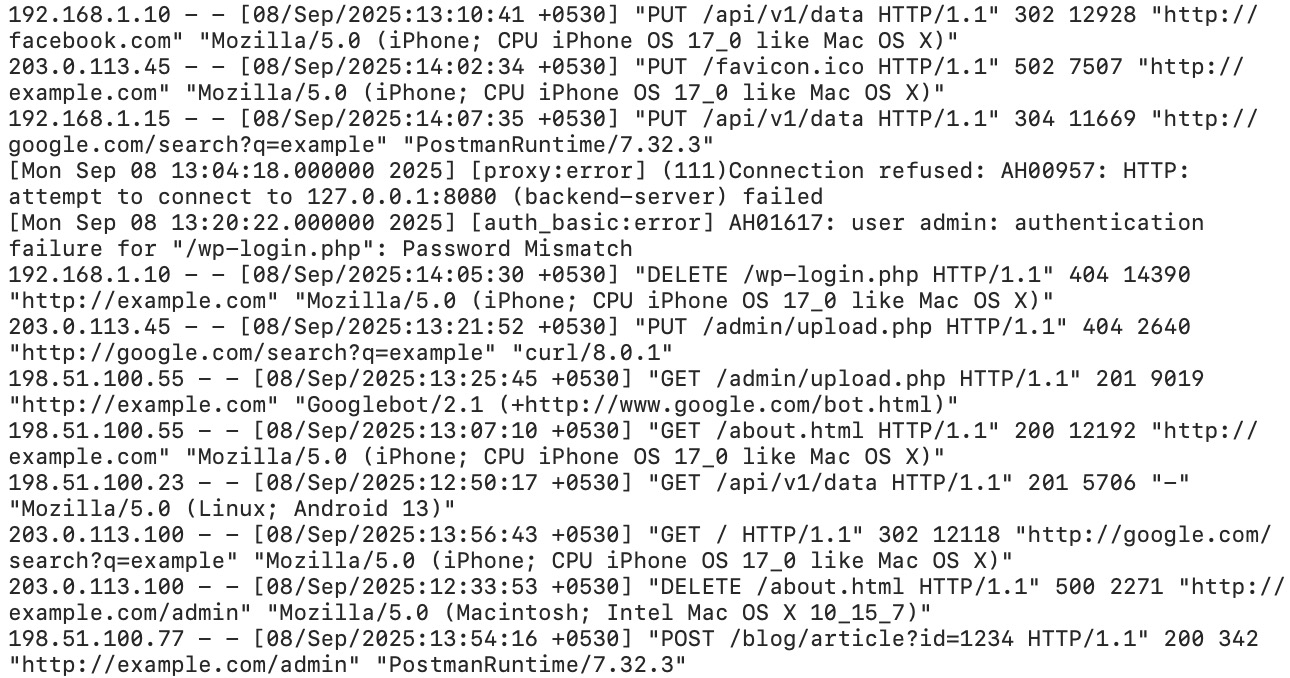
Lass uns das aufdröseln:
| Feld | Wert | Was es bedeutet |
|---|---|---|
| IP-Adresse | 66.249.79.45 | Die IP von Googlebot (der Bereich 66.249.x.x gehört zu Google) |
| Zeitstempel | [15/Mar/2026:09:23:17 +0000] | Exakter Zeitpunkt der Anfrage |
| Anfrage | GET /blog/content-decay-guide/ HTTP/2.0 | Welche URL gecrawlt wurde |
| Statuscode | 200 | Serverantwort (200 = OK) |
| Bytes gesendet | 34521 | Antwortgröße in Bytes |
| Referer | - | Woher die Anfrage kam (bei Bots meist leer) |
| User Agent | Googlebot/2.1 | Identifiziert den Crawler |
| Antwortzeit | 0.142 | 142ms, um die Seite auszuliefern |
Verschiedene Webserver verwenden leicht unterschiedliche Formate. Apache “Combined Log Format” ist fast identisch zu Nginx. IIS nutzt ein W3C-Extended-Format mit durch Leerzeichen getrennten Feldern und einer Header-Zeile, die die Spalten definiert. Die Daten sind dieselben — nur die Anordnung unterscheidet sich.
Für SEO sind die entscheidenden Felder: User Agent (zum Filtern für Bots), URL (um zu sehen, was gecrawlt wird), Statuscode (um Fehler zu finden) und Antwortzeit (um Performance-Engpässe aufzudecken).
User Agents, die du kennen solltest
Nicht jede Googlebot-Anfrage ist derselbe Crawler. Google verwendet unterschiedliche User Agents für verschiedene Zwecke, und das unterscheiden zu können, ist wichtig.
| User-Agent-String | Was er tut | Warum das wichtig ist |
|---|---|---|
Googlebot/2.1 | Primärer Webcrawler | Das ist der Haupt-Crawl — deine Kernseiten |
Googlebot-Image/1.0 | Image-Crawler | Crawlt Bilder für den Google Images-Index |
Googlebot-Video/1.0 | Video-Crawler | Entdeckt und indexiert Videoinhalte |
Googlebot-News | News-Crawler | Nur relevant, wenn du bei Google News gelistet bist |
APIs-Google | AMP/API-Fetcher | Ruft AMP-Seiten und speziellen Content ab |
Chrome/W.X.Y.Z (mit Googlebot) | Rendering-Bot | Das ist der große Brocken. Wenn du einen Chrome-UA neben Googlebot siehst, ist das der Web Rendering Service — Google führt dein JavaScript aus |
Der Rendering-Bot ist besonders wichtig. Wenn Googlebot eine Seite zum ersten Mal crawlt, bekommt er das rohe HTML. Wenn die Seite JavaScript enthält, legt Google eine zweite Anfrage über seinen Web Rendering Service (WRS) in die Warteschlange. Dabei kommt ein Headless-Chrome-Browser zum Einsatz. Diese zweite Anfrage taucht dann in deinen Logs mit einem Chrome-User-Agent-String auf.
Wenn du den initialen Googlebot-Hit siehst, aber nie den Chrome-Rendering-Durchlauf auf einer JS-lastigen Seite, sieht Google sehr wahrscheinlich nicht deinen vollständigen Content. Das ist in GSC unsichtbar. Nur die Loganalyse deckt es auf.
Logs für die SEO-Analyse einrichten
Die meisten Standardkonfigurationen für Nginx und Apache loggen genug Daten für eine grundlegende Analyse. Aber “grundlegend” reicht nicht. Du willst die Antwortzeit sehen, und die meisten Defaults enthalten sie nicht.
So sieht das Nginx-Logformat aus, das ich verwende. Ergänze es in deinem http-Block in nginx.conf:
log_format seo_analysis '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$request_time $upstream_response_time';
access_log /var/log/nginx/access.log seo_analysis;Die zwei relevanten Ergänzungen sind: $request_time (gesamte Zeit von Anfrage bis Antwort) und $upstream_response_time (wie lange dein Anwendungserver gebraucht hat, ohne den Nginx-Overhead). Die Differenz zwischen diesen beiden Werten zeigt dir, ob der Engpass in deiner App liegt oder in der Proxy-Schicht.
Für Apache ergänzst du %D (Request-Time in Mikrosekunden) in deiner LogFormat-Direktive:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" seo_combined
CustomLog /var/log/apache2/access.log seo_combinedDas CDN-Problem
Hier wird’s nervig. Wenn du hinter Cloudflare, Bunny CDN, Fastly oder einem anderen CDN sitzt, zeigen dir die Logs deines Origin-Servers nur Requests, die den Cache tatsächlich passieren. Eine perfekt gecachte Seite kann von Googlebot 50 Mal gecrawlt werden — aber dein Origin sieht davon nichts.
Du brauchst CDN-Logs auf Ebene der Requests:
- Cloudflare: Der Enterprise-Plan beinhaltet vollständiges Logpush nach S3, R2 oder Datadog. Business- und Pro-Pläne erhalten gesampelte Logs über das Dashboard. Free-Plan — da hast du Pech.
- Bunny CDN: Rohe Logs sind in allen Plänen verfügbar. Download über API oder Dashboard. Das ist einer der Gründe, warum ich Bunny mag.
- Fastly: Echtzeit-Log-Streaming zu deinem eigenen Endpoint. Flexibel, aber setup-intensiv.
- AWS CloudFront: Standard- und Echtzeit-Logs nach S3. Lässt sich unkompliziert aktivieren.
Wenn dein CDN auf deinem Plan kein Bot-Level-Logging anbietet, kannst du eine Regel setzen, um den Cache für bekannte Bot-User-Agents zu umgehen. So müssen Bot-Requests zum Origin — und du kannst sie loggen. Der Tradeoff: während Crawls steigt die Last auf dem Origin leicht.
Ich bin nicht ganz sicher, ob sich dieser Tradeoff für kleinere Websites lohnt. Wenn du 200 Googlebot-Requests pro Tag bekommst, ist die Origin-Last durch das Cache-Bypassing vernachlässigbar. Wenn es 200.000 sind, überlege dir deine Infrastruktur sehr genau, bevor du diesen Schalter umlegst.
Log-Rotation und Speicherung
Logs werden schnell groß. Eine Website mit 10.000 Besuchen pro Tag erzeugt grob 2–5 MB Access-Logs pro Tag. Über ein Jahr sind das 700 MB bis 1,8 GB unkomprimiert. Gzip- komprimiert vielleicht 50–100 MB.
Für SEO-Analysen brauchst du mindestens 90 Tage Logs. Ideal sind 6 Monate, damit du saisonale Crawl-Muster siehst und sie mit Algorithmus-Updates korrelieren kannst. Richte logrotate (Linux) oder einen Cron-Job ein, um Logs wöchentlich zu komprimieren und zu archivieren. Lösche alles, was älter als 6 Monate ist, außer du hast einen konkreten Grund, es zu behalten.
Logs mit Python auswerten: Ein praxisnahes Vorgehen
Ich möchte das einem verstorbenen Hamlet Batista widmen, der die Nutzung von Python für SEO-Loganalyse und Automatisierung vorangetrieben hat. Hamlet ist 2020 gestorben, aber seine Arbeit — besonders sein Schreiben darüber, wie man mit Python und Jupyter Notebooks technisches SEO betreibt — hat grundlegend verändert, wie unsere Branche mit Datenproblemen umgeht. Vieles, was als Nächstes kommt, basiert auf Mustern, die er der SEO-Community beigebracht hat.
Hier ist ein simples Python-Skript, das Nginx-Logs nach Googlebot-Requests filtert und die Metriken erzeugt, die für SEO wirklich zählen. So ähnlich war es, was ich gegen die eigenen Logs von SEOJuice.com laufen ließ.
import re
import csv
from collections import Counter, defaultdict
from datetime import datetime
LOG_PATTERN = re.compile(
r'(?P<ip>\S+) \S+ \S+ '
r'\[(?P<timestamp>[^\]]+)\] '
r'"(?P<method>\S+) (?P<url>\S+) \S+" '
r'(?P<status>\d{3}) (?P<size>\d+) '
r'"[^"]*" "(?P<ua>[^"]*)" '
r'(?P<response_time>[\d.]+)?'
)
GOOGLEBOT_PATTERN = re.compile(r'Googlebot|Google-InspectionTool', re.IGNORECASE)
def parse_log(filepath):
"""Parse Nginx log, return only Googlebot requests."""
results = []
with open(filepath, 'r') as f:
for line in f:
match = LOG_PATTERN.match(line)
if not match:
continue
if not GOOGLEBOT_PATTERN.search(match.group('ua')):
continue
results.append({
'ip': match.group('ip'),
'timestamp': match.group('timestamp'),
'url': match.group('url'),
'status': int(match.group('status')),
'size': int(match.group('size')),
'ua': match.group('ua'),
'response_time': float(match.group('response_time') or 0),
})
return results
def analyze(requests):
"""Generate SEO-relevant metrics from Googlebot requests."""
url_counts = Counter(r['url'] for r in requests)
status_counts = Counter(r['status'] for r in requests)
slow_urls = [
(r['url'], r['response_time'])
for r in requests if r['response_time'] > 1.0
]
# Section-level crawl distribution
section_counts = Counter()
for r in requests:
parts = r['url'].strip('/').split('/')
section = parts[0] if parts and parts[0] else '(root)'
section_counts[section] += 1
print(f"Total Googlebot requests: {len(requests)}")
print(f"\n--- Status Code Distribution ---")
for code, count in status_counts.most_common():
pct = (count / len(requests)) * 100
print(f" {code}: {count} ({pct:.1f}%)")
print(f"\n--- Top 20 Most Crawled URLs ---")
for url, count in url_counts.most_common(20):
print(f" {count:>5}x {url}")
print(f"\n--- Crawl Distribution by Section ---")
total = len(requests)
for section, count in section_counts.most_common(10):
pct = (count / total) * 100
print(f" /{section}/: {count} ({pct:.1f}%)")
print(f"\n--- Slow Responses (>1s) ---")
for url, time in sorted(slow_urls, key=lambda x: -x[1])[:10]:
print(f" {time:.2f}s {url}")
if __name__ == '__main__':
requests = parse_log('/var/log/nginx/access.log')
analyze(requests)Das sind vielleicht 60 Zeilen Code. Ich habe 20 Minuten gebraucht. Und der Output hat mir sofort gezeigt, dass Googlebot unsere /tools/-Sektion ordentlich verklopft hat (73% aller Crawl-Requests), während neue Blogbeiträge kaum angefasst wurden. Das erklärte, warum unser neuer Content wochenlang nicht indexiert wurde.
Für größere Websites oder kontinuierliches Monitoring brauchst du etwas Robusteres. Der ELK-Stack (Elasticsearch, Logstash, Kibana) ist der Branchenstandard für Log-Aggregation im großen Maßstab. Logstash nimmt die Logs auf und parst sie, Elasticsearch indexiert sie für schnelle Abfragen, und Kibana liefert dir Dashboards. Mächtig, aber nicht trivial einzurichten — plane für die initiale Konfiguration ruhig einen Tag oder zwei.
Die sechs Kennzahlen, die wirklich zählen

Der Bereich /tools/ hatte Dutzende Parameterkombinationen (Filter, Sortieroptionen, Pagination), die Tausende crawlbare URLs erzeugten. Googlebot crawlt das brav alles. Währenddessen bekam unser Blog — der Bereich, der tatsächlich organischen Traffic treibt — nur 11% der Crawl-Aufmerksamkeit.
Die Lösung war eine Kombination aus Canonical-Tags, robots.txt-Regeln und noindex für Parameter-Varianten. Außerdem haben wir das interne Linking so umgebaut, dass es unsere Content-Silos besser abbildet. Innerhalb von zwei Wochen hat sich die Crawl-Frequenz im Blog verdoppelt. Neue Beiträge wurden innerhalb von Tagen indexiert statt erst nach Wochen.
Das siehst du nicht in GSC. GSC liefert dir die gesamten Crawl-Requests. Sie zerlegt das nicht nach Sektionen und zeigt dir nicht das Verteilungsproblem.
2. Verteilung der Statuscodes
Aggregiere deine Statuscodes über alle Googlebot-Requests. So sieht gesund aus:
- 200 (OK): Sollten 85–95% aller Requests sein
- 301/302 (Weiterleitungen): Unter 10%. Wenn es mehr ist, hast du Redirect Chains oder Legacy-URLs, die immer noch gecrawlt werden
- 304 (Nicht geändert): Normal. Bedeutet, dass Googlebot geprüft hat und sich die Seite nicht verändert hat
- 404 (Nicht gefunden): Unter 5%. Wenn es mehr ist, verschwendest du Crawl-Budget für tote Seiten
- 500/503 (Serverfehler): Sollte nahe Null sein. Jeder Peak ist ein Notfall
Ich habe einmal einen Fall gesehen, bei dem 22% der Googlebot-Requests 404 zurückgaben. Der vorherige Entwickler hatte eine Produktkategorie gelöscht, ohne umzuleiten. Googlebot hatte diese URLs in seiner Crawl-Queue und versuchte sie immer wieder erneut. 22% des Crawl-Budgets, verbrannt auf Seiten, die es nicht gab. Über acht Monate.
3. Antwortzeit pro URL
Google hat das wiederholt gesagt: Page Speed ist ein Rankingfaktor. Aber Core Web Vitals (die GSC meldet) messen Performance auf Client-Seite. Die Serverantwortzeit — also wie lange dein Server braucht, um das HTML zu generieren und zu senden — ist etwas anderes, und das taucht nur in Logs auf.
Wonach du suchst: Jede URL, deren Antwortzeit konsistent über 500ms liegt. Über 1 Sekunde ist ein Problem. Über 2 Sekunden kann Googlebot die Anfrage möglicherweise komplett abbrechen.
Sortiere deine Googlebot-Requests nach Antwortzeit absteigend. Die langsamsten URLs fallen meist in ein paar Kategorien: Datenbank-lastige Seiten (Produktlisten mit komplexen Filtern), Seiten, die während des Renderings externe API-Aufrufe machen, oder Seiten, die große Antworten erzeugen (Sitemaps, Feeds).
4. Crawl-Tiefenmuster
Wie viele Klicks von der Startseite aus braucht Googlebot, um zu einer Seite zu gelangen? Das steht nicht direkt im Log, aber du kannst es aus Zeitstempeln und Referral-Mustern ableiten.
Wenn Googlebot deine Startseite um 09:00 aufruft, deine Hauptkategorien um 09:01 und eine tiefe Produktseite erst um 09:14 — dann deutet dieses 14-Minuten-Fenster darauf hin, dass die Seite sehr tief verschachtelt ist. Seiten, die Googlebot spät in einer Crawl-Session entdeckt, bekommen weniger Aufmerksamkeit.
Ein einfacher Ansatz: Vergleiche den Satz an URLs, die Googlebot gecrawlt hat, mit deiner vollständigen Sitemap. Jede URL aus der Sitemap, die Googlebot in 30+ Tagen nicht besucht hat, ist aus Sicht von Google praktisch verwaist — unabhängig davon, was dein internes Linking behauptet.
5. Quoten für Bot- vs. Human-Traffic
Das ist genauso eine Security- und Performance-Kennzahl wie eine SEO-Kennzahl. Filtere deine Logs nach User Agent und berechne den Anteil der Requests, der von Bots kommt im Vergleich zu echten Nutzern.
Auf den meisten Websites sind Bots für 30–50% aller Requests verantwortlich. Wenn Bots 80%+ ausmachen, wirst du wahrscheinlich gescraped oder von schlechten Bots getroffen, die Serverressourcen verschwenden. Wenn Googlebot speziell weniger als 5% deines Bot-Traffics darstellt, konsumiert wahrscheinlich etwas anderes deine Serverkapazität — und bremst damit potenziell Google in seiner Fähigkeit, dich zu crawlen.
6. Verwaiste Seiten — Seiten, die Googlebot nie besucht
Das ist womöglich die wertvollste Analyse, die du machen kannst. Nimm die Liste der URLs aus deiner Sitemap oder deinem CMS. Vergleiche sie mit der Liste der URLs, die Googlebot in den letzten 90 Tagen besucht hat. Jede URL, die Googlebot nicht angefasst hat, ist funktional unsichtbar.
Häufige Ursachen: Die Seite hat keine internen Links, die auf sie zeigen (eine echte verwaiste Seite), sie ist zu tief in der Seitenarchitektur, oder sie ist durch eine robots.txt-Regel blockiert, von der du nichts mehr auf dem Schirm hattest.
Ich bin wirklich nicht sicher, warum nicht mehr SEOs diese Analyse routinemäßig machen. Mit dem Python-Skript oben und einer Liste deiner URLs dauert es 10 Minuten. Jedes Mal, wenn ich das für einen Kunden laufen ließ, fanden wir Seiten, die eigentlich wichtig sein sollten, aber seit Monaten nicht gecrawlt wurden.
Echte Muster, die dich alarmieren sollten
Theorie ist nett. Hier sind die konkreten Probleme, die ich durch Loganalyse auf echten Websites gefunden habe — und die sonst unentdeckt geblieben wären.
Die Falle mit Parameter-URLs
Wie erwähnt: unsere eigene Erfahrung. Aber es lohnt sich, das zu betonen: Facettierte Navigation, Suchparameter, Sortierreihenfolgen und Pagination erzeugen eine exponentielle Anzahl an crawlbaren URLs. Ein Produktkatalog mit 500 Produkten, 8 Filterkategorien und 3 Sortieroptionen kann zehntausende URLs erzeugen. Googlebot versucht, alle zu crawlen.
Laut der von Botify veröffentlichten Crawl-Budget-Analyse (2023) kann bei großen E-Commerce-Websites bis zu 80% des Crawl-Budgets von Googlebot durch Parameter-URLs verbraucht werden, die nahezu identischen Content liefern — wobei die exakte Zahl je nach Website-Typ und Architektur stark variiert. Ihr CTO Adrien Menard hat dazu ausführlich geschrieben: Beim Crawl-Budget-Problem auf großen Websites geht es nicht darum, Google mehr zu crawlen zu lassen — es geht darum, Google davon abzuhalten, Crawls für URLs mit geringem Wert zu verschwenden.
Das stille 5xx-Problem
Ein Kunde hatte intermittierende 503-Fehler, die nur dann auftraten, wenn Googlebot-Crawl-Bursts stattfanden. Monitoring (Pingdom, UptimeRobot) zeigte 99,9% Verfügbarkeit, weil diese Tools nur einmal pro Minute von einem einzelnen Standort aus prüfen. Googlebot trifft innerhalb kurzer Zeit 10–50 Seiten. Ihr Server kam mit diesem Burst nicht klar, warf für etwa 15% der Googlebot-Requests 503s und erholte sich innerhalb weniger Sekunden.
Die Crawl-Stats in GSC zeigten eine leicht erhöhte Fehlerquote. Die Logs zeigten das vollständige Bild: jeden Tag zwischen 2:00 und 3:00 Uhr UTC (wenn Googlebot typischerweise genau diese Seite besucht), fiel der Server unter Last aus. Um das zu beheben, mussten die PHP-FPM-Worker-Counts und das Database-Connection-Pooling getuned werden. Gesamtkosten: zwei Stunden DevOps-Arbeit. Die Ranking-Verbesserungen waren innerhalb von drei Wochen sichtbar.
Neuer Content bleibt unbemerkt
Wir haben eine ausführliche Anleitung veröffentlicht. Drei Wochen später war sie immer noch nicht indexiert. In GSC wurde die URL als “Entdeckt — derzeit nicht indexiert” geführt. Nett.
Die Logs erzählten die echte Geschichte: Googlebot hatte die URL nie angefragt. Nicht ein einziges Mal. Die Seite war von einer Tag-Archivseite verlinkt, die selbst in 60 Tagen nur zweimal gecrawlt wurde. Googlebot hatte den Link einfach noch nicht verfolgt.
Die Lösung war, eine interne Verlinkung von einer häufig gecrawlten Seite hinzuzufügen (unsere Homepage-Seitenleiste). Googlebot hat die neue Seite innerhalb von 48 Stunden aufgerufen. Innerhalb einer Woche indexiert. Genau solche Probleme sollte ein SEO-Checkliste nach Launch vor dem Ernstfall erkennen.
Rendering-Budget-Verschwendung
Ein SaaS-Kunde hatte eine Marketing-Website in Next.js gebaut. SSR war aktiviert — gut. Aber die Logs zeigten etwas Merkwürdiges: Der Chrome-Rendering-Bot von Googlebot machte bei jeder einzelnen Seite einen zweiten Durchlauf, inklusive einfacher statischer Seiten, die keinerlei clientseitigen dynamischen Content hatten.
Die Ursache war ein clientseitiges Analytics-Skript, das nach dem Laden der Seite das DOM verändert. Googlebot sah das initiale HTML, kam dann zurück, um JS zu rendern, und sah anderen Content (die durch Analytics injizierten Elemente). Also rendert er weiter, um sicherzugehen, dass die finale Version da ist. Das verbrauchte Rendering-Budget auf Seiten, das es nicht braucht.
Die Lösung: Das Analytics-Skript so verschieben, dass es erst nach dem DOMContentLoaded-Event lädt, mit einem defer-Attribut, und sicherstellen, dass es keine sichtbaren DOM-Elemente verändert. Die Rendering-Requests gingen um 60% zurück.
Tools für die Analyse von Logdateien

Botify — Enterprise-Level. Nimmt Logs im großen Stil entgegen, korreliert Crawl-Daten und Search Console und baut Dashboards automatisch. Wenn du eine Website mit Millionen von Seiten betreust, lohnt sich diese Investition wahrscheinlich. Für Seiten unter 100k URLs ist es Overkill. Die Preise lagen bei zuletzt (Stand Mitte 2025) im Bereich von mehreren hundert Euro pro Monat, aber die exakten Konditionen sind nicht klar transparent — und ich habe dazu gemischte Gefühle.
JetOctopus — Ein solides Mittelmaß. Cloudbasiertes Log-Analysis mit guter Visualisierung. Handhabt große Logdateien, integriert sich mit GSC und kostet deutlich weniger als Botify. Das habe ich Agenturen empfohlen, die mehrere mittelgroße Websites betreuen.
Custom Python + ELK — Wenn du technisch bist und volle Kontrolle willst, ist das Skript oben ein guter Ausgangspunkt. Für laufendes Monitoring leitest du deine Logs in den ELK-Stack (Elasticsearch, Logstash, Kibana). Logstash parst die Logs mit Grok-Mustern, Elasticsearch speichert und indexiert sie, Kibana gibt dir Echtzeit-Dashboards. Das Setup dauert einen Tag. Laufende Kosten sind im Wesentlichen nur der Server — bei einem kleinen VPS vielleicht $20–$50/Monat.
GoAccess — Ein leichter, terminalbasierter Log-Analyzer, der HTML-Reports erzeugt. Nicht SEO-spezifisch, aber überraschend nützlich für einen schnellen Überblick über Bot-Aktivität und die Verteilung der Statuscodes. Kostenlos, schnell, läuft auf jedem Server. Gut für den Use Case “Ich will nur kurz etwas checken”.
Was ich gelernt habe, als ich die eigenen Logs von SEOJuice.com analysiert habe
Moment der Transparenz. Das habe ich herausgefunden, als ich Ende 2025 zum ersten Mal eine echte Loganalyse auf unserer eigenen Seite gemacht habe.
Erkenntnis 1: Crawl-Budgetverschwendung auf Tool-Seiten. Unsere kostenlosen SEO-Tools (Site Audit, Domain Authority Checker, Keyword Extractor usw.) erzeugen pro Analyse eindeutige URLs. Jedes Tool-Ergebnis hatte eine eigene URL. Googlebot crawlt davon Tausende. Das waren größtenteils dünne, flüchtige Seiten, die nicht in den Index mussten. Wir haben noindex auf die Tool-Result-Seiten gesetzt und die Crawl-Rate im Blog ist innerhalb von zwei Wochen gestiegen.
Erkenntnis 2: Langsame Seiten, die von APIs abhängen. Unsere Pricing-Seite machte bei jeder Anfrage einen echten Call zu Paddles API, um die aktuellen Preise zu holen. Mediane Antwortzeit: 1,8 Sekunden. Googlebot hat darauf gewartet. Wir haben auf Caching der Preisdaten mit einem TTL von 1 Stunde umgestellt. Die Antwortzeit fiel auf 90ms.
Erkenntnis 3: Redirect Chains (301). Nach einer URL-Umstrukturierung hatten wir Chains wie /old-url → /medium-url → /final-url. Zwölf Prozent der Googlebot-Requests folgten Redirects. Jeder Hop ist eine verschwendete Anfrage. Wir haben alle Chains in unserem Nginx-Setup zu Single-Hop-Weiterleitungen “abgeflacht”.
Erkenntnis 4: CSS- und JS-Crawling. Das hat mich überrascht. Rund 30% der Googlebot-Requests gingen auf statische Assets — CSS-Dateien, JavaScript-Bundles, Fonts. Die sind fürs Rendern nötig, aber das bedeutete: Nur 70% unseres Crawl-Budgets gingen wirklich in Content-Seiten. Wir konnten das nicht komplett eliminieren (Google braucht diese Dateien, um Seiten darzustellen), aber es hat die Art verändert, wie wir über unser gesamtes Crawl-Budget denken.
Nettoergebnis: Nachdem wir die Punkte 1–3 adressiert hatten, wurde unser Blog-Content 3–4x schneller indexiert. Aus “entdeckt, aber nicht indexiert nach 2–3 Wochen” wurde “innerhalb von 3–5 Tagen indexiert”. Alles dank Insights aus der Loganalyse, die GSC nie ausgespielt hat.
Wie die Crawler-Analytics von SEOJuice hilft
Ich habe die crawler analytics Funktion in SEOJuice speziell gebaut, weil ich keine Lust mehr hatte, Roh-Logs händisch aufzudröseln. Sie gibt dir dieselben Erkenntnisse — ohne Command-Line-Gefrickel.
Die Crawler-Analytics von SEOJuice überwacht die Googlebot-Aktivität auf deiner Website und zeigt dir:
- Crawl-Frequenz nach Seite und Sektion — du siehst genau, wo Google sein Crawl-Budget ausgibt
- Statuscode-Verteilung über die Zeit — Fehler-Spikes erkennen, bevor sie Rankings treffen
- Trends bei der Antwortzeit — Seiten identifizieren, die Googlebot ausbremsen
- Ungecrawlte Seiten — Seiten in deiner Sitemap, die Googlebot nicht besucht
- Rendering-Aktivität — welche Seiten einen zweiten Durchlauf durch die WRS von Google auslösen
Sie ersetzt keine Roh-Loganalyse für jeden Use Case. Wenn du eine spezifische Nginx-Konfiguration debuggen oder Bot-Verhalten auf IP-Ebene untersuchen musst, brauchst du weiterhin die Roh-Logs. Aber für die 90% der Fälle, in denen du einfach wissen willst “crawlt Googlebot die richtigen Dinge?” — ist es deutlich schneller, als Python-Skripte zu schreiben.
Teste SEOJuice kostenlos und verbinde deine Website, um die Crawler-Analytics live zu sehen. Keine Kreditkarte nötig.
Ein einfacher monatlicher Prozess für Log-Audits
Du musst nicht jeden Tag auf Logs starren. Hier ist die monatliche Routine, die ich mache:
- Logs der letzten 30 Tage herunterladen oder abfragen (oder im Dashboard deines Log-Analysis-Tools schauen).
- Statuscode-Verteilung prüfen. Steigen 4xx oder 5xx an? Dann sofort untersuchen.
- Crawl-Verteilung mit Content-Verteilung vergleichen. Crawlt Google die Bereiche, die dir wichtig sind, proportional?
- Ungecrawlte URLs finden. Sitemap gegen gecrawlte URLs spiegeln. Alles, was 30+ Tage ungecrawlt bleibt, bekommt einen internen Link von einer hoch gecrawlten Seite.
- Antwortzeiten prüfen. Tauchen neue Seiten im >1s-Bereich auf? Fixe sie, bevor sie zu Ranking-Problemen werden.
- Rendering-Requests ansehen. Wenn Rendering-Requests steigen, ohne dass neue JS-lastige Seiten auftauchen, hat sich wahrscheinlich in deinem Frontend etwas verändert.
Gesamtzeit: 30–45 Minuten. Der ROI ist überproportional.
Häufig gestellte Fragen
Wie groß muss meine Website sein, damit eine Logdateianalyse sinnvoll ist?
Ich habe das nicht in jeder Nische bis ins Letzte getestet, aber es gibt kein hartes Minimum — der Nutzen skaliert mit der Größe der Website. Unter 100 Seiten crawlt Googlebot alles ohnehin, und Crawl-Budget-Themen sind unwahrscheinlich. Zwischen 500 und 5.000 Seiten wird es wertvoll. Über 10.000 Seiten ist es essenziell — Crawl-Budgetverschwendung ist bei dieser Größe praktisch garantiert. Das gesagt: Selbst eine 200-Seiten-Website kann profitieren, wenn du Indexierungsverzögerungen oder mysteriöse Ranking-Drops siehst.
Kann ich prüfen, ob eine Anfrage wirklich von Googlebot kommt und nicht nur so aussieht?
Ja. Google veröffentlicht seine IP-Bereiche, und du kannst eine Reverse-DNS-Abfrage auf die anfragende IP machen. Echte Googlebot-IPs lösen zu *.googlebot.com oder *.google.com auf. In Python: import socket; socket.gethostbyaddr('66.249.79.45'). Jede IP, die nicht auf eine Google-Domain auflöst, ist kein echter Googlebot — wahrscheinlich ein Scraper, der den Googlebot-User-Agent-String nutzt. In Googles offizieller Dokumentation wird diese Verifizierungsmethode empfohlen.
Wie oft crawlt Googlebot eine typische Website?
Das variiert enorm. Eine News-Seite mit hoher Autorität kann Tausende Googlebot-Requests pro Stunde sehen. Eine kleine Business-Seite vielleicht 50–200 pro Tag. Die Frequenz hängt davon ab, wie wichtig deine Website eingeschätzt wird, wie oft sich dein Content ändert, wie schnell dein Server antwortet und wie aktuell deine XML-Sitemap ist. Laut der 2024er Crawl-Frequenzanalyse von JetOctopus über ihre Kundenbasis liegt die mediane Crawl-Frequenz für eine 5.000-Seiten-Website bei ungefähr 300–800 Googlebot-Requests pro Tag.
Sollte ich schlechte Bots in meinen Logs blockieren?
Blocke schlechte Bots auf Server-Ebene (Nginx-Deny-Rules oder fail2ban), nicht nur in robots.txt. robots.txt ist nur eine Empfehlung — bösartige Bots ignorieren sie. Aber Vorsicht: Blocke nicht aus Versehen legitime Crawler. Ich habe Websites gesehen, die alle Bots mit “bot” im User-Agent-String blockiert haben, und dabei Googlebot erwischt. Whitelist e Google, Bing und alle anderen Suchmaschinen, die dir wichtig sind, bevor du breit angelegte Bot-Blockierungsregeln implementierst.
Welche Beziehung gibt es zwischen Logdateianalyse und Crawl-Budget?
Logdateianalyse ist, wie du das Crawl-Budget misst. Google definiert Crawl-Budget als die Kombination aus Crawl-Rate-Limit (wie schnell Google crawlen kann, ohne deinen Server zu überlasten) und Crawl-Demand (wie viel Google basierend auf dem wahrgenommenen Wert crawlen möchte). Beides kannst du nicht direkt steuern, aber du kannst Einfluss nehmen: Schnellere Antwortzeiten erhöhen das Crawl-Rate-Limit, und das Entfernen von URLs mit geringem Wert aus der Crawl-Queue von Google erhöht den Anteil des Crawl-Budgets, der für Seiten ausgegeben wird, die wirklich zählen. Logs zeigen dir beide Seiten dieser Gleichung.
Logdateianalyse ist nicht glamourös. Das ist grep und Regex und das Weiterleiten von Textdateien durch Skripte. Es gibt keine hübschen Dashboards (außer du baust sie). Aber es ist das Nächstbeste, um deine Website “durch die Augen von Google” zu sehen. GSC zeigt dir eine kuratierte Zusammenfassung. Logs zeigen dir die rohen Fakten.
Wenn du eine Website mit mehr als ein paar hundert Seiten betreust und du dir deine Server-Logs nie angesehen hast, hast du wahrscheinlich Crawl-Probleme, von denen du nichts weißt. Ich würde Geld darauf wetten.
Weiterführende Lektüre im Technical-SEO-Silo:
Read More
- Barrierefreiheit für SEO: Die Ranking-Faktor-Frage ist eine Falle
- Optimierung für Zero-Click-Suchen: Zitiert werden statt nur geklickt
- 10 On-Site-SEO-Elemente, die die Rankings 2026 beeinflussen (Prioritätsreihenfolge)
- SEO für Beauty Brands: So steigern Sie Ihren Traffic
- Anchor-Text-Leitfaden: Was Rankings im Jahr 2026 wirklich bewegt
- Googles Suchfeld fungiert jetzt als Task-Dispatcher
no credit card required