Entity SEO Explained: The Identity Layer Under Content SEO
TL;DR: Entity SEO is not “keyword SEO with schema sprinkled on top.” It is the work of making your brand, people, products, and topics easy for search and AI systems to identify as real things, connect to trusted facts, and describe without guessing.
Contrarian opener: entity SEO is about identity, not rankings
Most people search for “entity SEO” because they want a ranking tactic. Add schema. Mention related topics. Clean up internal links. Ship. I used to treat entity SEO that way at mindnow, and it worked fine for ordinary blog posts. It was weak for brands.
I see the same mistake now with vadimkravcenko.com and seojuice.com. People try to “optimize for entities” before they have made the entity itself clear. The result is a site with decent content, messy profiles, conflicting descriptions, and structured data that says more than the public web can confirm.
That is not a rankings problem first. You have an identity problem (yes, I made this mistake)—rankings can hide that problem for a while.
Google made the shift public in 2012 when Amit Singhal introduced the Knowledge Graph:
“an intelligent model—in geek-speak, a ‘graph’—that understands real-world entities and their relationships to one another: things, not strings.”
That phrase still does most of the work. Entity SEO did not appear because AI Overviews showed up. Google has been organizing search around things and relationships for more than a decade. AI search raised the cost of being vague.
In blue-link search, an unclear brand could still rank if a page matched the query. In AI search, the system may summarize your company, compare you to competitors, recommend you, omit you, or cite an old profile. If it cannot reconcile who you are, what you sell, and which sources describe you correctly, it guesses. Entity SEO is how you reduce that guessing.
What the top 3 results get right and what they miss
The current SERP explains entities fairly well. The gap is practical brand identity work. Here is the short version.
| Result | What it says | What it misses |
|---|---|---|
| Search Engine Land, “Entity SEO: The definitive guide” | Strong history of entities, Knowledge Graph, relationships, semantic search, and why Google moved beyond string matching. | It explains the system well, but the practical brand-identity layer needs a harder 2026 update: entity cleanup, AI citation drift, sameAs hygiene, and brand reconciliation across systems. |
| InLinks, “Entity SEO: the Guide to Understanding” | Good explainer on entities, topical connections, content relevance, and using entity-based signals to improve search fit. | It leans toward content and tooling. The missing piece is the brand as a durable knowledge-graph node, not only pages optimized around entity terms. |
| Ahrefs, “What is Entity-Based SEO?” | Clear glossary-level definition. Useful for beginners who need the keyword-versus-entity distinction. | Too shallow for a decision-maker. It does not show how Organization schema, Wikidata, corroborating profiles, and AI answer systems connect into one identity problem. |
So the gap is simple: the SERP explains what entities are. This article explains entity SEO as brand identity engineering for search and AI systems.

Working definition: what is entity SEO?
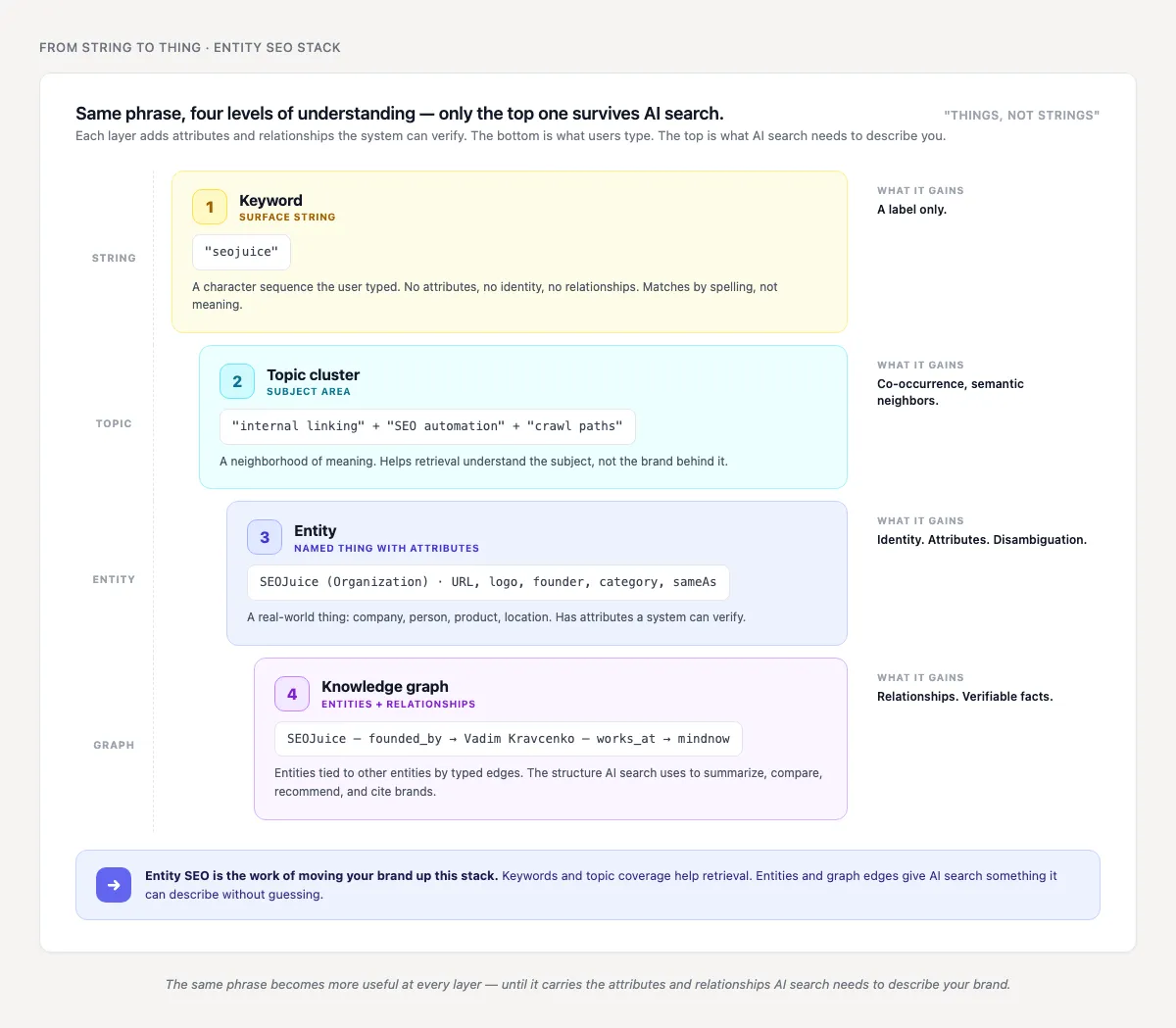
Entity SEO is the process of making real-world things connected to your business understandable, verifiable, and reusable by search systems. Those things can be a company, founder, product, location, service, event, category, dataset, or concept.
Here is the vocabulary without the fog:
- Keywords: strings people type into a search box.
- Topics: clusters of meaning around a subject.
- Entities: named things with attributes and relationships.
- The Knowledge Graph: a machine-readable map of entities and relationships.
- Schema: claims you publish about entities on your own site.
- sameAs: identity links that help systems reconcile one entity across trusted sources.
“SEOJuice” as a string means almost nothing by itself. “SEOJuice” as an Organization entity can have a URL, logo, founder, product category, social profiles, sameAs links, area served, and known topics. That is a different object.
This is also where semantic SEO and entity SEO split. Semantic SEO is about retrieval: can a system understand that your page answers a query? Entity SEO is about identity: can a system understand who published the answer, what the brand represents, and which facts about it are true?
They overlap. A strong topical footprint helps define what an entity is known for. Clean entity data helps AI systems trust and describe your content. But they are not the same job. If you want the retrieval side, read the SEOJuice guide to semantic SEO. If you want the identity layer, stay here.
Why entity SEO matters more in AI search than it did in blue-link search
Search systems do more than rank pages now. They summarize, recommend, compare, and cite brands. That changes the game because visibility no longer lives inside one ranked list.
BrightEdge analyzed tens of thousands of identical prompts across ChatGPT, Google AI Overviews, and Google AI Mode. It found that the platforms disagreed on brand recommendations 61.9% of the time. Google AI Overviews showed 6.02 brand mentions per query on average, compared with 2.37 for ChatGPT.
That does not mean one system is right and the other is wrong. It means “ranking in Google” and “being known by AI search” are now different states. The same brand can appear in AI Overviews, disappear from ChatGPT, and show up differently in Perplexity because each system grounds identity through different sources.
Andrea Volpini’s line on structured data is the cleanest 2026 framing:
“It doesn’t ‘rank for you,’ it stabilizes what AI can say about you.”
That is the point. Entity SEO reduces ambiguity. It gives retrieval and generation systems less room to invent, merge, omit, or mislabel your brand—especially when the model has to answer without crawling your homepage in real time.
If you are tracking AI visibility, this also changes reporting. A brand mention in an AI Overview, a citation in Perplexity, and a clean brand answer in ChatGPT are not interchangeable. They are separate symptoms of whether your entity is recognized across systems. For more on that layer, see the SEOJuice guide to AI Overviews SEO.
The brand-as-entity shift: Google needs to know who you are
Jason Barnard has spent years making this point in plain language:
“Being in Google’s Knowledge Graph means that Google fully and explicitly understands who you are.”
Do not overread that. A Knowledge Panel is not the only proof of entity recognition, and not every business needs one on day one. But the goal is still the same: Google should identify the company, connect it to the official site, distinguish it from similarly named things, and attach the right facts.
Weak brand entity definition usually shows up in boring places:
- Your brand name returns mixed or irrelevant results.
- Your profiles use different names, logos, descriptions, or categories.
- Your founder, company, and product are not connected anywhere.
- Your schema says one thing, LinkedIn says another, and Crunchbase says a third.
- AI tools describe the company with old positioning or wrong product names.
This is where product sites fool themselves. A site can publish clean blog posts and still be a weak entity if its Organization, Product, founder, sameAs, and topical claims are scattered. I would audit seojuice.com this way before I touched another keyword brief: identity first, content second, citations third.
If you are building a brand cluster, pair entity cleanup with brand SEO. Brand demand helps. Entity clarity tells systems which brand that demand belongs to.
Where entities live: your site, Google’s graph, Wikidata, and third-party sources
Entities do not live in one place. Search systems build confidence by comparing layers.
- Your own site: homepage, About page, author pages, product pages, location pages, and Organization schema.
- Search-engine systems: Google Knowledge Graph, entity extraction, local business data, Merchant Center, Search Console signals, and business profiles.
- Open graphs: Wikidata, Wikipedia where relevant, DBpedia, and public datasets.
- Corroborating sources: LinkedIn, Crunchbase, GitHub, YouTube, podcast pages, conference pages, industry publications, app marketplaces, review sites, and partner pages.
Wikidata matters because it is one of the few open identity layers used across many systems. Wikidata reported 121,742,179 items and more than 2.49 billion edits as of August 2025. It was also recognized in 2025 as a digital public good.
A Wikidata QID is not magic. Spammy entries can backfire. But when your brand legitimately qualifies, it can become a durable cross-system identity anchor (not every company deserves one). That matters when AI systems disagree on brands for the same prompt.
Do not create fake notability. Entity SEO is not Wikipedia spam. If the brand is not eligible for a public knowledge base, build corroboration first through real profiles, product listings, customer references, partner pages, author bios, and industry citations.

The entity SEO system: make claims, corroborate them, connect them
The implementation framework is simple—the execution is where teams get sloppy. Entity SEO has three jobs.
1. Make the claim on your own site
Your website is the canonical source for your entity claims. It should clearly state:
- Legal or public brand name.
- Official URL.
- Logo.
- Founder or team when relevant.
- Product or service category.
- Address or operating geography when relevant.
- Social and professional profiles.
- Areas of expertise.
- Parent company, product suite, or brand family.
- Contact and support channels.
A vague About page is an entity SEO problem. If your site cannot state what the entity is, external systems will not fix it.
2. Corroborate the claim elsewhere
Search and AI systems trust repeated facts more when they appear on independent or semi-independent sources. Use LinkedIn, GitHub, YouTube, Apple Podcasts, Crunchbase, app directories, partner pages, speaker pages, association pages, local citations, and industry articles where they are truthful.
Consistency matters. The same name, URL, logo, founder, product category, and short description should recur across sources. Old descriptions on third-party profiles can poison the graph for months.
3. Connect the claim with structured data and sameAs
Schema is the bridge between your canonical claims and the outside sources that confirm them. Start with Organization schema. Then add Product, Person, WebSite, WebPage, Article, BreadcrumbList, LocalBusiness, SoftwareApplication, or FAQPage only when the page supports it. If you need the mechanics, read the SEOJuice guide to schema markup for SEO.
Here is a compact Organization JSON-LD starting point. Treat it as a model, not a copy-paste answer.
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "SEOJuice",
"url": "https://seojuice.com/",
"logo": "https://seojuice.com/logo.png",
"founder": {
"@type": "Person",
"name": "Vadim Kravcenko"
},
"foundingDate": "2025",
"knowsAbout": ["entity SEO", "internal linking", "technical SEO"],
"areaServed": "Worldwide",
"sameAs": [
"https://www.linkedin.com/company/seojuice",
"https://x.com/seojuice"
],
"contactPoint": {
"@type": "ContactPoint",
"contactType": "support",
"email": "support@seojuice.io"
}
}
Aleyda Solis puts the operational instruction bluntly:
“Don’t overlook using Organization schema to implement structured data. Use every relevant property to showcase what you do.”
The phrase “every relevant property” matters. A logo and URL help. Founder, contact, product, geography, and sameAs often help more because they connect the entity to the surrounding graph.

Organization schema is not a ranking trick
Schema does not make a weak brand strong. It makes clear claims machine-readable. If those claims are unsupported or inconsistent, schema can expose the mess faster.
That is what Volpini means by “stabilizes.” Structured data helps systems associate the correct logo with the correct company, connect your official profiles, parse founder and product claims, and summarize the brand without inventing facts.
But schema should match visible page content. Do not hide claims in JSON-LD that users cannot verify on the page. Hidden claims are not strategy. They are future contradictions.
This is why sameAs hygiene matters. sameAs should point to authoritative identity sources, not every account you ever opened. A strong LinkedIn profile, GitHub organization, YouTube channel, Crunchbase profile, app listing, or Wikidata item can help. An abandoned social account from 2019 may create more noise than confidence.
Entity cleanup: why weak entities are getting riskier
Jason Barnard reported in Search Engine Land that Google’s Knowledge Graph saw a two-stage one-week drop of 6.26% in June 2025, with more than 3 billion entities deleted, according to his tracking.
That is one specialist dataset, not a public Google statement. Still, the signal matters because it fits the larger pattern: search systems are under pressure to reduce hallucinations, duplicates, and low-confidence entity records.
Risk increases when entity signals do not reconcile:
- Duplicate brand names with no disambiguation.
- Thin person entities with no corroboration.
- Local businesses with inconsistent addresses.
- Software products with unclear parent companies.
- Brand names that changed without redirects and profile cleanup.
- AI-generated author profiles with no real-world footprint.
Bad entity SEO can create more ambiguity, not less. A fake author, a forced Wikidata page, or a schema claim no external source supports may look clever for a week. Then it becomes another contradiction the graph has to resolve.
How to do an entity SEO audit
Step 1: Search the exact brand name
Check Google, Bing, ChatGPT, Perplexity, LinkedIn, YouTube, Crunchbase, GitHub, Wikidata, and relevant app or review platforms. Document what each system thinks the brand is. Do not start with traffic. Start with identity.
Step 2: Map the entity set
List the entities around the brand: Organization, founder, product, blog authors, locations, key services, categories, and owned publications. If the founder, company, and product look unrelated, mark that as a fix (I would fix this before publishing another article).
Step 3: Pick the canonical source for each entity
Usually the homepage owns the Organization entity. The About page owns the company story. Author pages own people. Product pages own products. Location pages own physical branches.
Step 4: Compare facts across sources
Check name, logo, founding date, founder, category, description, address, phone, social URLs, product names, and topical focus. Put the facts in a spreadsheet. Boring, yes. Effective, also yes.
Step 5: Fix contradictions before adding more schema
Do not publish new claims before cleaning old ones. If LinkedIn says “AI writing tool,” Crunchbase says “SEO SaaS,” and the homepage says “internal linking automation,” decide which description is true and update the rest.
Step 6: Add or improve schema
Start with Organization and WebSite. Then add Product, Person, Article, BreadcrumbList, LocalBusiness, or SoftwareApplication where useful. Match schema to visible content (the current public habit, not a magic file).
Step 7: Build corroboration
Update real profiles. Earn mentions. Create partner references. Publish founder bios. Connect product listings. Add author pages. Link them back to the canonical site where appropriate. Internal links matter too; see SEOJuice’s guide to internal linking for SEO.
Step 8: Re-test AI descriptions
Ask search and AI systems: “What is [brand]?”, “Who founded [brand]?”, “What does [brand] do?”, and “[brand] alternatives.” Record wrong answers and trace likely sources. This is how I would audit seojuice.com: first identity, then content, then citations. Not the other way around.

Entity SEO examples: what good looks like
Example 1: SaaS company
A SaaS company usually needs an Organization entity connected to a SoftwareApplication entity, founder Person entity, product category, G2 or Capterra profiles, LinkedIn, GitHub, YouTube, help docs, and support pages. The system should answer: who runs this, what software is it, what category does it belong to, and where is it trusted?
Example 2: consultant or agency
A consultant or agency needs the Person and Organization entities connected. The personal site, agency site, LinkedIn, podcast appearances, conference pages, author bios, and service pages should reinforce the same story. For mindnow and vadimkravcenko.com, the agency, founder, and personal site should not look like three unrelated things.
Example 3: local business
A local business needs LocalBusiness data that lines up across its website, Google Business Profile, local citations, review sites, service areas, staff pages, and location pages. The system should answer: who is this, where do they operate, how do customers contact them, and which location is official?
Common entity SEO mistakes
- Treating schema as the whole strategy. Schema connects claims. It cannot create trust alone.
- Creating Wikidata or Wikipedia pages too early. Public knowledge bases require real evidence. Manufacture it and the cleanup gets ugly.
- Using sameAs for every social link. Point to authoritative profiles, not weak or abandoned accounts.
- Leaving old descriptions live. Old positioning on third-party sites can keep resurfacing in AI answers.
- Publishing fake author bios. Thin personas create risk, especially when they have no public footprint.
- Confusing topic coverage with entity recognition. A blog can cover a topic well while the brand remains unclear.
- Adding Organization schema only to the homepage. Person, Product, Article, WebSite, and BreadcrumbList entities often need connections too.
- Changing a brand name without cleanup. Redirects, profiles, logos, descriptions, and citations need the same update.
- Using different logos and categories everywhere. Visual and categorical inconsistency makes reconciliation harder.
If the graph cannot reconcile the facts, polished content will not save the identity layer.
The entity SEO playbook for 2026
- Define the entity set: company, people, products, locations, services, publications, and categories.
- Choose canonical pages for each entity.
- Rewrite the About page, author pages, product pages, and profile pages for clarity.
- Clean up name, logo, URL, category, and description across third-party profiles.
- Add complete Organization schema.
- Add sameAs only to authoritative profiles.
- Connect Person, Product, Article, WebSite, and LocalBusiness schema where relevant.
- Build corroborating citations from real sources (the source must be real).
- Check Wikidata eligibility only when the entity has enough public evidence.
- Re-test Google, Bing, AI Overviews, ChatGPT, and Perplexity quarterly.
Entity SEO sits as the identity layer under content SEO, never the replacement for it. If Google and AI systems cannot tell who you are, they will struggle to trust what you publish — and that is the part most entity SEO explainers underplay.
FAQ
Is entity SEO the same as semantic SEO?
No. Semantic SEO focuses on meaning, intent, and retrieval. Entity SEO focuses on identity, facts, and relationships. A strong strategy needs both, but the work is different.
Do I need a Google Knowledge Panel for entity SEO?
No. A Knowledge Panel can be a signal of explicit understanding, but the earlier goal is cleaner reconciliation: official site, profiles, schema, product data, founder data, and citations all saying the same thing.
Should every brand create a Wikidata page?
No. Wikidata helps when the entity qualifies and has public evidence. If your brand lacks notability, build real corroboration first through profiles, product listings, partner pages, media mentions, and industry references.
How long does entity SEO take?
Basic cleanup can happen in days. Reconciliation across search and AI systems usually takes weeks or months because third-party sources, crawlers, and model-grounding systems update on different cycles.
Want help turning your brand into a cleaner entity?
SEOJuice helps teams fix the layer most content audits skip: internal connections, entity clarity, and the crawl paths that make your site easier to understand. If your brand facts are scattered, start with the audit above, then use SEOJuice to strengthen the links between the pages that define who you are.
Read More
no credit card required