En bref : Google Search Console vous montre ce que Google veut bien vous montrer. Les logs serveur vous montrent ce que Googlebot a réellement fait. J’ai découvert que Googlebot consacrait 73 % de son crawl budget à des URL paramétrées dont on avait oublié l’existence. GSC n’indiquait aucun problème. Voici comment mettre en place l’analyse de fichiers logs, ce qu’il faut chercher, et pourquoi c’est la technique la plus sous-exploitée du SEO technique.
Google Search Console est un outil formidable. Je l’utilise tous les jours. Mais il souffre d’un problème fondamental : il ne vous montre que ce que Google a choisi de rapporter.
Les statistiques d’exploration de GSC vous donnent des chiffres agrégés — nombre total de requêtes, temps de réponse moyen, quelques codes de statut. Ce qu’il ne vous dit pas, c’est quelles URL précises Googlebot a visitées, dans quel ordre, combien de temps chaque requête a pris, si Googlebot est revenu pour une seconde passe de rendu JavaScript, ou quelles sections de votre site il ignore complètement.
C’est là que se situe le trou noir. Et il est énorme.
Les logs serveur sont la vérité brute. Chaque requête de Googlebot vers votre serveur est enregistrée avec un horodatage, l’URL exacte, le code de statut, le temps de réponse et la chaîne user agent. Pas de synthèse, pas d’échantillonnage, pas de filtre décidé par Google. Des données brutes.
Je vais être honnête avec vous : j’ai ignoré l’analyse de fichiers logs pendant les deux premières années de SEOJuice. Ça me semblait réservé aux SEO en entreprise, ceux qui signent des contrats Botify à six chiffres. J’avais tort. Dès que j’ai commencé à parser nos propres logs Nginx, j’ai trouvé des problèmes que GSC dissimulait depuis des mois. Du crawl budget gaspillé sur des URL à facettes. Des erreurs 5xx qui ne se produisaient que lors des passages de Googlebot. Des articles de blog neufs que Googlebot n’avait pas visités depuis trois semaines.
D’après ce que j’ai observé sur des centaines de sites : selon mon expérience, presque chaque site de plus de 500 pages présente au moins un problème d’exploration significatif que seule l’analyse des logs peut révéler.
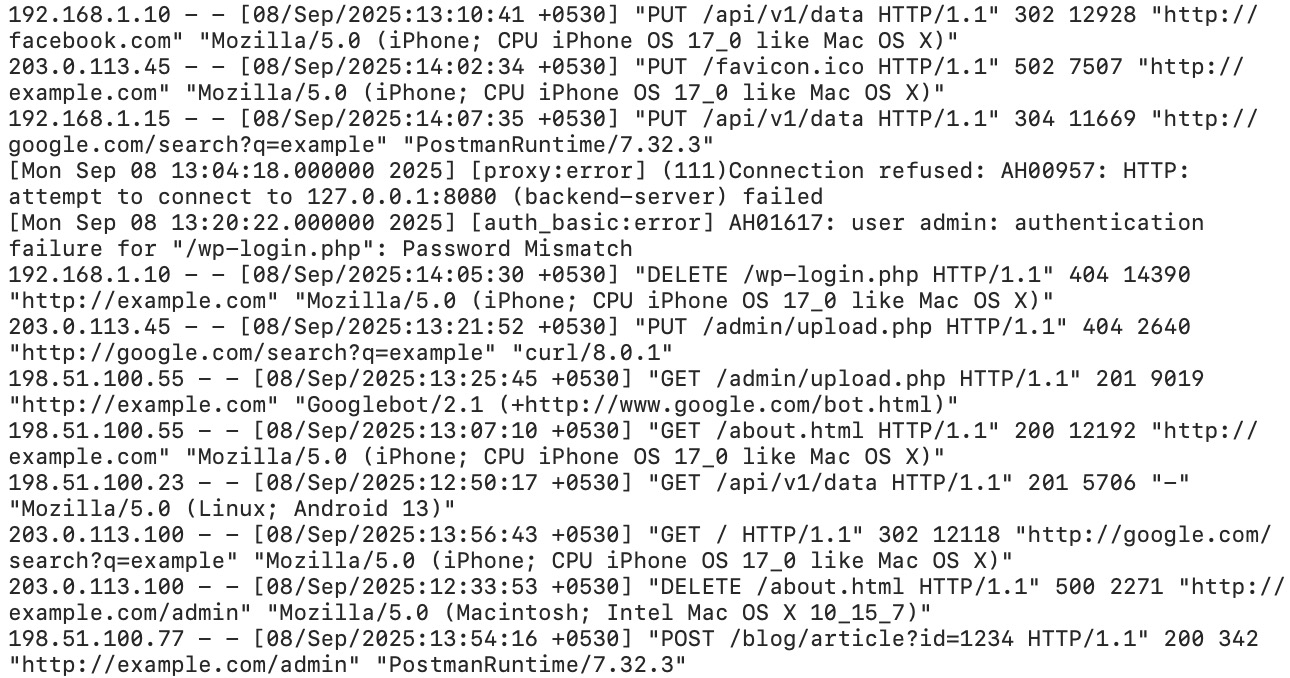
Décomposons tout ça :
| Champ | Valeur | Signification |
|---|---|---|
| Adresse IP | 66.249.79.45 | IP de Googlebot (la plage 66.249.x.x appartient à Google) |
| Horodatage | [15/Mar/2026:09:23:17 +0000] | Heure exacte de la requête |
| Requête | GET /blog/content-decay-guide/ HTTP/2.0 | Quelle URL a été explorée |
| Code de statut | 200 | Réponse du serveur (200 = OK) |
| Octets envoyés | 34521 | Taille de la réponse en octets |
| Referer | - | Provenance de la requête (généralement vide pour les bots) |
| User Agent | Googlebot/2.1 | Identifie le robot d’exploration |
| Temps de réponse | 0.142 | 142 ms pour servir la page |
Les différents serveurs web utilisent des formats légèrement différents. Le « Combined Log Format » d’Apache est quasiment identique à celui de Nginx. IIS utilise un format étendu W3C avec des champs séparés par des espaces et une ligne d’en-tête définissant les colonnes. Les données sont les mêmes — c’est l’agencement qui diffère.
Les champs essentiels pour le SEO sont : le user agent (pour filtrer les bots), l’URL (pour voir ce qui est exploré), le code de statut (pour repérer les erreurs) et le temps de réponse (pour identifier les goulots d’étranglement).
Toutes les requêtes de Googlebot ne proviennent pas du même robot. Google utilise différents user agents pour différents objectifs, et les distinguer est important.
| Chaîne User Agent | Rôle | Pourquoi c’est important |
|---|---|---|
Googlebot/2.1 | Robot d’exploration principal | C’est le crawl principal — vos pages essentielles |
Googlebot-Image/1.0 | Robot d’images | Explore les images pour l’index Google Images |
Googlebot-Video/1.0 | Robot vidéo | Découvre et indexe le contenu vidéo |
Googlebot-News | Robot d’actualités | Pertinent uniquement si vous êtes dans Google News |
APIs-Google | Récupérateur AMP/API | Récupère les pages AMP et les contenus spéciaux |
Chrome/W.X.Y.Z (avec Googlebot) | Bot de rendu | C’est le plus important. Quand vous voyez un UA Chrome accompagnant Googlebot, c’est le Web Rendering Service — Google exécute votre JavaScript |
Le bot de rendu mérite une attention particulière. Lorsque Googlebot explore une page pour la première fois, il récupère le HTML brut. Si la page contient du JavaScript, Google met en file d’attente une seconde requête via son Web Rendering Service (WRS), qui utilise un navigateur Chrome headless. Cette seconde requête apparaît dans vos logs avec une chaîne user agent Chrome.
Si vous voyez le premier passage de Googlebot mais jamais la passe de rendu Chrome sur une page riche en JS, Google ne voit probablement pas l’intégralité de votre contenu. C’est invisible dans GSC. Seule l’analyse des logs le révèle.
La plupart des configurations Nginx et Apache par défaut enregistrent suffisamment de données pour une analyse de base. Mais « de base » ne suffit pas. Vous voulez le temps de réponse, et la plupart des configurations par défaut ne l’incluent pas.
Voici le format de log Nginx que j’utilise. Ajoutez-le dans votre bloc http de nginx.conf :
log_format seo_analysis '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$request_time $upstream_response_time';
access_log /var/log/nginx/access.log seo_analysis;Les deux ajouts qui comptent : $request_time (temps total de la requête à la réponse) et $upstream_response_time (temps de traitement de votre serveur applicatif, hors surcharge Nginx). La différence entre ces deux valeurs vous indique si le goulot d’étranglement se situe au niveau de votre application ou de votre couche proxy.
Pour Apache, ajoutez %D (temps de requête en microsecondes) à votre directive LogFormat :
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" seo_combined
CustomLog /var/log/apache2/access.log seo_combinedC’est là que les choses se compliquent. Si vous êtes derrière Cloudflare, Bunny CDN, Fastly ou tout autre CDN, les logs de votre serveur d’origine ne montrent que les requêtes qui passent au-delà du cache. Une page parfaitement mise en cache peut être explorée 50 fois par Googlebot sans que votre serveur d’origine en voie une seule.
Vous avez besoin de logs au niveau du CDN :
Si votre CDN ne propose pas de logging au niveau des bots sur votre plan, vous pouvez créer une règle pour contourner le cache pour les user agents de bots connus. Cela force les requêtes des bots à atteindre votre serveur d’origine, où vous pouvez les enregistrer. Le compromis : une charge légèrement plus élevée sur l’origine pendant les phases d’exploration.
Je ne suis pas entièrement convaincu que ce compromis en vaille la peine pour les petits sites. Si vous recevez 200 requêtes Googlebot par jour, la charge supplémentaire sur l’origine est négligeable. Si vous en recevez 200 000, réfléchissez sérieusement à votre infrastructure avant d’activer cette option.
Les logs grossissent vite. Un site avec 10 000 visites quotidiennes génère environ 2 à 5 Mo de logs d’accès par jour. Sur un an, cela représente 700 Mo à 1,8 Go non compressés. Compressés en gzip, peut-être 50 à 100 Mo.
Pour l’analyse SEO, conservez au minimum 90 jours de logs. Idéalement 6 mois, pour observer les tendances saisonnières d’exploration et les corréler avec les mises à jour d’algorithme. Mettez en place logrotate (Linux) ou une tâche cron pour compresser et archiver les logs chaque semaine. Supprimez tout ce qui dépasse 6 mois, sauf raison particulière de le conserver.
Je souhaite dédier cette section à feu Hamlet Batista, pionnier de l’utilisation de Python pour l’analyse de logs SEO et l’automatisation. Hamlet nous a quittés en 2020, mais son travail — en particulier ses écrits sur l’utilisation de Python et des notebooks Jupyter pour le SEO technique — a fondamentalement transformé l’approche de notre industrie face aux problèmes de données. Une grande partie de ce qui suit s’appuie sur les méthodes qu’il a enseignées à la communauté SEO.
Voici un script Python basique qui filtre les logs Nginx pour les requêtes Googlebot et génère les métriques réellement utiles en SEO. C’est très proche de ce que j’ai exécuté sur les logs de SEOJuice.com.
import re
import csv
from collections import Counter, defaultdict
from datetime import datetime
LOG_PATTERN = re.compile(
r'(?P<ip>\S+) \S+ \S+ '
r'\[(?P<timestamp>[^\]]+)\] '
r'"(?P<method>\S+) (?P<url>\S+) \S+" '
r'(?P<status>\d{3}) (?P<size>\d+) '
r'"[^"]*" "(?P<ua>[^"]*)" '
r'(?P<response_time>[\d.]+)?'
)
GOOGLEBOT_PATTERN = re.compile(r'Googlebot|Google-InspectionTool', re.IGNORECASE)
def parse_log(filepath):
"""Parse Nginx log, return only Googlebot requests."""
results = []
with open(filepath, 'r') as f:
for line in f:
match = LOG_PATTERN.match(line)
if not match:
continue
if not GOOGLEBOT_PATTERN.search(match.group('ua')):
continue
results.append({
'ip': match.group('ip'),
'timestamp': match.group('timestamp'),
'url': match.group('url'),
'status': int(match.group('status')),
'size': int(match.group('size')),
'ua': match.group('ua'),
'response_time': float(match.group('response_time') or 0),
})
return results
def analyze(requests):
"""Generate SEO-relevant metrics from Googlebot requests."""
url_counts = Counter(r['url'] for r in requests)
status_counts = Counter(r['status'] for r in requests)
slow_urls = [
(r['url'], r['response_time'])
for r in requests if r['response_time'] > 1.0
]
# Section-level crawl distribution
section_counts = Counter()
for r in requests:
parts = r['url'].strip('/').split('/')
section = parts[0] if parts and parts[0] else '(root)'
section_counts[section] += 1
print(f"Total Googlebot requests: {len(requests)}")
print(f"\n--- Status Code Distribution ---")
for code, count in status_counts.most_common():
pct = (count / len(requests)) * 100
print(f" {code}: {count} ({pct:.1f}%)")
print(f"\n--- Top 20 Most Crawled URLs ---")
for url, count in url_counts.most_common(20):
print(f" {count:>5}x {url}")
print(f"\n--- Crawl Distribution by Section ---")
total = len(requests)
for section, count in section_counts.most_common(10):
pct = (count / total) * 100
print(f" /{section}/: {count} ({pct:.1f}%)")
print(f"\n--- Slow Responses (>1s) ---")
for url, time in sorted(slow_urls, key=lambda x: -x[1])[:10]:
print(f" {time:.2f}s {url}")
if __name__ == '__main__':
requests = parse_log('/var/log/nginx/access.log')
analyze(requests)Soixante lignes de code environ. Vingt minutes d’écriture. Et le résultat m’a immédiatement montré que Googlebot martelait notre section /tools/ (73 % de toutes les requêtes d’exploration) alors qu’il touchait à peine les nouveaux articles de blog. Ce qui expliquait pourquoi notre nouveau contenu mettait des semaines à être indexé.
Pour les sites plus importants ou le monitoring continu, vous aurez besoin de quelque chose de plus robuste. La stack ELK (Elasticsearch, Logstash, Kibana) est le standard de l’industrie pour l’agrégation de logs à grande échelle. Logstash ingère et parse les logs, Elasticsearch les indexe pour des requêtes rapides, et Kibana vous fournit des tableaux de bord. C’est puissant mais pas trivial à mettre en place — prévoyez un à deux jours pour la configuration initiale.

La section /tools/ comportait des dizaines de combinaisons de paramètres (filtres, options de tri, pagination) générant des milliers d’URL explorables. Googlebot les explorait consciencieusement. Pendant ce temps, notre blog — la section qui génère réellement du trafic organique — ne recevait que 11 % de l’attention d’exploration.
La solution : une combinaison de balises canonical, de règles robots.txt et de noindex sur les variantes paramétrées. Nous avons aussi restructuré le maillage interne pour mieux refléter nos silos de contenu. En deux semaines, la fréquence d’exploration du blog a doublé. Les nouveaux articles étaient indexés en quelques jours au lieu de quelques semaines.
Impossible de voir ça dans GSC. GSC vous donne le nombre total de requêtes d’exploration. Il ne les ventile pas par section et ne vous montre pas le problème de répartition.
Agrégez vos codes de statut sur l’ensemble des requêtes Googlebot. Voici à quoi ressemble une situation saine :
J’ai vu un jour un site où 22 % des requêtes Googlebot renvoyaient une 404. Le développeur précédent avait supprimé une catégorie de produits sans redirection. Googlebot avait ces URL dans sa file d’exploration et continuait de les retenter. Vingt-deux pour cent du crawl budget, brûlé sur des pages qui n’existaient plus. Pendant huit mois.
Google a affirmé à plusieurs reprises que la vitesse de page est un facteur de classement. Mais les Core Web Vitals (que GSC rapporte) mesurent les performances côté client. Le temps de réponse serveur — le temps que met votre serveur à générer et envoyer le HTML — est une autre affaire, et il n’apparaît que dans les logs.
Ce que vous cherchez : toute URL dont le temps de réponse dépasse régulièrement 500 ms. Au-dessus d’une seconde, c’est un problème. Au-dessus de 2 secondes, Googlebot risque d’abandonner la requête purement et simplement.
Triez vos requêtes Googlebot par temps de réponse décroissant. Les URL les plus lentes entrent généralement dans quelques catégories : pages gourmandes en base de données (listings produits avec filtres complexes), pages effectuant des appels API externes pendant le rendu, ou pages générant des réponses volumineuses (sitemaps, flux).
Combien de clics depuis la page d’accueil Googlebot a-t-il besoin pour atteindre une page ? Cette information n’est pas directement dans les logs, mais vous pouvez la déduire en examinant les horodatages et les patterns de référence.
Si Googlebot atteint votre page d’accueil à 09h00, vos pages de catégories principales à 09h01 et une page produit profonde à 09h14 — cet écart de 14 minutes suggère que la page est profondément imbriquée. Les pages que Googlebot découvre tardivement dans une session d’exploration reçoivent moins d’attention.
Une approche plus simple : comparez l’ensemble des URL que Googlebot a explorées avec votre sitemap complet. Toute URL présente dans le sitemap que Googlebot n’a pas visitée depuis plus de 30 jours est de facto orpheline du point de vue de Google, quel que soit l’état de votre maillage interne.
C’est autant une métrique de sécurité et de performance qu’une métrique SEO. Filtrez vos logs par user agent et calculez le pourcentage de requêtes totales provenant de bots par rapport aux vrais utilisateurs.
Sur la plupart des sites, les bots représentent 30 à 50 % de toutes les requêtes. Si les bots dépassent 80 %, vous êtes probablement scrape ou victime de bots malveillants qui gaspillent les ressources serveur. Si Googlebot en particulier représente moins de 5 % de votre trafic bot, autre chose consomme la capacité de votre serveur et ralentit potentiellement la capacité de Google à vous explorer.
C’est peut-être l’analyse la plus précieuse que vous puissiez mener. Prenez la liste des URL de votre sitemap ou de votre CMS. Comparez-la avec la liste des URL que Googlebot a visitées au cours des 90 derniers jours. Toute URL non visitée est fonctionnellement invisible.
Causes fréquentes : la page n’a aucun lien interne pointant vers elle (une véritable page orpheline), la page est trop profonde dans l’architecture du site, ou la page est bloquée par une règle robots.txt oubliée.
Je ne comprends sincèrement pas pourquoi davantage de SEO ne font pas cette analyse en routine. Ça prend 10 minutes avec le script Python ci-dessus et une liste de vos URL. À chaque fois que je l’ai exécuté pour un client, nous avons trouvé des pages censées être importantes mais qui n’avaient pas été explorées depuis des mois.
La théorie, c’est bien. Voici les vrais problèmes que j’ai découverts grâce à l’analyse des logs, sur des sites réels, et qui seraient passés inaperçus autrement.
J’ai déjà mentionné notre propre expérience. Mais il vaut la peine d’insister : la navigation à facettes, les paramètres de recherche, les ordres de tri et la pagination créent un nombre exponentiel d’URL explorables. Un catalogue produits de 500 produits, 8 catégories de filtres et 3 options de tri peut générer des dizaines de milliers d’URL. Googlebot essaiera de toutes les explorer.
Selon les recherches publiées par Botify sur le crawl budget (2023), sur les grands sites e-commerce, jusqu’à 80 % du crawl budget de Googlebot peut être consommé par des URL paramétrées qui délivrent un contenu quasi identique — même si le chiffre exact varie considérablement selon le type et l’architecture du site. Leur CTO, Adrien Menard, a beaucoup écrit à ce sujet : le problème de crawl budget sur les grands sites ne consiste pas à pousser Google à explorer davantage — il s’agit d’empêcher Google de gaspiller ses explorations sur des URL à faible valeur.
Un client avait des erreurs 503 intermittentes qui n’apparaissaient que lors des pics d’exploration de Googlebot. Leur monitoring (Pingdom, UptimeRobot) indiquait un uptime de 99,9 % parce que ces outils vérifient une fois par minute depuis un seul emplacement. Googlebot, lui, envoie 10 à 50 requêtes en rafale. Leur serveur ne pouvait pas absorber ces pics, renvoyait des 503 pour environ 15 % des requêtes Googlebot, et récupérait en quelques secondes.
Les statistiques d’exploration de GSC montraient un taux d’erreur légèrement élevé. Les logs montraient le tableau complet : chaque jour entre 2h et 3h UTC (quand Googlebot a tendance à cibler ce site en particulier), le serveur cédait sous la charge. La correction a nécessité un ajustement du nombre de workers PHP-FPM et du pooling de connexions base de données. Coût total : deux heures de travail DevOps. Les améliorations de classement sont apparues en trois semaines.
Nous avions publié un guide détaillé. Trois semaines plus tard, il n’était toujours pas indexé. GSC affichait l’URL comme « Découverte — non indexée actuellement ». Très utile.
Les logs racontaient la vraie histoire : Googlebot n’avait jamais demandé cette URL. Pas une seule fois. La page était reliée depuis une page d’archive de tags qui elle-même n’avait été explorée que deux fois en 60 jours. Googlebot n’avait tout simplement pas encore suivi le lien.
La solution : ajouter un lien interne depuis une page fréquemment explorée (la barre latérale de notre page d’accueil). Googlebot a atteint la nouvelle page en 48 heures. Indexée en une semaine. C’est exactement le type de problème qu’une checklist SEO post-lancement devrait détecter avant qu’il ne devienne un vrai problème.
Un client SaaS avait un site marketing construit avec Next.js. Le SSR était activé — bien. Mais les logs montraient quelque chose d’étrange : le bot de rendu Chrome de Googlebot effectuait une seconde passe sur chaque page, y compris les pages statiques simples sans contenu dynamique côté client.
Le problème : un script analytics côté client qui modifiait le DOM après le chargement de la page. Googlebot voyait le HTML initial, puis revenait pour le rendu JS et trouvait un contenu différent (les éléments injectés par l’analytics). Il continuait donc à refaire le rendu pour s’assurer d’avoir la version finale. Cela consommait du budget de rendu sur des pages qui n’en avaient pas besoin.
La solution : déplacer le script analytics pour qu’il se charge après l’événement DOMContentLoaded avec un attribut defer, et s’assurer qu’il ne modifie pas les éléments DOM visibles. Les requêtes de rendu ont chuté de 60 %.

Botify — Niveau enterprise. Ingère les logs à grande échelle, les croise avec les données d’exploration et la Search Console, et génère des tableaux de bord automatiquement. Si vous gérez un site de plusieurs millions de pages, l’investissement en vaut probablement la peine. Pour les sites de moins de 100 000 pages, c’est surdimensionné. Le tarif se situait dans les centaines d’euros par mois la dernière fois que j’ai vérifié (mi-2025), bien que leur grille tarifaire soit opaque — et j’ai des sentiments mitigés à ce sujet.
JetOctopus — Un bon compromis. Analyse de logs cloud avec une visualisation soignée. Gère les fichiers logs volumineux, s’intègre à GSC, et coûte nettement moins que Botify. Je l’ai recommandé à des agences gérant plusieurs sites de taille moyenne.
Python custom + ELK — Si vous êtes technique et voulez un contrôle total, le script ci-dessus est un point de départ. Pour un monitoring continu, envoyez vos logs dans la stack ELK (Elasticsearch, Logstash, Kibana). Logstash parse les logs avec des patterns grok, Elasticsearch les stocke et les indexe, Kibana vous fournit des tableaux de bord en temps réel. L’installation prend une journée. Le coût récurrent est juste le serveur — environ 20 à 50 €/mois sur un petit VPS.
GoAccess — Un analyseur de logs léger en terminal qui génère des rapports HTML. Pas spécifique au SEO, mais étonnamment utile pour un aperçu rapide de l’activité des bots et de la distribution des codes de statut. Gratuit, rapide, fonctionne sur n’importe quel serveur. Idéal pour le cas d’usage « je veux juste vérifier quelque chose rapidement ».
Moment transparence. Voici ce que j’ai trouvé en lançant une vraie analyse de logs sur notre propre site fin 2025.
Constat 1 : Gaspillage de crawl budget sur les pages d’outils. Nos outils SEO gratuits (audit de site, vérificateur d’autorité de domaine, extracteur de mots-clés, etc.) génèrent des URL uniques par analyse. Chaque résultat d’outil avait une URL unique. Googlebot les explorait par milliers. C’étaient pour la plupart des pages fines et éphémères qui n’avaient pas besoin d’être indexées. Nous avons ajouté noindex aux pages de résultats d’outils et avons vu le taux d’exploration de notre blog augmenter en deux semaines.
Constat 2 : Pages lentes dépendantes d’API. Notre page de tarification faisait un appel en temps réel à l’API de Paddle pour récupérer les prix actuels. Temps de réponse médian : 1,8 seconde. Googlebot attendait. Nous sommes passés à un cache des données tarifaires avec un TTL d’une heure. Le temps de réponse est tombé à 90 ms.
Constat 3 : Chaînes de redirections 301. Après une restructuration d’URL, nous avions des chaînes du type /old-url → /medium-url → /final-url. Douze pour cent des requêtes Googlebot suivaient des redirections. Chaque saut est une requête gaspillée. Nous avons aplati toutes les chaînes en redirections à un seul saut dans notre configuration Nginx.
Constat 4 : Exploration des CSS et JS. Ça m’a surpris. Environ 30 % des requêtes Googlebot ciblaient des ressources statiques — fichiers CSS, bundles JavaScript, polices. C’est nécessaire pour le rendu, mais cela signifiait que seulement 70 % de notre crawl budget allait aux pages de contenu réelles. Nous ne pouvions pas éliminer cela (Google a besoin de ces fichiers pour afficher les pages), mais cela a recadré notre façon de penser notre crawl budget total.
Résultat net : après avoir corrigé les constats 1 à 3, notre contenu blog était indexé 3 à 4 fois plus vite. Les nouveaux articles sont passés de « découvert mais non indexé pendant 2 à 3 semaines » à « indexé en 3 à 5 jours ». Le tout grâce à des insights d’analyse de logs que GSC n’a jamais révélés.
J’ai construit la fonctionnalité d’analyse du crawler dans SEOJuice précisément parce que j’en avais assez de parser des logs bruts. Elle vous donne les mêmes informations sans passer par la ligne de commande.
L’analyse du crawler de SEOJuice surveille l’activité de Googlebot sur votre site et révèle :
Cela ne remplace pas l’analyse brute des logs dans tous les cas. Si vous devez déboguer une configuration Nginx spécifique ou investiguer le comportement des bots au niveau IP, les logs bruts restent indispensables. Mais pour les 90 % de cas où vous voulez simplement savoir « est-ce que Googlebot explore les bonnes pages ? » — c’est bien plus rapide que d’écrire des scripts Python.
Essayez SEOJuice gratuitement et connectez votre site pour voir les analyses du crawler en action. Sans carte bancaire.
Vous n’avez pas besoin de scruter les logs tous les jours. Voici la routine mensuelle que je suis :
Temps total : 30 à 45 minutes. Le retour sur investissement est disproportionné.
Je n’ai pas testé cela de manière exhaustive dans toutes les niches, mais il n’y a pas de seuil minimum strict — le bénéfice augmente avec la taille du site. En dessous de 100 pages, Googlebot explorera tout quoi qu’il arrive, et vous n’aurez probablement pas de problème de crawl budget. Entre 500 et 5 000 pages, cela commence à devenir utile. Au-delà de 10 000 pages, c’est essentiel — le gaspillage de crawl budget est quasi garanti sur des sites de cette taille. Cela dit, même un site de 200 pages peut en bénéficier si vous constatez des retards d’indexation ou des baisses de classement inexplicables.
Oui, c’est possible. Google publie ses plages d’adresses IP, et vous pouvez effectuer une résolution DNS inverse sur l’IP source. Les IP légitimes de Googlebot résolvent vers *.googlebot.com ou *.google.com. En Python : import socket; socket.gethostbyaddr('66.249.79.45'). Toute IP qui ne résout pas vers un domaine Google est un faux Googlebot — probablement un scraper utilisant la chaîne user agent de Googlebot. La documentation officielle de Google recommande cette méthode de vérification.
Cela varie énormément. Un site d’actualités à forte autorité peut recevoir des milliers de requêtes Googlebot par heure. Un site de petite entreprise peut en voir 50 à 200 par jour. La fréquence dépend de l’importance perçue de votre site, de la fréquence de mise à jour de votre contenu, de la rapidité de réponse de votre serveur et de la fraîcheur de votre sitemap XML. Selon l’analyse de fréquence d’exploration de JetOctopus (2024) sur leur base clients, la fréquence médiane d’exploration pour un site de 5 000 pages se situe entre 300 et 800 requêtes Googlebot par jour.
Bloquez les mauvais bots au niveau du serveur (règles deny Nginx ou fail2ban), pas seulement dans le robots.txt. Le robots.txt est une suggestion — les bots malveillants l’ignorent. Mais soyez prudent : ne bloquez pas accidentellement les robots légitimes. J’ai vu des sites qui bloquaient tous les bots contenant « bot » dans la chaîne user agent, ce qui englobait Googlebot. Ajoutez toujours Google, Bing et les autres moteurs de recherche qui vous intéressent en liste blanche avant de mettre en place des règles de blocage de bots à large spectre.
L’analyse de fichiers logs est la façon dont vous mesurez le crawl budget. Google définit le crawl budget comme la combinaison de la limite de taux d’exploration (la vitesse à laquelle Google peut explorer sans surcharger votre serveur) et de la demande d’exploration (combien Google souhaite explorer en fonction de la valeur perçue). Vous ne pouvez contrôler directement ni l’un ni l’autre, mais vous pouvez les influencer : des temps de réponse plus rapides augmentent la limite de taux d’exploration, et supprimer les pages à faible valeur de la file d’exploration de Google augmente la proportion de crawl budget consacrée aux pages qui comptent. Les logs vous montrent les deux côtés de cette équation.
L’analyse de fichiers logs n’a rien de glamour. C’est du grep, des regex et des fichiers texte envoyés dans des scripts. Pas de jolis tableaux de bord (sauf si vous les construisez). Mais c’est ce qui se rapproche le plus d’une vision de votre site à travers les yeux de Google. GSC vous montre un résumé filtré. Les logs vous montrent la vérité brute.
Si vous gérez un site de plus de quelques centaines de pages et que vous n’avez jamais regardé vos logs serveur, vous avez des problèmes d’exploration que vous ignorez. J’en mettrais ma main à couper.
Pour aller plus loin dans le silo SEO technique :
no credit card required
No related articles found.
