TL;DR: Google Search Console te dice lo que Google quiere que veas. Los registros del servidor te muestran lo que Googlebot hizo realmente. Descubrí que Googlebot estaba dedicando el 73% de su presupuesto de rastreo a URLs con parámetros que se nos habían olvidado. En GSC no aparecía nada raro. Te explico cómo configurar el análisis de archivos de log, qué debes mirar y por qué es la técnica de SEO técnico menos utilizada (y más infravalorada).
Google Search Console es una herramienta fantástica. La uso a diario. Pero tiene un problema fundamental: solo muestra lo que Google ha decidido reportar.
Las estadísticas de rastreo de GSC te dan números agregados — solicitudes totales, tiempo de respuesta promedio, algunos códigos de estado. Lo que no te dice es qué URLs específicas golpeó Googlebot, en qué orden, cuánto tardó cada solicitud, si Googlebot volvió para un segundo pase y renderizar JavaScript, o qué secciones de tu sitio está ignorando por completo.
Ahí está el hueco. Y es enorme.
Los logs del servidor son la verdad sin filtros. Cada solicitud que Googlebot hace a tu servidor queda registrada con una marca de tiempo, la URL exacta, el código de estado, el tiempo de respuesta y la cadena de user agent. Sin resúmenes, sin muestreos y sin que Google decida qué necesitas saber. Datos en crudo.
Voy a ser honesto con algo: ignoré el análisis de archivos de log durante los primeros dos años gestionando SEOJuice. Me parecía algo que hacían los SEOs “enterprise” con contratos de Botify de seis cifras. Me equivoqué. En el momento en que empecé a analizar nuestros propios logs de Nginx, encontré problemas que GSC había estado ocultando durante meses. Desperdicio de presupuesto de rastreo en URLs con parámetros (facetas) que no tocábamos. Errores 5xx que solo ocurrían siguiendo patrones de rastreo de Googlebot. Posts nuevos que Googlebot no había visitado en tres semanas.
Con base en lo que he visto en cientos de sitios: en mi experiencia, casi cualquier sitio con más de 500 páginas tiene al menos un problema de rastreo importante que solo el análisis de logs puede revelar.
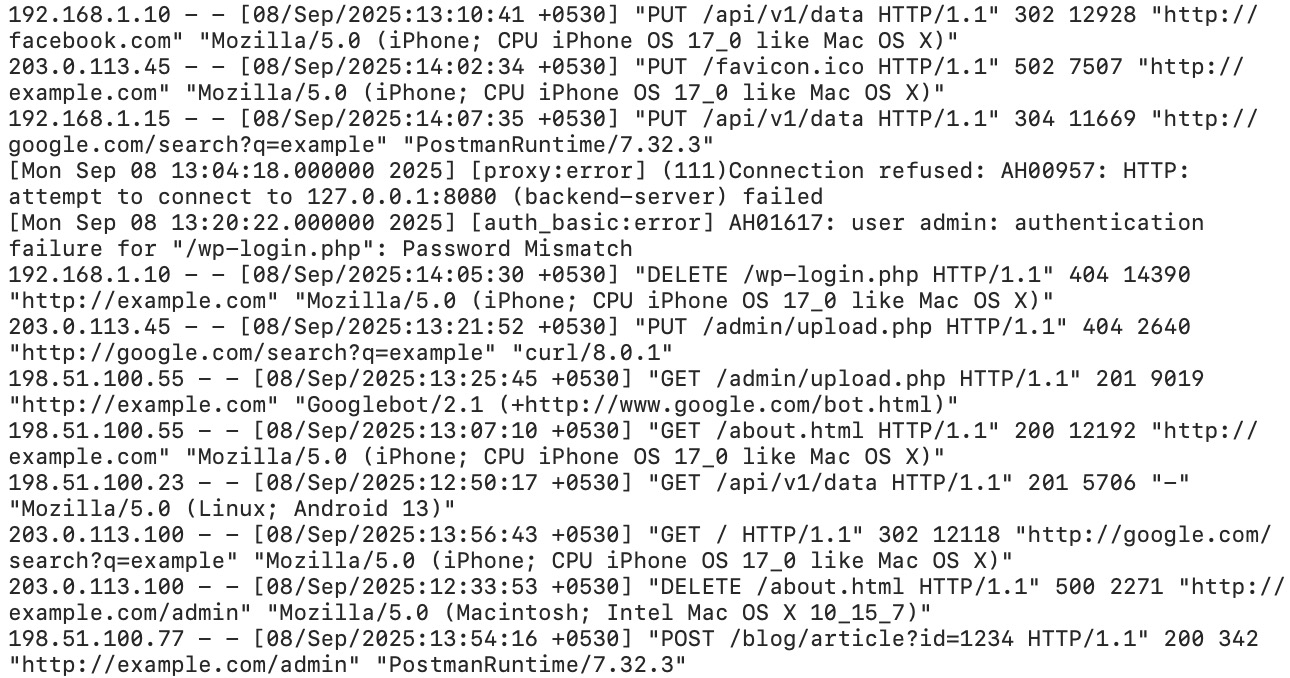
Desglosemos eso:
| Campo | Valor | Qué significa |
|---|---|---|
| Dirección IP | 66.249.79.45 | IP de Googlebot (el rango 66.249.x.x es Google) |
| Timestamp | [15/Mar/2026:09:23:17 +0000] | Hora exacta de la solicitud |
| Request | GET /blog/content-decay-guide/ HTTP/2.0 | Qué URL se rastreó |
| Código de estado | 200 | Respuesta del servidor (200 = OK) |
| Bytes enviados | 34521 | Tamaño de la respuesta en bytes |
| Referer | - | Desde dónde vino la solicitud (normalmente vacío para bots) |
| User Agent | Googlebot/2.1 | Identifica el rastreador |
| Tiempo de respuesta | 0.142 | 142 ms para servir la página |
Los distintos servidores web usan formatos ligeramente diferentes. El “Combined Log Format” de Apache es casi idéntico al de Nginx. IIS usa un formato extendido W3C con campos separados por espacios y una línea de cabecera que define las columnas. Los datos son los mismos; cambia la disposición.
Los campos críticos para SEO son: user agent (para filtrar bots), URL (para ver qué se está rastreando), código de estado (para encontrar errores) y tiempo de respuesta (para detectar cuellos de botella de rendimiento).
No todas las solicitudes de Googlebot usan el mismo rastreador. Google emplea user agents distintos según el objetivo, y saber diferenciarlos importa.
| Cadena de User Agent | Qué hace | Por qué importa |
|---|---|---|
Googlebot/2.1 | Rastreador web principal | Este es el rastreo base: tus páginas clave |
Googlebot-Image/1.0 | Rastreador de imágenes | Rastrea imágenes para el índice de Google Imágenes |
Googlebot-Video/1.0 | Rastreador de video | Descubre e indexa contenido de video |
Googlebot-News | Rastreador de noticias | Solo relevante si estás en Google News |
APIs-Google | Recuperador AMP/API | Obtiene páginas AMP y contenido especial |
Chrome/W.X.Y.Z (con Googlebot) | Bot de renderizado | Este es el grande. Cuando ves un Chrome UA junto a Googlebot, es el Web Rendering Service: Google ejecutando tu JavaScript |
El bot de renderizado es especialmente importante. Cuando Googlebot rastrea por primera vez una página, obtiene el HTML en crudo. Si la página tiene JavaScript, Google pone en cola una segunda solicitud mediante su Web Rendering Service (WRS), que usa un navegador headless Chrome. Esa segunda solicitud aparece en tus logs con una cadena de user agent de Chrome.
Si ves el primer “golpe” de Googlebot, pero nunca el pase de renderizado con Chrome en una página con mucho JS, probablemente Google no está viendo todo tu contenido. Esto es invisible en GSC. Solo el análisis de logs lo revela.
La mayoría de configuraciones por defecto de Nginx y Apache registran datos suficientes para un análisis básico. Pero “básico” no es suficiente. Necesitas el tiempo de respuesta, y la mayoría de defaults no lo incluyen.
Aquí tienes el formato de log de Nginx que uso. Añádelo en tu bloque http dentro de nginx.conf:
log_format seo_analysis '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$request_time $upstream_response_time';
access_log /var/log/nginx/access.log seo_analysis;Las dos incorporaciones que importan: $request_time (tiempo total desde la solicitud hasta la respuesta) y $upstream_response_time (cuánto tardó tu servidor de aplicaciones, excluyendo la sobrecarga de Nginx). La diferencia entre estos dos números te dice si el cuello de botella está en tu aplicación o en tu capa de proxy.
Para Apache, añade %D (tiempo de solicitud en microsegundos) a tu directiva LogFormat:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %D" seo_combined
CustomLog /var/log/apache2/access.log seo_combinedAquí es donde se pone molesto. Si estás detrás de Cloudflare, Bunny CDN, Fastly o cualquier otro CDN, los logs de tu servidor de origen solo muestran las solicitudes que pasan la caché. Una página perfectamente cacheada podría ser rastreada por Googlebot 50 veces, y tu origen no vería ni una de esas solicitudes.
Necesitas logs a nivel CDN:
Si tu CDN no ofrece logging a nivel bots en tu plan, puedes crear una regla para saltarte la caché para user agents de bots conocidos. Así fuerzas a que las solicitudes de bots lleguen a tu origen, donde puedes registrarlas. El intercambio es una carga ligeramente más alta en el origen durante los rastreos.
No estoy del todo seguro de que valga la pena ese intercambio para sitios pequeños. Si recibes 200 solicitudes de Googlebot por día, la carga extra en el origen al saltarte la caché es despreciable. Si recibes 200.000, piensa con cuidado en tu infraestructura antes de activar ese switch.
Los logs se vuelven grandes rápido. Un sitio con 10.000 visitas diarias genera aproximadamente entre 2 y 5 MB de logs de acceso por día. En un año: entre 700 MB y 1.8 GB sin comprimir. Comprimidos con gzip, quizá 50-100 MB.
Para análisis SEO, necesitas como mínimo 90 días de logs. Idealmente 6 meses, para ver patrones de rastreo estacionales y correlacionarlos con actualizaciones del algoritmo. Configura logrotate (Linux) o un job cron para comprimir y archivar logs semanalmente. Elimina cualquier cosa anterior a 6 meses salvo que tengas una razón concreta para conservarla.
Quiero dedicar esto al fallecido Hamlet Batista, que pionereó el uso de Python para análisis de logs SEO y automatización. Hamlet falleció en 2020, pero su trabajo — especialmente su escritura sobre usar Python y notebooks de Jupyter para SEO técnico — cambió de forma fundamental cómo nuestra industria aborda los problemas con datos. Gran parte de lo que sigue se apoya en patrones que él enseñó a la comunidad SEO.
Aquí tienes un script básico en Python que filtra logs de Nginx para solicitudes de Googlebot y genera las métricas que de verdad importan para SEO. Es muy parecido a lo que ejecuté contra los logs propios de SEOJuice.com.
import re
import csv
from collections import Counter, defaultdict
from datetime import datetime
LOG_PATTERN = re.compile(
r'(?P<ip>\S+) \S+ \S+ '
r'\[(?P<timestamp>[^\]]+)\] '
r'"(?P<method>\S+) (?P<url>\S+) \S+" '
r'(?P<status>\d{3}) (?P<size>\d+) '
r'"[^"]*" "(?P<ua>[^"]*)" '
r'(?P<response_time>[\d.]+)?'
)
GOOGLEBOT_PATTERN = re.compile(r'Googlebot|Google-InspectionTool', re.IGNORECASE)
def parse_log(filepath):
"""Parse Nginx log, return only Googlebot requests."""
results = []
with open(filepath, 'r') as f:
for line in f:
match = LOG_PATTERN.match(line)
if not match:
continue
if not GOOGLEBOT_PATTERN.search(match.group('ua')):
continue
results.append({
'ip': match.group('ip'),
'timestamp': match.group('timestamp'),
'url': match.group('url'),
'status': int(match.group('status')),
'size': int(match.group('size')),
'ua': match.group('ua'),
'response_time': float(match.group('response_time') or 0),
})
return results
def analyze(requests):
"""Generate SEO-relevant metrics from Googlebot requests."""
url_counts = Counter(r['url'] for r in requests)
status_counts = Counter(r['status'] for r in requests)
slow_urls = [
(r['url'], r['response_time'])
for r in requests if r['response_time'] > 1.0
]
# Sección: distribución del rastreo
section_counts = Counter()
for r in requests:
parts = r['url'].strip('/').split('/')
section = parts[0] if parts and parts[0] else '(root)'
section_counts[section] += 1
print(f"Total Googlebot requests: {len(requests)}")
print(f"\n--- Status Code Distribution ---")
for code, count in status_counts.most_common():
pct = (count / len(requests)) * 100
print(f" {code}: {count} ({pct:.1f}%)")
print(f"\n--- Top 20 Most Crawled URLs ---")
for url, count in url_counts.most_common(20):
print(f" {count:>5}x {url}")
print(f"\n--- Crawl Distribution by Section ---")
total = len(requests)
for section, count in section_counts.most_common(10):
pct = (count / total) * 100
print(f" /{section}/: {count} ({pct:.1f}%)")
print(f"\n--- Slow Responses (>1s) ---")
for url, time in sorted(slow_urls, key=lambda x: -x[1])[:10]:
print(f" {time:.2f}s {url}")
if __name__ == '__main__':
requests = parse_log('/var/log/nginx/access.log')
analyze(requests)Son quizá 60 líneas de código. Me tomó 20 minutos escribirlo. Y el resultado me mostró de inmediato que Googlebot estaba martillando nuestra sección /tools/ (el 73% de todas las solicitudes de rastreo) mientras tocaba apenas posts nuevos del blog. Ahí estaba el porqué de que nuestro contenido nuevo no se indexara durante semanas.
Para sitios más grandes o monitoreo continuo, necesitas algo más robusto. El stack ELK (Elasticsearch, Logstash, Kibana) es el estándar en la industria para agregación de logs a gran escala. Logstash ingiere y parsea los logs, Elasticsearch los indexa para consultas rápidas y Kibana te da dashboards. Es potente, pero no es trivial de montar: reserva uno o dos días para la configuración inicial.

La sección /tools/ tenía docenas de combinaciones de parámetros (filtros, opciones de orden, paginación) que generaban miles de URLs rastreables. Googlebot las rastreaba todas, como quien va a por todas. Mientras tanto, nuestro blog — la sección que de verdad impulsa el tráfico orgánico — recibía solo el 11% de la atención de rastreo.
El arreglo fue una combinación de etiquetas canónicas, reglas robots.txt y noindex en variantes con parámetros. También reestructuramos el enlazado interno para reflejar mejor nuestros silos de contenido. En dos semanas, la frecuencia de rastreo del blog se duplicó. Los posts nuevos empezaron a indexarse en días en vez de semanas.
No puedes ver esto en GSC. GSC te da el total de solicitudes de rastreo. No lo desglosa por sección ni te muestra el problema de la distribución.
Agrega tus códigos de estado en todas las solicitudes de Googlebot. Así es como se ve una situación saludable:
Una vez vi un sitio donde el 22% de las solicitudes de Googlebot devolvían 404. El desarrollador anterior había eliminado una categoría de producto sin redirigir. Googlebot tenía esas URLs en su cola de rastreo y seguía reintentándolas. Veintidós por ciento del presupuesto de rastreo, quemado en páginas que no existían. Durante ocho meses.
Google ha dicho repetidamente que la velocidad de página es un factor de ranking. Pero Core Web Vitals (que es lo que reporta GSC) mide rendimiento del lado del cliente. El tiempo de respuesta del servidor — cuánto tarda tu servidor en generar y enviar el HTML — es otra cosa, y solo aparece en los logs.
Lo que buscas: cualquier URL donde el tiempo de respuesta supere 500 ms de forma consistente. Por encima de 1 segundo es un problema. Por encima de 2 segundos, Googlebot puede abandonar la solicitud por completo.
Ordena las solicitudes de Googlebot por tiempo de respuesta, de mayor a menor. Las URLs más lentas suelen caer en unas pocas categorías: páginas pesadas en base de datos (listados de productos con filtros complejos), páginas que hacen llamadas a APIs externas durante el renderizado o páginas que generan respuestas grandes (sitemaps, feeds).
¿Cuántos clics desde la home necesita Googlebot para llegar a una página? Esto no está directamente en los datos del log, pero puedes inferirlo revisando marcas de tiempo y patrones de referer.
Si Googlebot llega a tu home a las 09:00, tus páginas de categorías principales a las 09:01 y una página de producto profunda a las 09:14 — esa brecha de 14 minutos sugiere que la página está muy anidada. Las páginas que Googlebot descubre tarde en una sesión reciben menos atención.
Un enfoque más simple: compara el conjunto de URLs que Googlebot rastreó contra tu sitemap completo. Cualquier URL del sitemap que Googlebot no ha visitado en 30+ días, a efectos prácticos, está “huérfana” desde la perspectiva de Google, independientemente de lo que diga tu enlazado interno.
Esto es una métrica de seguridad y rendimiento tanto como de SEO. Filtra tus logs por user agent y calcula qué porcentaje de las solicitudes totales proviene de bots frente a usuarios reales.
En la mayoría de sitios, los bots representan 30-50% de todas las solicitudes. Si los bots son 80%+ , probablemente estés siendo “scrapeado” o recibiendo malos bots que desperdician recursos del servidor. Si Googlebot específicamente representa menos de 5% de tu tráfico de bots, es probable que algo más esté consumiendo tu capacidad de servidor y potencialmente ralentizando la capacidad de Google para rastrearte.
Esto podría ser el análisis más valioso que puedes hacer. Toma la lista de URLs de tu sitemap o de tu CMS. Compárala con la lista de URLs que Googlebot ha visitado en los últimos 90 días. Cualquier URL que Googlebot no toque es, funcionalmente, invisible.
Causas comunes: la página no tiene enlaces internos hacia ella (una página huérfana real), la página está demasiado profunda en la arquitectura del sitio o la página está bloqueada por una regla de robots.txt que se te pasó.
No entiendo de verdad por qué más SEOs no hacen este análisis de forma rutinaria. Son 10 minutos con el script de Python de arriba y una lista de tus URLs. Cada vez que lo he ejecutado para un cliente, hemos encontrado páginas que supuestamente eran importantes pero que no se rastreaban desde hacía meses.
La teoría es bonita. Estos son los problemas reales que he encontrado con análisis de logs en sitios reales y que, de otro modo, habrían pasado desapercibidos.
Ya mencioné nuestra experiencia. Pero vale la pena recalcarlo: la navegación facetada, los parámetros de búsqueda, los órdenes y la paginación generan una cantidad exponencial de URLs rastreables. Un catálogo de productos con 500 productos, 8 categorías de filtro y 3 opciones de orden puede generar decenas de miles de URLs. Googlebot intentará rastrearlas todas.
Según la investigación publicada por Botify sobre presupuesto de rastreo (2023), en sitios grandes de e-commerce, hasta 80% del presupuesto de rastreo de Googlebot puede consumirse en URLs con parámetros que devuelven contenido casi idéntico — aunque la cifra exacta varía bastante según el tipo de sitio y la arquitectura. Su CTO, Adrien Menard, ha escrito extensamente sobre esto: el problema de presupuesto de rastreo en sitios grandes no es lograr que Google rastree más; es evitar que Google desperdicie rastreos en URLs de bajo valor.
Un cliente tenía errores 503 intermitentes que solo aparecían durante “picos” de rastreo de Googlebot. Su monitoreo (Pingdom, UptimeRobot) mostraba 99.9% de disponibilidad porque esas herramientas revisan una vez por minuto desde una única ubicación. Googlebot golpea entre 10 y 50 páginas en rápida sucesión. Su servidor no podía manejar el pico, lanzó 503s en torno al 15% de las solicitudes de Googlebot y se recuperó en cuestión de segundos.
Las estadísticas de rastreo de GSC mostraban una tasa de error ligeramente más alta. Los logs contaban toda la historia: cada día entre las 2:00 y las 3:00 (UTC), cuando Googlebot tiende a golpear ese sitio, el servidor fallaba bajo carga. Arreglarlo requirió ajustar los conteos de workers de PHP-FPM y el pooling de conexiones a la base de datos. Coste total: dos horas de trabajo de DevOps. Las mejoras en ranking aparecieron en tres semanas.
Publicamos una guía detallada. Tres semanas después, seguía sin indexarse. En GSC, la URL figuraba como “Descubierta — actualmente no indexada”. Qué útil.
Los logs contaban la historia real: Googlebot nunca había solicitado esa URL. Ni una vez. La página estaba enlazada desde un archivo/tag de la que a su vez solo se habían hecho dos rastreos en 60 días. Googlebot simplemente aún no había seguido el enlace.
El arreglo fue añadir un enlace interno desde una página frecuentemente rastreada (el sidebar de nuestra home). Googlebot golpeó la página nueva en menos de 48 horas. Indexada en una semana. Este es exactamente el tipo de problema que un checklist SEO posterior al lanzamiento debería detectar antes de que se convierta en un problema.
Un cliente SaaS tenía un sitio de marketing construido en Next.js. SSR estaba habilitado — bien. Pero los logs mostraron algo raro: el bot de renderizado con Chrome de Googlebot hacía un segundo pase en absolutamente todas las páginas, incluso en páginas estáticas sencillas que no tenían contenido dinámico del lado del cliente.
El problema era un script de analítica del lado del cliente que modificaba el DOM después de que la página cargaba. Googlebot veía el HTML inicial, luego regresaba para renderizar JS y detectaba contenido diferente (los elementos inyectados por la analítica). Así que seguía re-renderizando para asegurarse de tener la versión final. Estaba consumiendo presupuesto de renderizado en páginas que no lo necesitaban.
El arreglo: mover el script de analítica para cargarlo después del evento DOMContentLoaded con el atributo defer, y asegurarte de que no modifique elementos visibles del DOM. Las solicitudes de renderizado cayeron 60%.

Botify — Nivel enterprise. Ingiere logs a escala, los correlaciona con datos de rastreo y Search Console, y construye dashboards automáticamente. Si gestionas un sitio con millones de páginas, probablemente valga la inversión. Para sitios con menos de 100k páginas, es exagerado. El precio estaba en el rango de cientos por mes cuando lo miré por última vez (a mediados de 2025), aunque la tarifa exacta no es clara y me deja sentimientos encontrados.
JetOctopus — Un punto intermedio sólido. Análisis de logs en la nube con buena visualización. Maneja archivos grandes, se integra con GSC y cuesta bastante menos que Botify. Se lo he recomendado a agencias que gestionan varios sitios medianos.
Python + ELK a medida — Si eres técnico y quieres control total, el script de arriba es un punto de partida. Para monitoreo continuo, canaliza tus logs hacia el stack ELK (Elasticsearch, Logstash, Kibana). Logstash parsea los logs con patrones grok, Elasticsearch los almacena e indexa y Kibana te da dashboards en tiempo real. La configuración toma un día. El coste continuo es solo el servidor: quizá $20-$50 al mes en un VPS pequeño.
GoAccess — Un analizador ligero de logs basado en terminal que genera reportes HTML. No es específico de SEO, pero es sorprendentemente útil para una visión rápida de la actividad de bots y la distribución de códigos de estado. Gratis, rápido, funciona en cualquier servidor. Ideal para el caso de uso “quiero comprobar algo rápido”.
Momento de transparencia. Esto fue lo que encontré cuando ejecuté por primera vez un análisis serio de logs en nuestro propio sitio a finales de 2025.
Hallazgo 1: desperdicio de presupuesto en páginas de herramientas. Nuestras herramientas SEO gratuitas (auditoría de sitio, checker de autoridad de dominio, extractor de keywords, etc.) generan URLs únicas por cada análisis. Cada resultado de herramienta tenía su propia URL. Googlebot las rastreaba en miles. Eran, en su mayoría, páginas superficiales y efímeras que no necesitaban estar en el índice. Añadimos noindex a las páginas de resultados de las herramientas y vimos aumentar la tasa de rastreo del blog en dos semanas.
Hallazgo 2: páginas lentas que dependen de una API. Nuestra página de precios hacía una llamada en tiempo real a la API de Paddle para traer precios actuales. Tiempo de respuesta mediano: 1.8 segundos. Googlebot estaba esperando eso. Cambiamos a cachear los datos de precios con un TTL de 1 hora. El tiempo de respuesta bajó a 90 ms.
Hallazgo 3: cadenas de redirección 301. Después de una reestructuración de URLs, teníamos cadenas como /old-url → /medium-url → /final-url. El 12% de las solicitudes de Googlebot seguían redirecciones. Cada salto es una solicitud desperdiciada. Simplificamos todas las cadenas a redirecciones de un solo salto en nuestra configuración de Nginx.
Hallazgo 4: rastreo de CSS y JS. Esto me sorprendió. Aproximadamente el 30% de las solicitudes de Googlebot eran para assets estáticos: archivos CSS, bundles de JavaScript y fuentes. Son necesarios para renderizar, pero significaba que solo el 70% de nuestro presupuesto de rastreo iba a páginas de contenido reales. No podíamos eliminarlo (Google necesita esos archivos para renderizar), pero cambió cómo pensamos sobre nuestro presupuesto total de rastreo.
Resultado neto: tras abordar los hallazgos 1-3, el contenido del blog se indexaba 3-4 veces más rápido. Los posts nuevos pasaron de “descubiertos pero no indexados en 2-3 semanas” a “indexados en 3-5 días”. Todo gracias a insights del análisis de logs que GSC nunca mostró.
Construí la función de analítica del crawler en SEOJuice específicamente porque estaba cansado de parsear logs en crudo. Te ofrece los mismos insights sin el trabajo de línea de comandos.
La analítica del crawler de SEOJuice monitorea la actividad de Googlebot en tu sitio y te muestra:
No reemplaza el análisis de logs en crudo para cada caso de uso. Si necesitas depurar una configuración específica de Nginx o investigar el comportamiento de bots a nivel IP, sigues necesitando los logs en crudo. Pero para el 90% de los casos en los que solo quieres saber “¿Googlebot está rastreando lo correcto?” — es muchísimo más rápido que escribir scripts en Python.
Prueba SEOJuice gratis y conecta tu sitio para ver la analítica del crawler en acción. No hace falta tarjeta de crédito.
No necesitas mirar los logs todos los días. Este es el routine mensual que sigo:
Tiempo total: 30-45 minutos. El ROI es desproporcionado.
No lo he probado de forma exhaustiva en cada nicho, pero no hay un mínimo duro: el beneficio escala con el tamaño del sitio. Con menos de 100 páginas, Googlebot rastreará todo sin importar, y es poco probable que tengas problemas de presupuesto de rastreo. Entre 500 y 5,000 páginas es donde empieza a volverse valioso. Por encima de 10,000 páginas, es esencial: el desperdicio de presupuesto de rastreo casi está garantizado en sitios de ese tamaño. Dicho esto, incluso un sitio de 200 páginas puede beneficiarse si estás viendo retrasos de indexación o caídas de ranking misteriosas.
Sí. Google publica sus rangos IP y puedes hacer una consulta inversa de DNS (reverse DNS) en la IP que solicita. Las IP legítimas de Googlebot resuelven a *.googlebot.com o *.google.com. En Python: import socket; socket.gethostbyaddr('66.249.79.45'). Cualquier IP que no resuelva a un dominio de Google es un Googlebot falso, probablemente un scraper usando la cadena de user agent de Googlebot. La documentación oficial de Google recomienda este método de verificación.
Varía enormemente. Un sitio de noticias con alta autoridad puede ver miles de solicitudes de Googlebot por hora. Un sitio pequeño de negocio puede ver entre 50 y 200 al día. La frecuencia depende de la importancia percibida de tu sitio, de cuánto cambia tu contenido, de la velocidad de respuesta de tu servidor y de la frescura de tu sitemap XML. Según un análisis de frecuencia de rastreo de JetOctopus en 2024 sobre su base de clientes, la frecuencia mediana de rastreo para un sitio de 5,000 páginas es de aproximadamente 300-800 solicitudes de Googlebot por día.
Bloquea malos bots a nivel servidor (reglas Nginx deny o fail2ban), no solo en robots.txt. robots.txt es una sugerencia: los bots maliciosos lo ignoran. Pero ojo: no bloquees accidentalmente rastreadores legítimos. He visto sitios que bloquearon todos los bots que contenían “bot” en la cadena user agent y eso incluía a Googlebot. Antes de aplicar reglas amplias de bloqueo, crea una lista blanca (whitelist) para Google, Bing y cualquier otro motor de búsqueda que te interese.
El análisis de logs es cómo mides el presupuesto de rastreo. Google define el presupuesto de rastreo como la combinación del límite de tasa de rastreo (qué tan rápido puede rastrear Google sin saturar tu servidor) y la demanda de rastreo (cuánto quiere rastrear Google según el valor percibido). No puedes controlar directamente ninguno de los dos, pero sí puedes influir: tiempos de respuesta más rápidos aumentan el límite de tasa de rastreo, y eliminar páginas de bajo valor de la cola de rastreo de Google aumenta la proporción del presupuesto dedicada a páginas que importan. Los logs te muestran ambos lados de esta ecuación.
El análisis de logs no es glamuroso. Es grep y regex, y pasar archivos de texto por scripts. No hay dashboards bonitos (a menos que los construyas). Pero es lo más cerca que tendrás de ver tu sitio a través de los ojos de Google. GSC te da un resumen curado. Los logs muestran la verdad en crudo.
Si estás gestionando un sitio con más de un par de cientos de páginas y nunca has mirado tus logs del servidor, tienes problemas de rastreo que ni siquiera sabes que existen. Apuesto dinero a que sí.
Lecturas adicionales en el silo de SEO Técnico:
no credit card required
No related articles found.
